


![Time Series Forecasting with ARIMA Models In Python [Part 2]](https://cdn-images-1.medium.com/max/700/1*Xs77Hz06NDZk-N-iyvUMFA.jpeg "Time Series Forecasting with ARIMA Models In Python [Part 2]")
Time Series Forecasting with ARIMA Models In Python [Part 2]
Last Updated on January 6, 2023 by Editorial Team
Last Updated on May 12, 2022 by Editorial Team
Author(s): Youssef Hosni
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A practical guide for time series forecasting using ARIMA models in Python
Time series data is one of the most common data types in the industry and you will probably be working with it in your career. Therefore understanding how to work with it and how to apply analytical and forecasting techniques are critical for every aspiring data scientist. In this series of articles, I will go through the basic techniques to work with time-series data, starting from data manipulation, analysis, and visualization to understand your data and prepare it for and then using the statistical, machine, and deep learning techniques for forecasting and classification. It will be more of a practical guide in which I will be applying each discussed and explained concept to real data.
This series will consist of 9 articles:
- Manipulating Time Series Data In Python Pandas [A Practical Guide]
- Time Series Analysis in Python Pandas [A Practical Guide]
- Visualizing Time Series Data in Python [A practical Guide]
- Time Series Forecasting with ARIMA Models In Python [Part 1]
- Time Series Forecasting with ARIMA Models In Python [Part 2] (You are here!)
- Machine Learning for Time Series Data [A practical Guide]
- Deep Learning for Time Series Data [A practical Guide]
- Time Series Forecasting project using statistical analysis, machine learning & deep learning.
- Time Series Classification using statistical analysis, machine learning & deep learning.
This article is the second part of time series forecasting using ARIMA models. In the first part, the ARIMA model was introduced and how to use to forecast the future. In this article, I will focus more on choosing the best model parameter and how to build a pipeline for the process of forecasting through the Box-Jenkins method.
Table of contents:
1. Finding the Best ARIMA Models
- Using ACF and PACF to find the best model parameters
- Using AIC and BIC to narrow your model choices
- The model diagnostic a
- The Box-Jenkins method
2. Seasonal ARIMA Models
- Introduction to seasonal time series
- Seasonal ARIMA model
- Process automation and model saving
- SARIMA and Box-Jenkins for seasonal time series
3. References
The codes and the data used in this article can be found in this GitHub repository.
1. Finding the Best ARIMA Models
In this section, we will learn how to identify promising model orders from the data itself, then, once the most promising models have been trained, you’ll learn how to choose the best model from this fitted selection. You’ll also learn how to structure your time series project using the Box-Jenkins method.
1.1. Using ACF and PACF to find the best model parameters
In the previous section, we knew how to use the ARIMA model for forecasting, however, we did not discuss how to choose the order of the forecasting model. The model order is a very important parameter that affects the quality of the forecasts. One of the best ways to identify the correct model order is the autocorrelation function (ACF) and partial autocorrelation function (PACF).
The ACF can be defined as the correlation between a time series and itself with n lags. So ACF(1) is the correlation between the time series and a one-step lagged version of itself. An ACF(2) is the correlation between the time series and a one-step lagged version of itself and so on. To have a better understanding of the ACF, let’s plot it for the earthquake time series for ten lags.
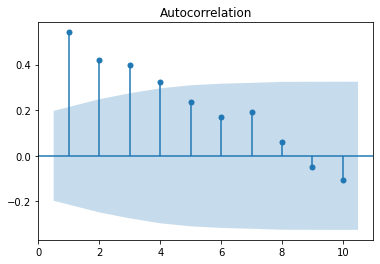
The bars in the figure above show the correlation of the time series with itself at each lag. If the bar is inside the blue shaded region, this means that it is not statistically significant.
On the other hand, the PACF is the correlation between a time series and a lagged version of itself after subtracting the effect of correlation at smaller lags. So it can be considered as the correlation at a particular lag. To have a better understanding of the PACF, let’s plot it for the earthquake time series for ten lags.
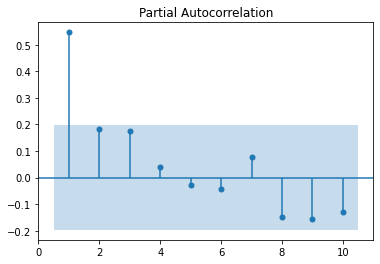
The bars in the figure above show the correlation of the time series with itself at each lag after subtracting the effect of the correlation of the smaller lags. If the bar is inside the blue shaded region, this means that it is not statistically significant.
The time series must be made stationary before making these plots. If the ACF values are high and tail off very very slowly, therefore this is a sign that the data is non-stationarity, and it needs to be different. On the other hand, if the autocorrelation at lag-1 is very negative this is a sign that we have taken the difference too many times.
By comparing the ACF and PACF for a time series, we can indicate the model order. There are three main possibilities:
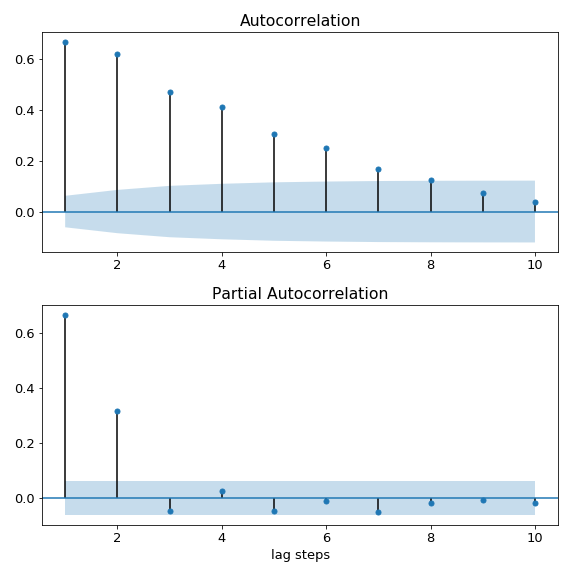
- AR(p) model: ACF tails off and PACF cuts off after lag p. The figure below shows the ACF and PACF plots for an AR(2).
