


TransUNet — Revolutionize Traditional Image Segmentation
Last Updated on July 25, 2023 by Editorial Team
Author(s): Leo Wang
Originally published on Towards AI.
Renovating U-Net by combining CNNs and Transformer to achieve SOTA results on image segmentation tasks.
Table of Contents
· U+1F525 Intuition
· U+1F525 TransUNet
∘ Down-Sampling (Encoding)
∘ Up-Sampling (Decoding)
· U+1F525 Results
· U+1F525 Implementations
· Reference
U+1F525 Intuition
Nowadays, U-Net has dominated image segmentation tasks, especially in the field of medical imaging. Among most of the hitherto proposed U-Nets, Convolution Neural Networks (CNN) are widely used as their underlying structures.
However, CNN's can only exploit short-range (or local) information effectively due to their small convolutional kernel sizes, failing to explore long-range information sufficiently in tasks that have features with long-range relations.
Transformers, commonly used to handle Natural Language Processing tasks, can explore long-range information effectively, but they are not robust in exploiting short-range information as CNNs do.
To use the power of CNNs can compensate for the shortcomings of Transformers and vice versa in image segmentation tasks, Chen et al. proposed TransUNet, which is also the first image segmentation model built from Transformer. It’s also worth mentioning that the authors verified the promising outcome of combining CNNs and Transformers by firstly attempting to use pure Transformer architecture for image segmentation. However, it did not work as well as introducing CNNs in their architecture because transformers are not as good as CNNs in exploiting local features.
U+1F525 TransUNet
We know that in U-Net (Fig. 1) there is an encoder (the down-sampling path) and a decoder (the up-sampling path). The down-sampling path will encode the image’s features to a high-level map, and its details will be used by the up-sampling path to produce the final mask of the same dimension as the input.

Similarly, TransUNet also comprises an encoder and a decoder for encoding and decoding image information to produce a segmentation. Different from traditional U-Nets, TransUNet instead uses a hybrid CNN-Transformer architecture as an encoder to learn both the high-resolution spatial information from CNNs and global context information from Transformers.

To break down the steps:
Down-Sampling (Encoding)
- Firstly, CNN is used as a feature extractor to generate a feature map for the input, as shown in the pink box in Fig. 2.
- For each level of the feature extractor, the output feature map (that encodes for intermediate high-level feature maps) is then concatenated to the decoder path of the same level, as shown by the dotted arrows in Fig. 2.
- Then, the feature map is tokenized (vectorized) into a 2D embedding of shape (n_patch, D) by linear projection, and D is the total length of the embedding. The embeddings were pre-trained and will retain the positional information of the feature map (if you don’t understand how don’t worry about it for now, as it won’t hinder your comprehension of TransUNet too much).
- After obtaining the embeddings, they are fed into 12 Transformer layers to encode less short-range and more long-range information from the image. Each layer is illustrated in Fig. 2 (a), which uses multi-head self-attention (MSA) and multi-layer perceptron (MLP) modules. MSA is the basic building block for transformers and is explained here, and MLP is just comprised of several fully connected layers.
- Lastly, to prepare for the up-sampling path, the output is reshaped to (D, H/16, W/16). H/16 and W/16 mean that the heights and widths by this time have been shrunk by 16 times because of the previous operations.
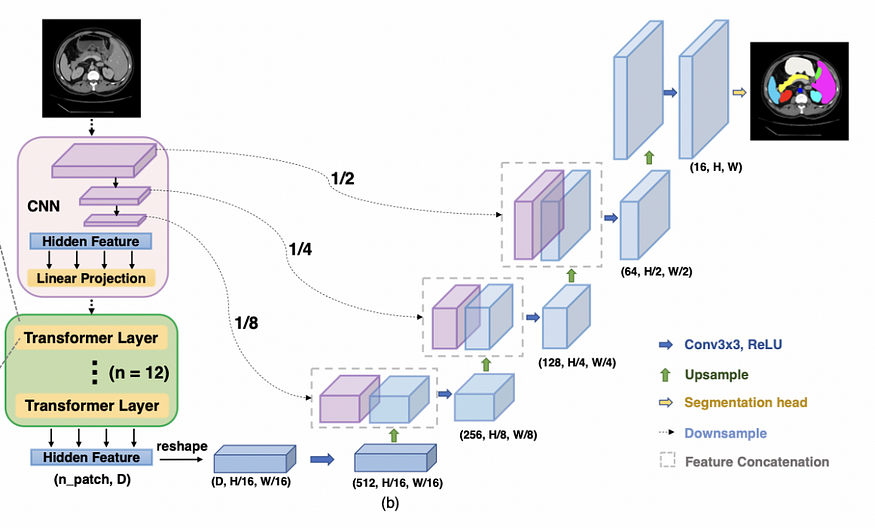
Up-Sampling (Decoding)
The up-sampling process is pretty straightforward (without any fancy techniques).
- Firstly, the input from the CNN-Transformer encoder is run by a 3×3 convolution layer with ReLU activation, upsampled, and then concatenated with the output of the third-level CNN feature extractor.
- The resultant feature maps are then run through the 3×3 convolution with the ReLU activation layer again. The output is then concatenated with the output from the second-level CNN feature extractor.
- The step is repeated again. Now, the output is a mask in shape (C, H, W), with C=number of objective classes, H=image height, and W=image width.
The authors also noted that more intensive incorporation of low-level features generally leads to better segmentation accuracy.
U+1F525 Results
The model is run on the Synapse Multi-Organ Segmentation dataset. The final scores are evaluated by the Dice Similarity Coefficient and Hausdorff distance.
As you can see, TransUNet performed better than most of the existing SOTA architectures, such as V-Net, ResNet U-Net, ResNet Attention U-Net, and Vision Transformers, which suggests that the Transformer-based architecture is better at leveraging self-attention than other self-attention based CNN U-Nets.

U+1F525 Implementations
Official TransUNet Implementation
Thank you! U+2764️
May we plead with you to consider giving us some applause! U+2764️
Reference
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

