



Topic Modeling on Customer Reviews using BERTopic and Llama2
Author(s): Boris Dorian Da Silva
Originally published on Towards AI.
Topic Modeling on Customer Reviews using BERTopic and Llama2
A Quick Guide to Creating Interpretable Topics from Customer Reviews with BERTopic and Llama2 using Ollama.
Introduction
No matter the industry, most companies utilize customer reviews to gather crucial insights about their products/services.
Topic modeling is a technique that facilitates the discovery of main themes and topics within a vast collection of text documents. This method aids in comprehending customer sentiments, preferences, and challenges.
Customer reviews typically consist of two main components: an overall score for the product/service and a descriptive comment. These scores may come in various formats, such as “1 to 10,” “1 to 5,” “Negative/Neutral/Positive,” etc. However, for ease of analysis, it is advisable to standardize them into three categories: Negative, Positive, and Neutral. For instance, in a “1 to 5” score format, the standardization could be defined as follows:
- Negative: 1 or 2
- Neutral: 3
- Positive: 4 or 5
Once the reviews scores are standardized, the goal is to address two main questions:
- What are people talking about in the negative reviews?
- What are people talking about in the positive reviews?
In this article, I present a guide for constructing a quick and straightforward topic model using the powerful BERTopic library to extract topics from documents and leveraging the Large Language Model “Llama2” to improve the topic representations. This guide serves as an effective strategy for gaining initial insights from the reviews.
BERTopic
According to the official documentation, BERTopic “is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions”.
BERTopic employs a sequence of five steps to generate topic representations:

For further details, I recommend referring to the official website and the original paper by Maarten Grootendorst.
Dataset
In this article, I use a publicly available dataset from Kaggle comprising over 33,000 anonymized reviews of McDonald’s stores in the United States, sourced from Google reviews.
You can access the dataset at: https://www.kaggle.com/datasets/nelgiriyewithana/mcdonalds-store-reviews/data
Below, you can see the contents of the dataset:
import pandas as pd
df = pd.read_csv('McDonald_s_Reviews.csv', encoding='latin1')
df.head()
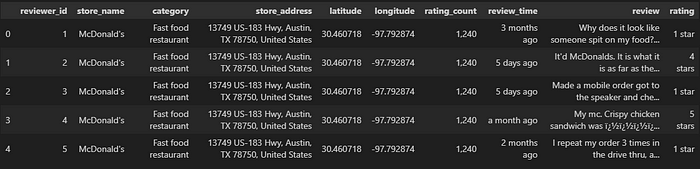
We will divide our dataset into 2 dataframes for the negative reviews and the positive ones, based on the standardization described above.
df_neg = df[df['rating'].isin(['1 star', '2 stars'])]
df_pos = df[df['rating'].isin(['4 stars', '5 stars'])]
print('Quantity of negative reviews: ', len(df_neg))
print('Quantity of positive reviews: ', len(df_pos))