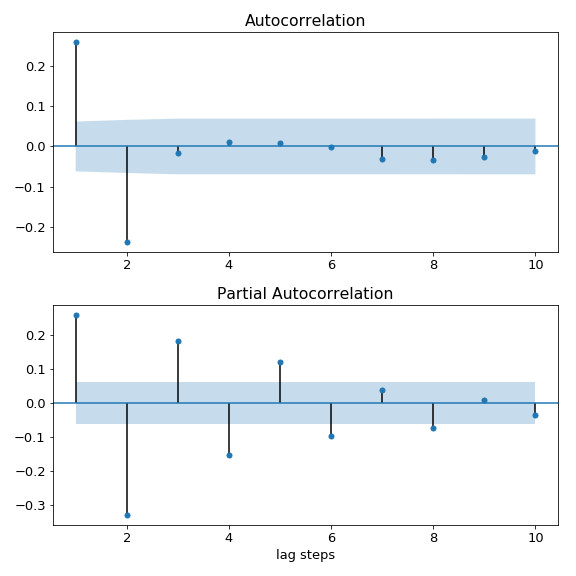
- MA(q) model: The amplitude of the ACF cuts off after lag q, while the PACF tails off. The figure below shows the ACF and PACF plots for an MA(2).
- ARIMA(p,q) model: if the amplitude of both the ACF and PACF cuts off, then this will be the ARIMA model, however, we will not be able to deduce the model orders (p,q) from the plot.
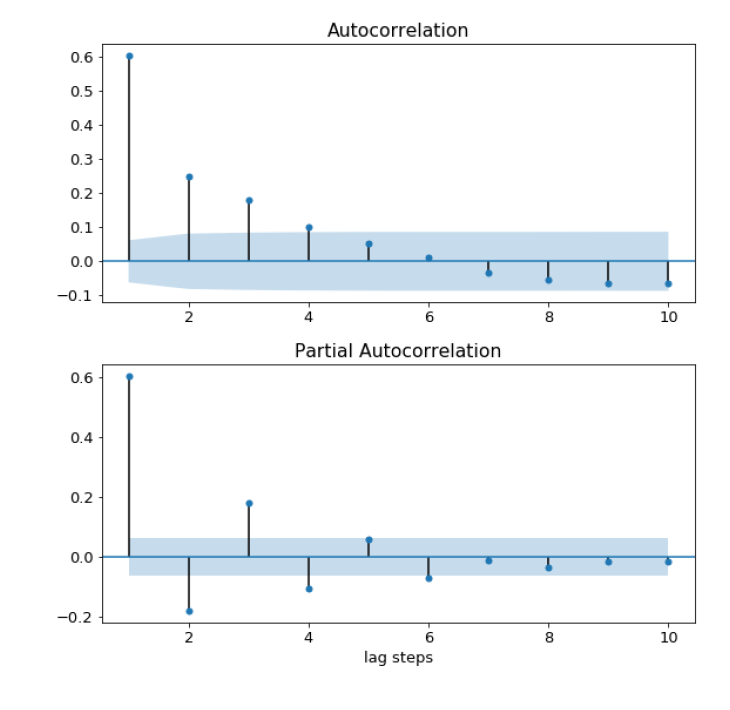
Let’s apply this to the earthquake time series, that we plotted the ACF and PACF before. It looks like the ACF tails off while the PACF cuts off at a lag of 1. Therefore it follows the first case, and the time series can be modeled using an AR(1) model.
1.2. Using AIC and BIC to narrow your model choices
We mentioned in the third case when the amplitude of both the ACF and PACF cuts off, the time series can be modeled using an ARIMA(p,q) model. However, the order of the model (p,q) can be indicated from the ACF and PACF plot. However, the Akaike information criterion (AIC) and Bayesian information criterion (BIC) can be used for finding their values.
For both AIC and BIC lower values suggest a better model. Both AIC and BIC penalize complex models with a lot of parameters. However, they differ in the way they do so and how much they penalize the model complexity. The BIC penalizes additional model orders more than AIC and therefore BIC will sometime suggest a simpler model than AIC. They often will suggest the same model, but if not, you will have to choose one of them depending on your priorities. If your goal is to identify a better predictive model then AIC will be a better choice, and if your goal is to identify a good explanatory model, then BIC will be a good choice.
Let’s apply this to the earthquake dataset used before and compare the results with the results we got from using ACF/PACF. We predict that the best model to fit the data is AR(1). We will calculate the AIC and BIC for different variations of p and q starting from 0 to 2.
The sorted AIC and BIC are shown below for each model
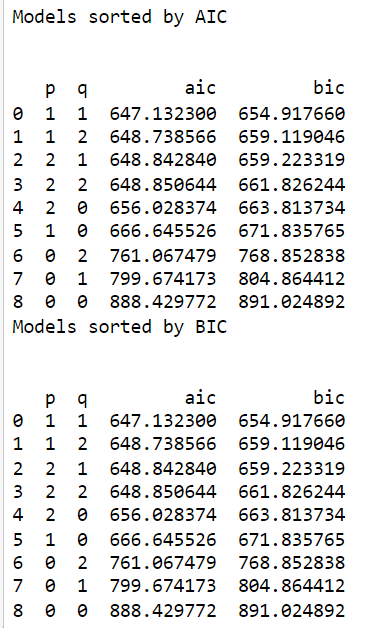
The results show that the best model to fit the data is (1,1), which is different from what was found using the PACF/ACF.
3.3. The model diagnostic
The next step is to diagnose the model to know whether the model is behaving well or not. To diagnose the model we will focus on the residuals of the training data. The residuals are the difference between the model’s one-step-ahead predictions and the real values of the time series.
