



The Role of Product Data Science
Last Updated on July 25, 2023 by Editorial Team
Author(s): Lisa Cohen
Originally published on Towards AI.
Data science organizations help companies leverage data to build better products, improve customer experiences and grow the business. Yet, data scientists can get pulled into many directions. Amongst the endless opportunities that come by their desks and questions that arise, where should they spend their time? This post sets a vision for the role of a data science organization and how the team can maximize its impact.
Project categories
Here are the types of work that a data scientist does:

– Descriptive: Data scientists and analysts are the experts in how customers use the product and can describe the product “in numbers”. Descriptive analysis can include describing user patterns, customer journeys, growth funnels, and more.
– Diagnostic: Through causal analysis, experimentation, customer journey research and cohorts, data scientists find the reason behind metric trend changes, and determine which leading indicators cause future outcomes.
– Predictive: Through forecasts, data scientists can help predict future outcomes, such as propensity models, projected metric growth, whether a customer will be satisfied or churn, and their future lifetime value.
– Prescriptive: With all these insights and expertise, data scientists are well positioned to drive strategic discussions recommending product & program changes, and influence the roadmap. This can be through initiating feature ideas, consulting on potential investments, or building ML models that recommend the next best action.
Product development process
Here is an overview of how these tasks come to life, as part of the product development process:
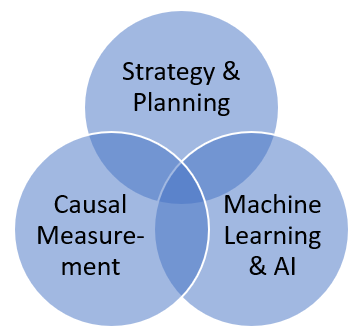
Strategy & Planning
Data Science helps inform strategy and guides product design & development, by providing thought leadership. DS engages as a co-owner with cross-functional partners (Product, Eng, Design, Research, Marketing, Sales, Finance), identifying opportunities that help achieve business goals, and uses data storytelling to communicate in a way that influences the product roadmap, and brings these ideas through to fruition.
– Hypothesis generation (and investigation). Identify new opportunities, based on data insights & discoveries, that help us achieve our product & business goals. Recommend product strategy or direction, based on customer insights or market data. Ex: Discovering the product’s magical “aha” moment (such as “Facebook’s 7 friends in 10 days”) which leads to increased retention, and proposing product designs to promote this “happy path”.
– Opportunity assessment: Assessing the opportunity of potential plans in order to prioritize our investments. Providing input on plans, based on past data learnings. Ex: Opportunity sizing roadmap investments to decide which to tackle in the next planning cycle, given limited resources.
Causality & Measurement
Data science offers a source of truth to understand & track progress. This involves analyses, experimentation, and causal inference.
– Success metrics: Defining metrics for product areas and the company. Identifying leading indicators through experimentation and causal analyses. Forecasting, goal setting, opportunity sizing.
– Experimentation: Defining experimentation guides and ship criteria. Defining holdback guidance to track impact over time. Defining consistent measurement practices (ex., metric governance)
– Running the business: Metric reviews and data storytelling for “running of the business”. Monitoring & identifying trend changes, and “first line of defense” for root cause analysis. Self-serve reporting to track progress on OKRs. * **
– Product expert in data: Customer and product usage understanding: Sizing stats and trends to help the company be data informed, with relevant reference points. *
* May also be driven by data analysts, where available. ** Reporting may also be done by product/business teams with data experience, if event data is exposed for broader access.
Machine Learning & Artificial Intelligence
More and more products are becoming ML & AI driven as users expect more personalized experiences (with ML) and productive experiences (with generative AI). Thus, companies are leveraging data and providing intelligent experiences that anticipate user needs and preferences. Another way that Data Science engages in product development is by advancing our models to improve their performance. Here are the ways DS contributes:
– Feature identification: Having strong domain context and experience analyzing user behavior, DS is well-positioned to identify new signals (and suggest scribe when needed), in order to best model the user experience and capture key features in the model.
– Influencing model design, parameters, and/or feature improvements: DS partners with MLEs in the model development process to hone the objective functions, parameter tuning, optimize training data, assess data quality, identify positive/negative signals, etc.
– Metrics: DS can help inform offline & online model evaluation metrics, as well as the objective functions to optimize.
– Model understanding: DS can also help us learn from models, for example by analyzing the top predictive features.
– Proof of concept models: DS can incubate new model ideas that emerge as part of their product analyses. In this case, there is a lifecycle such that if/when the models reach a production state, they get prioritized within the MLE roadmap, and transition ownership to MLE to run, service and maintain in production (which may also involve some re-writing). Note: This work is typically performed by an “Applied DS” archetype of DS.
– Business models: There are also opportunities for DS to develop internal, business-facing models. Ex. paid media optimization, multi-attribution models, LTV.