Topic Model Training
Once we have the reviews from the dataset, we will implement a simple configuration for BERTopic to train two topic models: one for negative reviews and another for positive reviews.
The particularity of this configuration lies in our utilization of KeyBERTInspired to perform an initial stage of representation fine-tuning. The outcome of this process is a list of keywords for each topic that represent the topic.
We will apply the same configuration to both the positive and negative reviews.
from bertopic import BERTopic
from bertopic.representation import KeyBERTInspired
from sklearn.feature_extraction.text import CountVectorizer
representation_model = KeyBERTInspired()
#vectorizer_model = CountVectorizer(min_df=5, stop_words = 'english')
topic_model_neg = BERTopic(#nr_topics = 'auto',
#vectorizer_model = vectorizer_model,
representation_model = representation_model)
topic_model_pos = BERTopic(#nr_topics = 'auto',
#vectorizer_model = vectorizer_model,
representation_model = representation_model)
print('Training topic model for negative reviews...')
topics_neg, ini_probs_neg = topic_model_neg.fit_transform(list(df_neg.review.values))
print('Training topic model for positive reviews...')
topics_pos, ini_probs_pos = topic_model_pos.fit_transform(list(df_pos.review.values))
df_neg['topic'] = topics_neg
df_neg['topic_prob'] = ini_probs_neg
df_pos['topic'] = topics_pos
df_pos['topic_prob'] = ini_probs_pos
topics_info_neg = topic_model_neg.get_topic_info()
topics_info_pos = topic_model_pos.get_topic_info()
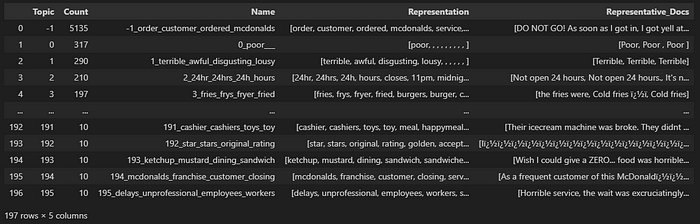
After training the topic model, we obtained 195 topics for negative reviews and 317 topics for positive reviews. To view the topics, you can execute the following lines of code:
# Topics information from Negative Reviews
topic_model_neg.get_topic_info()
# Topics information from Positive Reviews
topic_model_pos.get_topic_info()
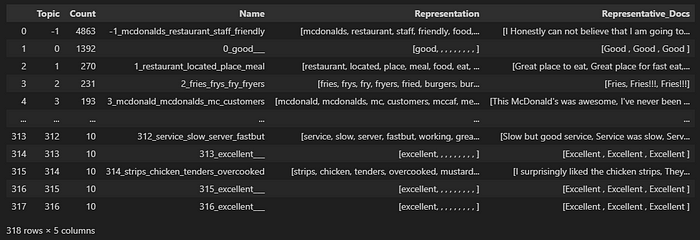
As you can observe, the largest group is denoted by the topic “-1,” which corresponds to outlier reviews. Essentially, the resulting model couldn’t allocate a topic to these reviews. If you wish to mitigate the number of outliers, I suggest referring to the official documentation to explore new configurations for the model.
In the following section, you can visualize a graph displaying the scores of the words for the first 8 topics.
# Topic Word Scores from Negative Reviews
topic_model_neg.visualize_barchart()