In statsmodels, the residuals over the training period can be accessed using the dot-resid attribute of the results object. The results are stored as a pandas series. This is shown in the code below:
To know how far the predictions are from the true value, we can calculate the mean absolute error of the residuals. This is shown in the code below:
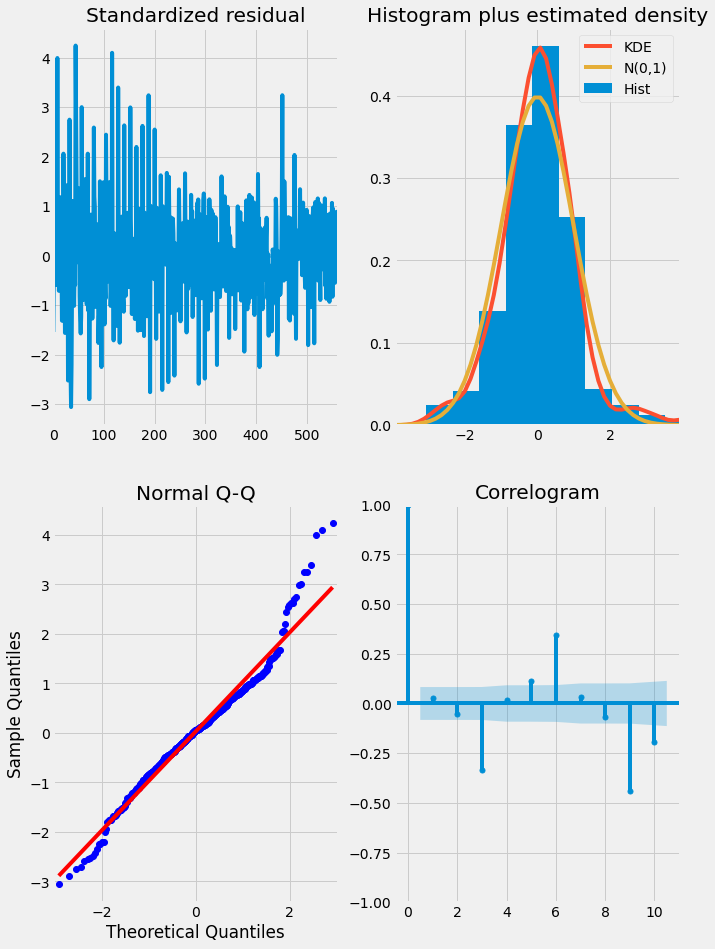
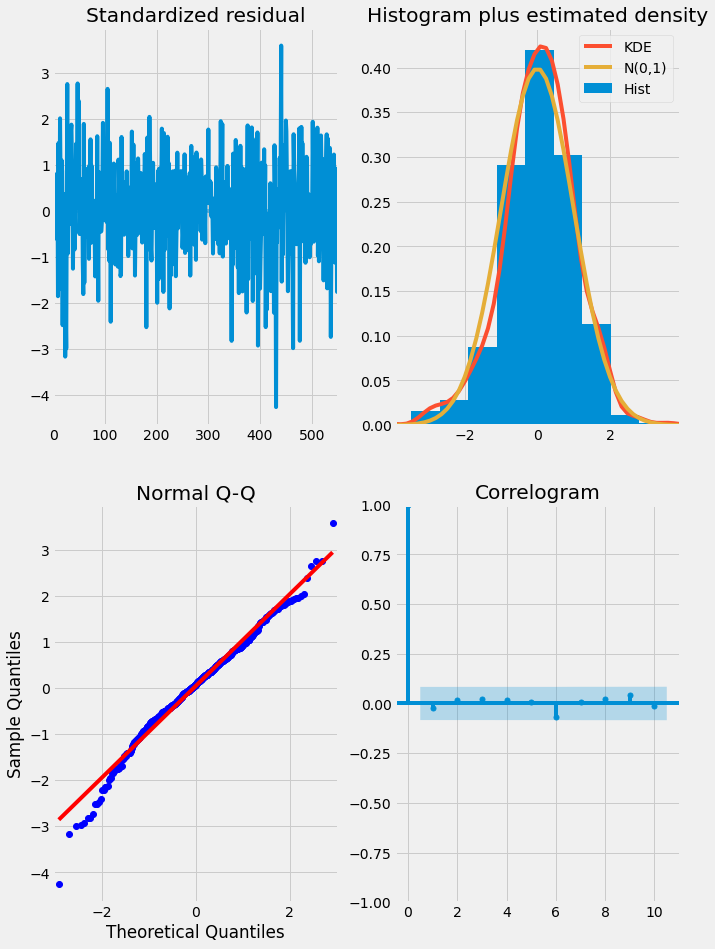
The ideal model should have residuals that are uncorrelated white Gaussian noise centered on zero. We can use the results object’s .plot_diagnostics method to generate four common plots for evaluating this. The code for this is shown below:
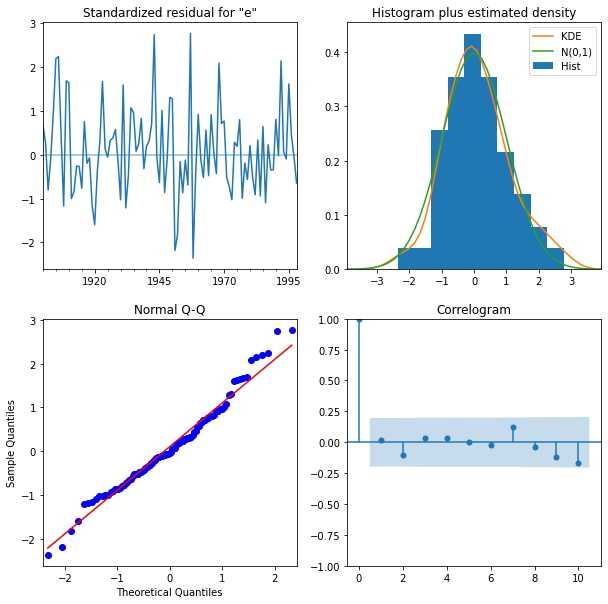
There are four plots in the residuals diagnostic plots:
- Standardized residuals plot: The top left plot shows one-step-ahead standardized residuals. If our model is working correctly, there should be no obvious pattern in the residuals. This is shown here in this case.
- Histogram plus estimated density plot: This plot shows the distribution of the residuals. The histogram shows us the measured distribution; the orange line shows a smoothed version of this histogram, and the green line shows a normal distribution. If the model is good these two lines should be the same. Here there are small differences between them, which indicate that our model is doing well.
- Normal Q-Q plot: The Q-Q plot compare the distribution of the residuals to the normal distribution. If the distribution of the residuals is normal, then all the points should lie along the red line, except for some values at the end.
- Correlogram plot: The correlogram plot is the ACF plot of the residuals rather than the data. 95% of the correlations for lag greater than zero should not be significant (within the blue shades). If there is a significant correlation in the residuals, it means that there is information in the data that was not captured by the model.