Note: ML & AI contributions are role/team dependent, and may not be needed for all DS roles, as it varies by product area and the nature of the domain. However, it continues to be a growing area, so it can be useful to add to a data scientist’s “toolbelt”. Like Conway’s DS Venn Diagram, this post is meant to describe a DS organization rather than a particular individual needing to fulfill all the functions themselves.
Roles and responsibilities
Setting standard roles & responsibilities can help align expectations across functions. Below are some common scenarios that arise with data scientists and cross-functional partners. (Note: This section is intended to clarify expectations, not create hard lines that limit how a function can contribute.)
Product Strategy & Vision: Documenting the product strategy, vision, and feature specs. This is led by Product, with Eng, DS, Design, and Research as key contributors and co-owners.
Defining OKR metrics: Choosing success metrics, metric definitions, metric implementation, forecasting, and opportunity sizing. This is led by DS, with Product as the approver and Eng, Design, and Research as contributors.
Setting OKR goals/targets: After reviewing the DS-provided forecast above, the Product ultimately determines the target based on the current roadmap, anticipated events, and level of aspiration. All functions should discuss, debate, and then be able to stand behind the final target choice when reviewing quarterly performance.
Holdbacks: After running an experiment, we typically ship changes with a 3–6mo holdback, to measure the long-term causal effect. DS is responsible for defining the product holdback strategy, to be used consistently across feature areas. This includes feature-level “all time” holdbacks, 3–6mo “incremental holdbacks”, and architecting the “warm up” plan to ramp up/down between incremental holdbacks.
Metric Reviews: Data scientists (or Data analysts) prepare the data and analysis for monthly and quarterly metric reviews. This is typically automated through self-serve systems, which Product may also pull for more frequent sprint reviews.
Experimentation and ship criteria: The data science team defines and documents guidance for experiment design, power analysis, checklists, ship criteria & best practices. Designated DS, Product and Eng leads review the experiments for their team areas, to foster expertise, establish consistency and prevent experiment collisions. Ship criteria help guide the “launch or not” decision in cases where some metrics improve while others worsen, and establish an allowable tradeoff based on analysis of the two metrics. As experimentation increases in scale, we can federate experiment review (according to agreed-upon criteria) and broadcast the results, while maintaining a central repository to review past experiments.
Scribing / Instrumentation: Having quality instrumentation is essential to be able to track how a feature is working. The instrumentation plan should be included in the feature spec and implemented by Engineering as part of the feature development. Data engineering helps set up monitoring and alerting to ensure ongoing data quality.
Self-Serve Data Access: Dashboards can be an effective way to democratize access to key metrics and enable teams to self-serve for metric reviews. Data science owns the canonical queries, metric governance, and dashboard correctness (for dashboards they own). Data engineering is responsible for the underlying datasets & pipelines (including data quality monitoring).
Investigating Changes in Business Metric Trends: When metric trends change, teams can use dashboard “slicers” to identify if it is isolated to a specific cohort, or query the data directly to test further hypotheses. Data science can lead the initial investigation (if prioritized), to identify the nature of the issues (i.e., data quality, code change, segmentation analysis, etc). Eng can investigate further for potential code changes or feature switches from recent launches, which may be responsible. Data engineering can investigate potential data quality issues.
DS Roadmap Planning: There are an infinite number of questions data scientists can analyze. However, Data Science is not infinitely resourced, and must optimize towards the highest impact opportunities. Therefore, Data Science is not expected to answer every question they are asked. When proposing a project to DS, stakeholders should clearly articulate:
1. What is the overall goal of the project, or underlying question you’re trying to answer, and why?
2. What decision or action will occur based on the result of this project?
3. What is the expected business impact? (Conversely, what will happen if it doesn’t get completed?)
Using this information, DS can prioritize appropriately, and more efficiently approach the project. DS doesn’t answer mere curiosity questions, and doesn’t typically create dashboards without a clear business question or expected decision/impact. The DS backlog should include a portfolio between stakeholder requests and at least 30% time towards DS-led innovation that accelerates business goals. Therefore, DS should create time for this through HackWeeks, focus weeks and roadmap planning.
The DS manager is ultimately responsible for the team output, and therefore is the approver on the team backlog. Similarly, Data Engineering and Experimentation platform teams should also own their roadmaps, while taking input from corresponding stakeholder teams. Technical PMs (TPMs) can also play a key role in facilitating the plan execution, tracking risks and dependencies, and communicating ETAs and deliverables.
Conclusion
In conclusion, Data science adds value at each step of the product development process. It can play a critical role by helping to inform strategy, guide design, and measure progress. By leveraging data to understand customer behavior and identify trends, data scientists can help companies develop products that are more effective and engaging. Without Data Science, you can execute the roadmap (i.e., run up the ladder), but with Data Science, you can ensure that the ladder is pointed the right direction, and uncover insights to get there more quickly.
Related resources
Managing a data science project
Designing a data science organization
Onboarding to a data science team
Data science learning resources
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