# Topic Word Scores from Positive Reviews
topic_model_pos.visualize_barchart()

2° Stage of Fine-Tuning Representation using LLM
The “Representation” column from the dataframe with the topics information (obtained in the previous section) includes a list of keywords that represent each topic, obtained through the KeyBERTInspired algorithm. While this representation can provide insights into the meaning of each topic, fully understanding and interpreting these keywords in the context of the topic may require considerable analysis. To expedite this process, we propose conducting a second stage of representation fine-tuning using a Large Language Model (LLM), specifically Llama2 in this case. The concept behind this approach is for the LLM model to generate concise labels representing each topic based on samples of reviews associated with the topic and their corresponding keywords obtained from KeyBERTInspired.
Ollama and Llama2
To run the Llama2 model, we will use Ollama, that is a streamlined tool that allows users to easily set up and run large language models locally. You can download the installer from the following link:
Once installed, you will need to download the model from the terminal using the following command line:
ollama pull llama2
Llama2 is released by Meta Platforms, Inc. This model is trained on 2 trillion tokens, and by default supports a context length of 4096. Llama 2 Chat models are fine-tuned on over 1 million human annotations, and are made for chat. By default, Ollama uses 4-bit quantization for this model.
Prompt Engineering
The next step involves building a custom prompt to send to the LLM model. The Llama2-chat model uses the following template to define system and instruction prompts:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]
Below, you can find the breakdown of each component within the template:
<s>: the beginning of the entire sequence.
[INST]: the beginning of some instructions.
<<SYS>>: the beginning of the system message.
{{ system_prompt }}: Where the user should edit the system prompt to give overall context to model responses.
<</SYS>>: the end of the system message.
{{ user_message }}: Where the user should provide instructions to the model for generating outputs.
[/INST]: the end of some instructions.
To build our prompt, we will employ the strategy outlined in the BERTopic documentation, which consists of three components:
- system_prompt: This component aids in guiding the model during a conversation. For instance, we can say that it is a helpful assistant that specializes in labeling topics.
- example_prompt: This provides an example of a correctly labeled topic to guide the LLM model.
- main_prompt: This contains the main question we are going to ask to the model, which is to label a topic. We will insert a sample of customer reviews and the keywords associated with the topic to provide the most relevant documents and keywords as additional context.
In the following part we will define the system_prompt:
system_prompt = """
<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant for labeling topics.
<</SYS>>
"""
To construct the “example_prompt,” we need to follow these steps:
- Obtain a sample topic from the topic model.
- Retrieve a number of reviews with the highest probability of belonging to that topic.
- Extract the keyword representations from the topic.
- Analyze this information and manually define a concise label.
The following code executes steps 1, 2, and 3. The output of this section is used to analyze the information and manually define the concise label (step 4).
topic_number = 3
print( 'Reviews: \n' ,'\n'.join([str(elem) for elem in \
df_neg[df_neg['topic']==topic_number]\
.sort_values('topic_prob', ascending=False)\
.drop_duplicates(subset=['review'])['review']\
.head(4).values])
)
print( '\nKey words: ' ,', '.join([str(elem) for elem in \
topics_info_neg.loc[topics_info_neg['Topic']==topic_number, 'Representation'].values[0]]))

In this particular case, I used a topic from negative reviews, but you can choose any topic, whether negative or positive. Based on the previous example, I can define a potential output (short label) as “bad food”.
With this information, I can construct the “example_prompt” as follows:
# Example prompt
example_prompt = """
I have a topic that contains the following documents (from customers reviews):
- Not good. Fries were stale.
- There burgers has gotten worse than ever but their fries are still good.
- Fries were too salty.
The topic is described by the following keywords: 'fries, fry, burger, burgers, fried, cold, frozen, cooked, greasy, warm'.
Based on the information about the topic above, please create a short label of this topic. Make sure you to only return the label and nothing more.
[/INST] bad food
"""
base_prompt = system_prompt + example_prompt
Running the LLM model
The following code iterates over each topic and extracts a list of unique sample reviews with the highest probability of belonging to that topic. In this particular case, it will extract 10 sample reviews. Additionally, it extracts the keywords that represent the topic. Using the list of reviews and topic keywords, it integrates them into the main_prompt to ultimately construct the prompt for running the LLM model. Consequently, we obtain a short label that represents the topic. This process is executed iteratively for all topics.
import ollama
# Quantity of reviews
qty_comments_prompt = 10
def get_short_labels(df, topics_info, qty_comments_prompt, base_prompt):
for topic in topics_info.loc[topics_info['Topic'] > -1, 'Topic']:
print(topic)
# X reviews with the higher probability. It doesn't consider the duplicated values
comments_list = '\n- '.join([str(elem) for elem in \
df[df['topic']==topic].sort_values('topic_prob', ascending=False)\
.drop_duplicates(subset=['review'])['review']\
.head(qty_comments_prompt).values])
# Key words list from topic
key_list = ', '.join([str(elem) for elem in topics_info.loc[topics_info['Topic']==topic, 'Representation'].values[0]])
# The main prompt with the list of reviews and list of topic key words
main_prompt = f"""
[INST]
I have a topic that contains the following documents (from customers reviews):
{comments_list}
The topic is described by the following keywords: '{key_list}'.
Based on the information about the topic above, please create a short label of this topic. Make sure you to only return the label and nothing more.
[/INST]
"""
# Build input prompt
prompt = base_prompt + main_prompt
output = ollama.generate(model='llama2', prompt=prompt)
topics_info.loc[topics_info['Topic']==topic, 'short_label'] = output['response']
print('Output: ', output['response'])
return topics_info
# Training topic model with Negative customer reviews
topics_info_neg_output = get_short_labels(df_neg, topics_info_neg, qty_comments_prompt, base_prompt)
topics_info_neg_output.to_excel('topics_info_neg.xlsx', index=False)
# Training topic model with Positive customer reviews
topics_info_pos_output = get_short_labels(df_pos, topics_info_pos, qty_comments_prompt, base_prompt)
topics_info_pos_output.to_excel('topics_info_pos.xlsx', index=False)
Results
As a result of this process, you will have two Excel files containing the topics: one for negative reviews and another for positive reviews. These files include a column titled “short_label” representing the meaning of each topic calculated in the preceding section. The structure of each file is illustrated below:
# Topics information from Negative Reviews
topics_info_neg_output.head()