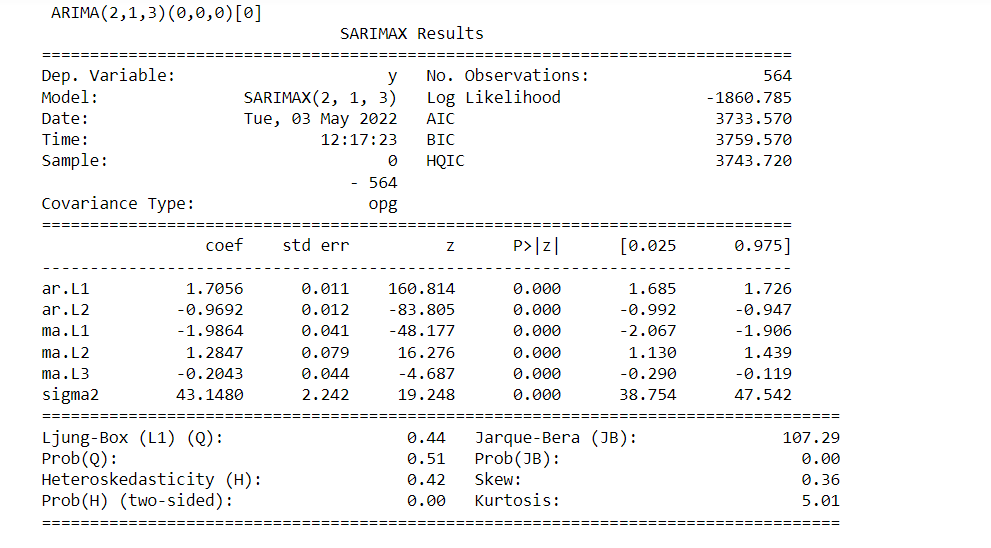
We can get the summary statistics of the model residuals using the results .summary method. In the result table shown below, the Prob(Q) is the p-value associated with the null hypothesis that the residuals have no correlation structure. Prob(JB) is the p-value associated with the null hypothesis that the residuals are Gaussian normally distributed. If either of the p-values is less than 0.05 we reject that hypothesis.
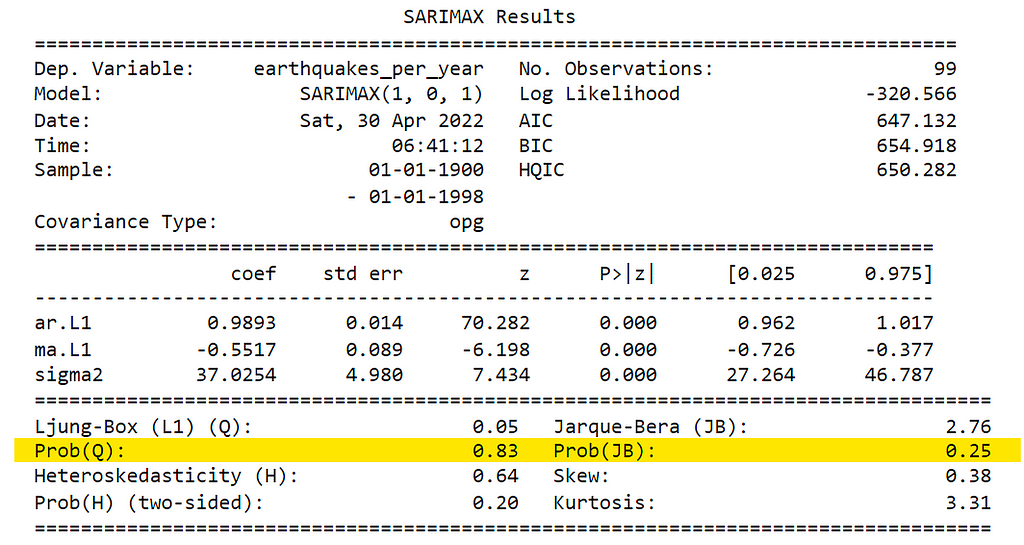
The values of Prob(Q) and Prob(JB) are both more than 0.05, so we cannot reject the null hypothesis that the residuals are Gaussian normally distributed.
3.4. The Box-Jenkins method
The Box-Jenkins method is a checklist that helps you to go from raw data to a model ready for production. The three main steps in this method to follow to go from raw data to a production-ready model: identification, estimation, model diagnostics, and decision making based on the model diagnostics. This could be summarized in the figure below.
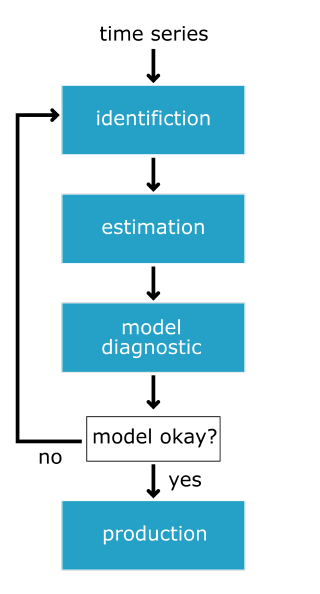
Identification
In the identification step, we explore and characterize the data to find the appropriate form of the data so as to be used in the estimation step. First, we will investigate whether the data is stationary or not. If the data is not stationary, we will find which transformation will transfer the data into stationary, and finally, we will identify the order of p and q that are most promising.
The tools used in this step are plotting, augmented dicky-fuller test, differencing and other transformation such as log transformation, and ACF and PACF for identifying promising model orders.
Estimation
In the estimation step the model is trained and the AR and MA coefficients of the data. This is automatically done for us by the model.fit method. In this step, we can fit many models and use BIC and AIC to narrow them down to more promising models.
Model Diagnostics
Using the information gathered from statistical tests and plots during the diagnostic step, we need to make a decision. Is the model good enough or do we need to go back and rework it? if the residuals are not as they should be we will go back and rethink our choices in the previous two steps. If the residuals are okay then we can go ahead and make forecasts!
This should be your general project workflow when developing time series models. You may have to repeat the process a few times in order to build a model that fits well.