# Topics information from Positive Reviews
topics_info_pos_output.head()

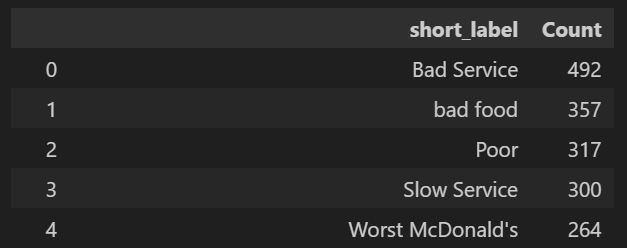
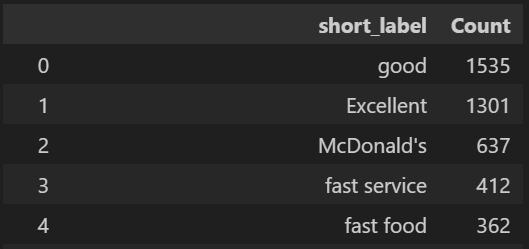
As some values of “short_label” are repeated, in the next section we group them and order them by the quantity of reviews (in the “Count” column). In this grouping we don not considers the outliers reviews (without a topic assigned by the model). Consequently, we obtain 147 topics for negative reviews and 173 for positive reviews.
topics_info_neg_output_grouped = topics_info_neg_output.groupby('short_label')['Count'].sum().reset_index()
topics_info_neg_output_grouped = topics_info_neg_output_grouped.sort_values(by=['Count'], ascending=False).reset_index(drop=True)
topics_info_pos_output_grouped = topics_info_pos_output.groupby('short_label')['Count'].sum().reset_index()
topics_info_pos_output_grouped = topics_info_pos_output_grouped.sort_values(by=['Count'], ascending=False).reset_index(drop=True)
# Negative topics
topics_info_neg_output_grouped.head()
# Positive topics
topics_info_pos_output_grouped.head()
Conclusion
In conclusion, the process of topic modeling using BERTopic and Llama2 offers a robust methodology for extracting meaningful insights from customer reviews. By standardizing review scores and leveraging advanced NLP techniques, this methodology efficiently analyzes large volumes of text data to understand customer sentiments, preferences, and concerns. The integration of BERTopic and Llama2 facilitates the creation of interpretable topics, providing actionable insights to improve products and services.
Moreover, through careful construction of prompts resulting in better output of the LLM model, providing concise representations of each topic, aids in the interpretation and analysis of the extracted insights. Overall, this approach enables quick analysis and actionable intelligence from customer reviews, driving informed decision-making to enhance customer satisfaction.
Sources
https://maartengr.github.io/BERTopic/index.html
https://arxiv.org/abs/2203.05794
https://developer.ibm.com/tutorials/awb-prompt-engineering-llama-2/
https://www.kaggle.com/datasets/nelgiriyewithana/mcdonalds-store-reviews/data
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