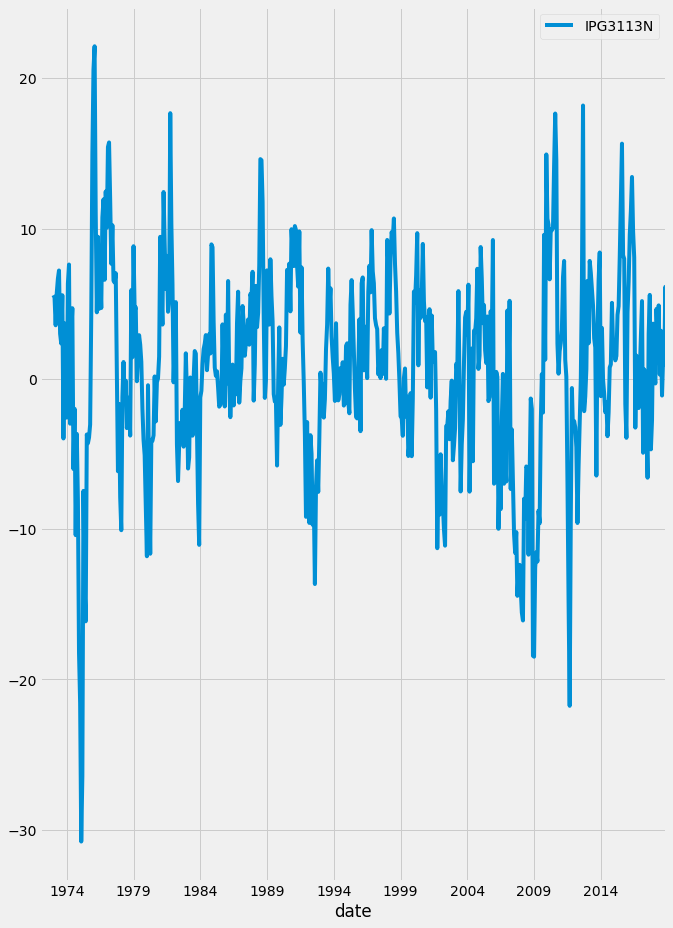
Let’s apply the Box-Jenkins method to new data. The data will be used is the co2 emission between 1958 to 2018. We will go through the three steps. We will start with identification. First, we will load and plot the data using the code below.
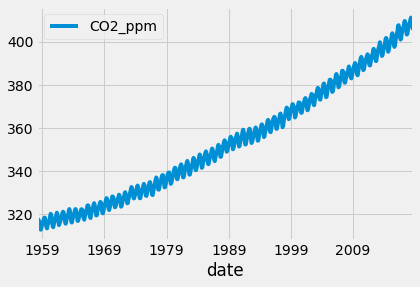
It is obvious that there is a trend in the data. Then we will apply the augmented Dicky-Fuller test.

The p-value is 1 which means that we can not reject the null hypothesis that the time series is non-stationary. To convert it to stationery, let’s take the first difference and plot it and apply the augmented Dicky-Fuller test.

The p-value is less than 0.05 so we can reject the null hypothesis and the data can be assumed that it is stationary. The first difference in the co2 data is shown in the figure below.
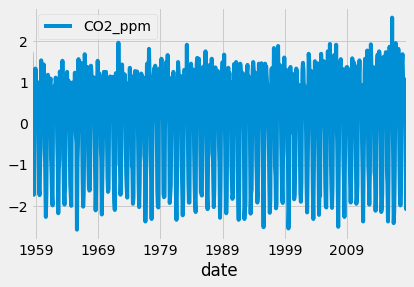
The last step of the identification is to plot the ACF and PACF plot for the first difference in the co2 emission data.
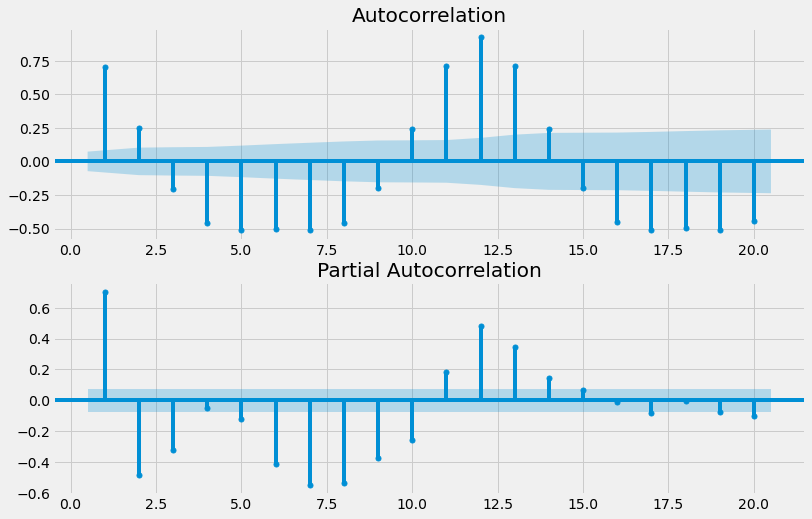
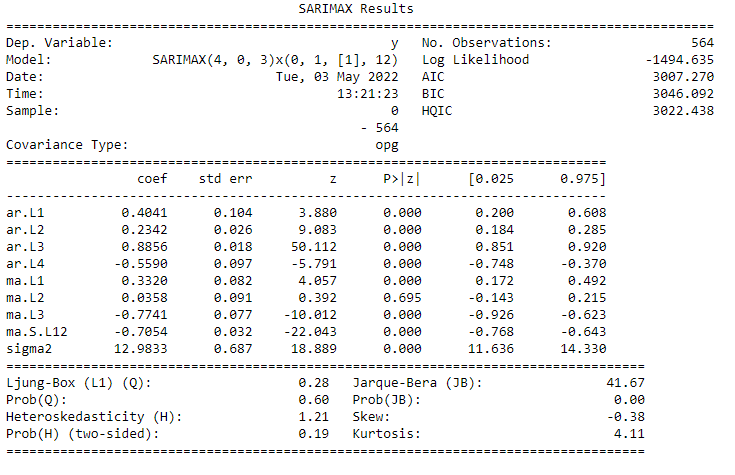
The ACF and PACF plot does not follow a certain pattern. So it will be difficult to identify the model order. So instead we will use the AIC and BIC to narrow down the choice of the model order and then fit the data to the best model. This is the second step which is the estimation step.
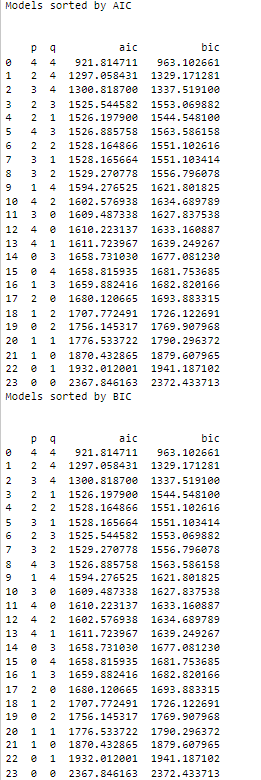
The best model order is (4,4). Let’s use this order to fit the data and then diagnose the model by analyzing the model residuals.
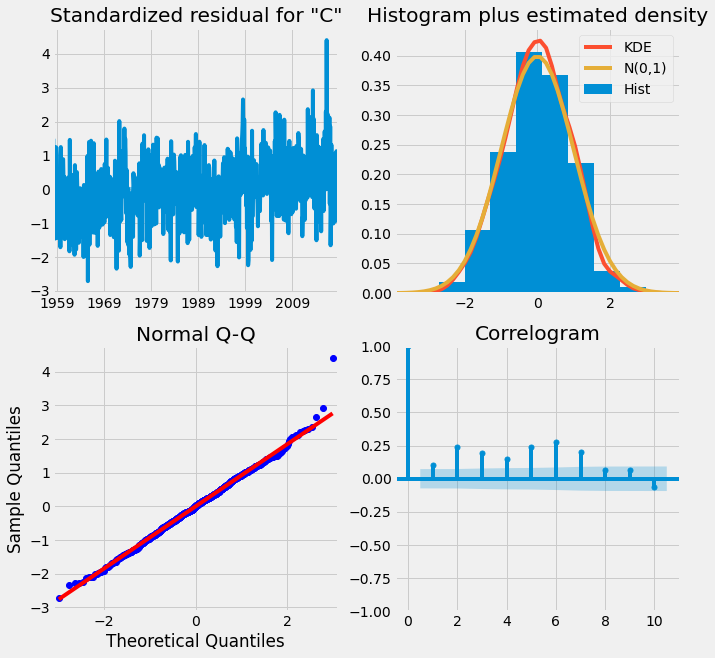
From the plots, we can make a decision that the model is doing well on the data, and no need to do another iteration.
2. Seasonal ARIMA Models
In the final section, we will discuss how to use seasonal ARIMA models to fit more complex data. You’ll learn how to decompose this data into seasonal and non-seasonal parts and then you’ll get the chance to utilize all your ARIMA tools on one last global forecast challenge.
2.1. Introduction to seasonal time series
A seasonal time series has predictable patterns that repeat regularly. Although we call this feature seasonality, it can repeat after any length of time. These seasonal cycles might repeat every year like sales of suncream, every week like the number of visitors to a park, or every day like the number of users on a website at any hour.
Any time series can be thought of to be made of three main components: trend, seasonal component, and the residual. The figure below shows the three components of the candy production time series used before.
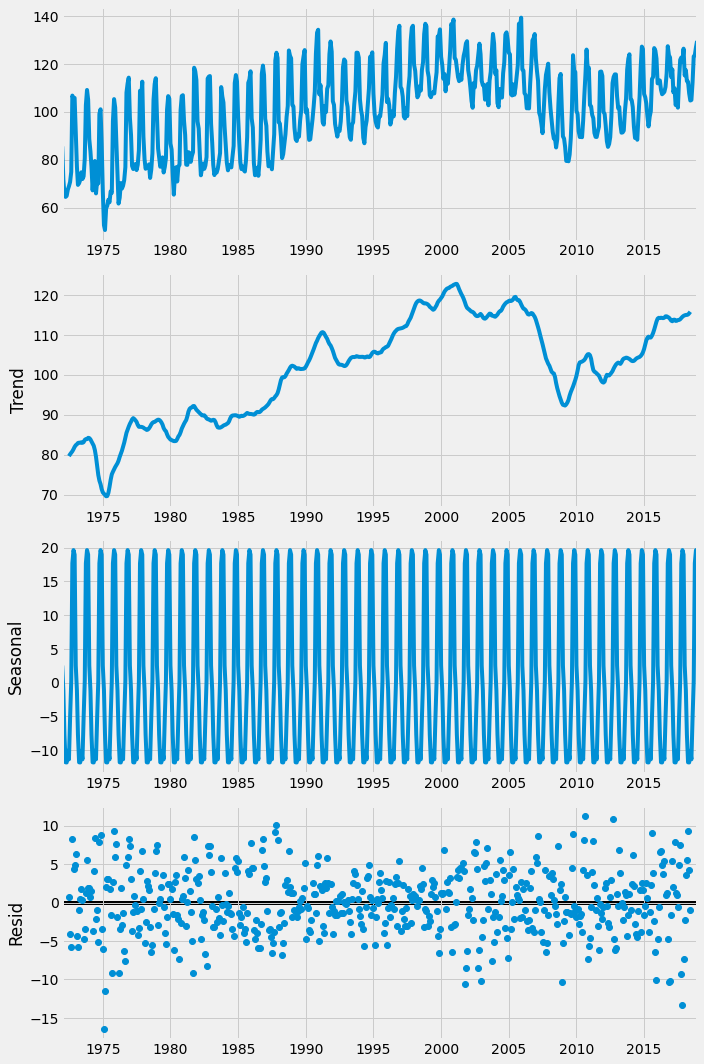
From the figure above it is obvious that there is a seasonality in the data. The cycle here is 12 months. However, this was given as a parameter to the function. If we would like to find the cycle or the seasonality cycle, one method is to use the ACF and observe the lag after which the correlation pattern gets repeated. However, it is important to make sure that the data is stationary. Since the candy production data is not stationary as it contains trends, we can transform it into stationary by taking the first difference. However, this time we are only trying to find the period of the time series, and the ACF plot will be clearer if we just subtract the rolling mean. We calculate the rolling mean using the DataFrame’s .rolling method where we pass the window size and also use the .mean method. Any large window size, N, will work for this. We subtract this from the original time series and drop the NA values. The time series is now stationary and it will be easier to interpret the ACF plot.
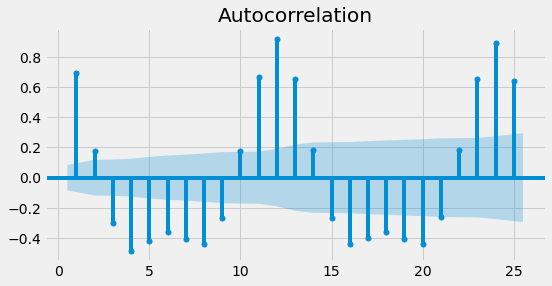
After plotting the ACF of the detrended data, we can clearly see that there is a seasonal period of 12 steps. Since the data is seasonal we will always have correlated residuals left if we try to fit an ARIMA model to it. This means that we aren’t using all of the information in the data, and so we aren’t making the best predictions possible. This will be solved by using the seasonal Arima as will be shown in the next subsection.
2.2. Seasonal ARIMA model
In the previous subsection, we discussed how to find seasonality in the data, in this subsection we will know how to use the seasonality to make more accurate predictions. The seasonal ARIMA (SARIMA) is used for this. Fitting a SARIMA model is like fitting two different ARIMA models at once, one to the seasonal part and another to the non-seasonal part. Since we have these two models we will have two sets of orders. We have non-seasonal orders for the autoregressive (p), the difference (d), and moving average (q) parts. We also have this set of orders for the non-seasonal part added to them a new order, S, which is the length of the seasonal cycle.
Let’s compare the SARIMA and ARIMA models further. Below is the equation of the ARIMA model with parameters (2,0,1). In this equation, we regress the time series against itself at lags-1 and 2 and against the shock at lag-1.
ARIMA(2,0,1) model :
y(t) = a(1) y(t-1) + a(2) y(t-2) + m(1) ϵ(t-1) + ϵ(t)
Below is the equation for a simple SARIMA model with a season length of 7 days. This SARIMA model only has a seasonal part; we have set the non-seasonal orders to zero. We regress the time series against itself at lags of one season and two seasons and against the shock at a lag of one season.
SARIMA(0,0,0)(2,0,1)7 model:
y = a (7)y(t-7) + a(14)y(t-14) + m(7) ϵ(t-7) + ϵ(t)
This particular SARIMA model will be able to capture seasonal, weekly patterns, but won’t be able to capture local, day-to-day patterns. If we construct a SARIMA model and include non-seasonal orders as well, then we can capture both of these patterns.
Fitting a SARIMA model is almost the same as fitting an ARIMA model. We import the model object and fit it as before. The only difference is that we have to specify the seasonal order as well as the regular order when we instantiate the model.
This means that there are a lot of model orders we need to find. In the last subsection, we learned how to find the seasonal period, S, using the ACF. The next task is to find the order of seasonal differencing.
To make a time series stationary we may need to apply seasonal differencing. In seasonal differencing, instead of subtracting the most recent time series value, we subtract the time series value from one cycle ago. We can take the seasonal difference by using the df.diff method. This time we pass in an integer S, the length of the seasonal cycle.
If the time series shows a trend then we take the normal difference. Once we have found the two orders of differencing and made the time series stationary, we need to find the other model orders. To find the non-seasonal orders (p,q), we plot the ACF and the PACF of the differenced time series. To find the seasonal orders (P, Q) we plot the ACF and PACF of the differenced time series at multiple seasonal steps. Then we can use the same table of ACF and PACF rules to work out the seasonal order. We make these seasonal ACF and PACF plots using the plot_acf and plot_pacf functions, but this time we set the lags parameter to a list of lags instead of a maximum. This plots the ACF and PACF at these specific lags only.
Let’s apply this to the candy production time series used in the previous subsection. We know that the seasonal period of the data is 12 steps. So first we will take the seasonal difference to remove the seasonal effect and then one step difference to remove the trend effect.
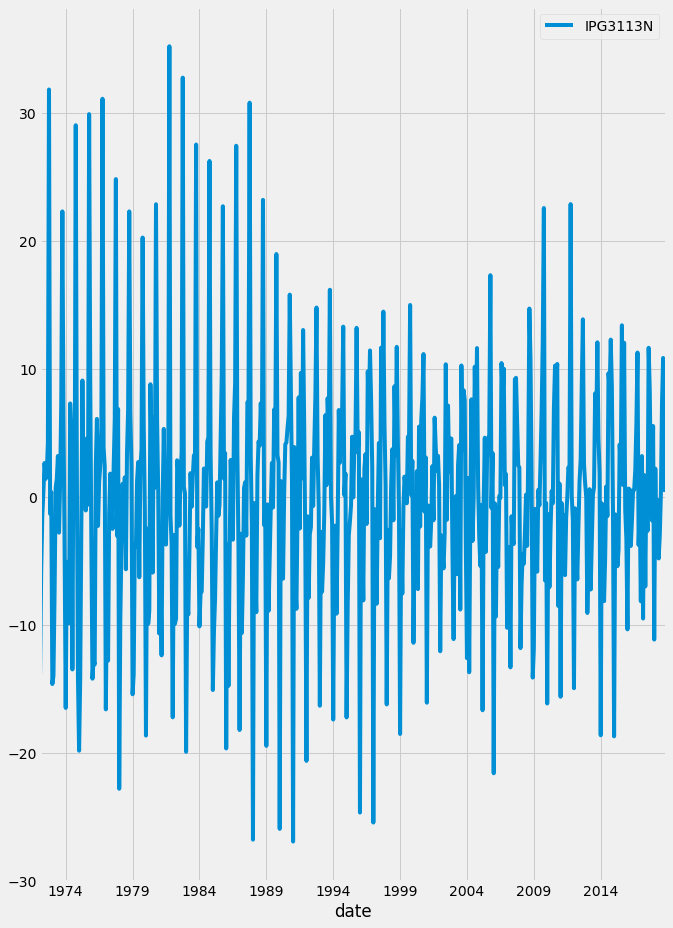
Applying the augment Adfuller-Dickey test to make sure that the time series is now stationary.

The p-value is less than 0.05 so we can reject the null hypothesis and assume that the time series now is stationary. After that, we will plot the ACF and PACF to find the non-seasonal model parameters.
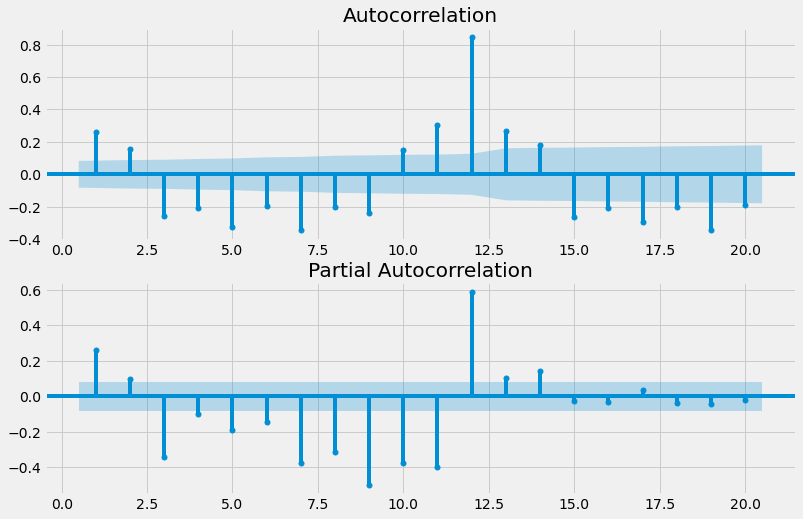
There is no clear pattern in the ACF and PACF plots, so we will use the AIC and BIC to narrow down our choices.
The best model parameters are (0,3). After that, we will plot the seasonal ACF and PACF to find the seasonal parameters.
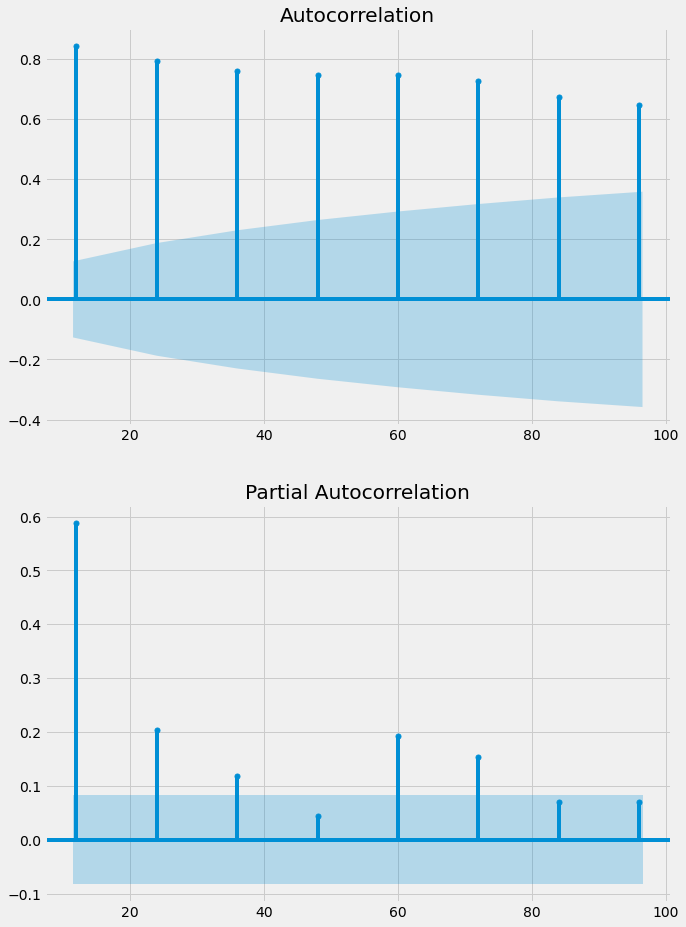
The ACF is tailing off and the PACF is cut off after a lag of three. So the model parameter is (0,3). The final step is to fit the model with all of these parameters.
2.3. Process automation and model saving
Previously we searched over ARIMA model order using for loops. Now that we have seasonal orders as well, this is very complex. Fortunately, there is a package that will do most of this work for us. This is the pmdarima package The auto_arima function from this package loops over model orders to find the best one. The object returned by the function is the results object of the best model found by the search. This object is almost exactly like a statsmodels SARIMAX results object and has the summary and the plot-diagnostics method.
The order of the best model found by the search is (2,3). However, it did not take the seasonal components into consideration. To do this we have to set the seasonal parameter to true. We also need to specify the length of the seasonal period; and the order of seasonal differencing. Finally, we will use a few non-order parameters. Using information_criterion you can select whether to choose the best model based on AIC or BIC, if information_criterion =’aic’ it will select it based on AIC and if it is information_criterion= ‘bic’ it will select it based on BIC. Also, we will set the trace parameter to true then this function prints the AIC and BIC for each model it fits. To ignore bad models we will set the error_action= ‘ignore’. We will set the stepwise to true then instead of searching over all of the model orders, the function searches outwards from the initial model order guess using an intelligent search method. This might save running time and computation power.

Once you have fit a model in this way, you may want to save it and load it later. You can do this using the joblib package. To save the model we use the dump function from the joblib package. We pass the model results object and the file_path into this function. Later on, when we want to make new predictions we can load this model again. To do this we use the load function from joblib.
If you have new data and you would like to update the trained model, you can use the model.update(new_data). This isn’t the same as choosing the model order again and so if you are updating with a large amount of new data it may be best to go back to the start of the Box-Jenkins method.
2.4. SARIMA and Box-Jenkins for seasonal time series
We previously covered the Box-Jenkins method for ARIMA models. We go through the identification of the model order; estimating or fitting the model; diagnosing the model residuals, and finally production. For SARIMA models the only step in the method which will change is the identification step. At the identification step we add the tasks of determining whether a time series is seasonal, and if so, then finding its seasonal period. We also need to consider transforms to make the seasonal time series stationary, such as seasonal and non-seasonal differencing and other transforms. Sometimes we will have the choice of whether to apply seasonal differencing, non-seasonal differencing, or both to make a time series stationary. Some good rules of thumb are that you should never use more than one order of seasonal differencing, and never more than two orders of differencing in total. Sometimes you will be able to make a time series stationary by using either one seasonal difference or one non-seasonal difference.
There are two types of seasonality: weak seasonality and strong seasonality. In weak seasonality, the seasonal oscillations in the time series will not always look the same and will be harder to identify. While in the strong seasonality the seasonality pattern in the time series will be strong. When you have a strong seasonal pattern you should always use one order of seasonal differencing. This will ensure that the seasonal oscillation will remain in your dynamic predictions far into the future without fading out. While in a weak seasonal pattern use it if only necessary.
Just like in ARIMA modeling sometimes we need to use other transformations on our time series before fitting. If the seasonality is Additive seasonality in which the seasonal pattern just adds or takes away a little from the trend. Whenever the seasonality is additive we shouldn’t need to apply any transforms except differencing. If the seasonality is multiplicative the amplitude of the seasonal oscillations will get larger as the data trends up or smaller as it trends down. If the seasonality is multiplicative, the SARIMA model can’t fit this without extra transforms. To deal with this we take the log transform of the data before modeling it.
3. References
[1]. https://app.datacamp.com/learn/courses/arima-models-in-python
[2].https://www.statsmodels.org/devel/generated/statsmodels.tsa.arima.model.ARIMA.html
Thanks for reading! If you like the article make sure to clap (up to 50!) and connect with me on LinkedIn and follow me on Medium to stay updated with my new articles.
Time Series Forecasting with ARIMA Models In Python [Part 2] was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

