



The NLP Cypher | 05.23.21
Last Updated on July 24, 2023 by Editorial Team
Last Updated on May 24, 2021 by Editorial Team
Author(s): Quantum Stat
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
Overtime
Hey Welcome back, another week goes by and so much code/research has been released into the wild.
Oh and btw, The NLP Index is on ??? , and I want to thank all contributors!
Here’s a quick glimpse at the awesome contributions: A collection of Spanish Medical NLP datasets brought to you by Salvador Lima in Barcelona. ?? Will update the NLP Index with these and other assets by tomorrow.
Cantemist (oncology clinical cases for cancer text mining): https://zenodo.org/record/3978041
PharmaCoNER (Pharmacological Substances, Compounds and proteins in Spanish clinical case reports): https://zenodo.org/record/4270158
CodiEsp (Abstracts from Lilacs and Ibecs with ICD10 codes): https://zenodo.org/record/3606662
MEDDOCAN (Medical Document Anonymization): https://zenodo.org/record/4279323
MESINESP2 (Medical Semantic Indexing): https://zenodo.org/record/4722925
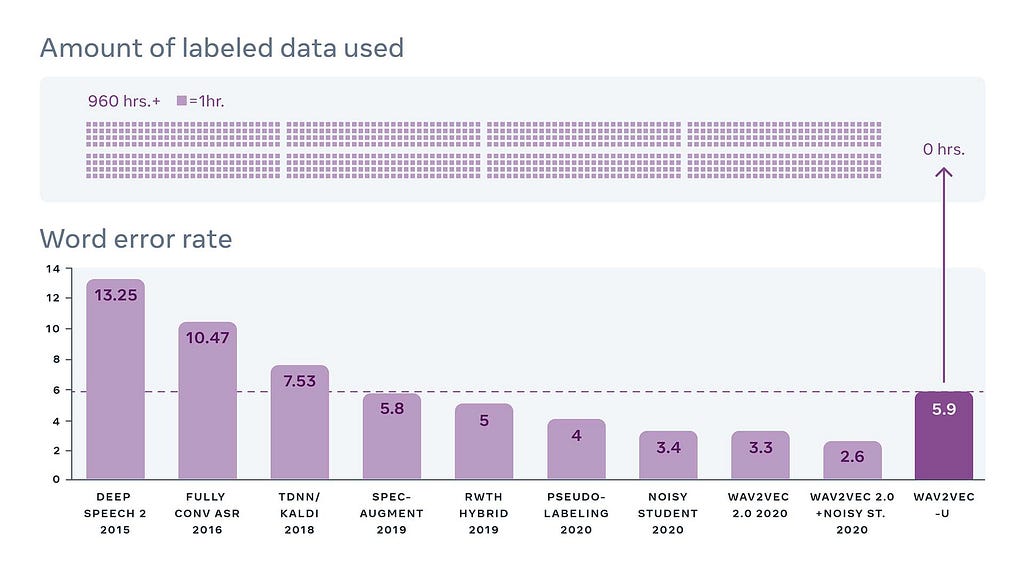
Wav2vec-U: Unsupervised Speech Recognition ?
This new FAIR model doesn’t need transcriptions to learn speech. It just needs unsupervised speech recordings and text. They used a GAN to help discriminate phonemes (sounds of language). While Wav2vec-U doesn’t achieve SOTA on the Librispeech benchmark, it still gets a pretty good score given the fact it didn’t require 960 hours of transcribed speech data. ?
Blog:
wav2vec Unsupervised: Speech recognition without supervision
Code:
Polars Dataframes ?
If you use dataframes often, you should check out Polars. It’s an awesome dataframe library written in Rust (includes Python bindings). Comes with Arrow support and all of its glory including parquet file and AWS S3 IO support.
Docs:
Universiteit van Amsterdam | Notebooks and Tutorials
The University of Amsterdam has a sweet collection of colab notebooks mixing various domains including GNNs, Transformers and computer vision.
Here’s their TOC:
Tutorial 2: Introduction to PyTorch
Tutorial 3: Activation functions
Tutorial 4: Optimization and Initialization
Tutorial 5: Inception, ResNet and DenseNet
Tutorial 6: Transformers and Multi-Head Attention
Tutorial 7: Graph Neural Networks
Tutorial 8: Deep Energy Models
Tutorial 9: Autoencoders
Tutorial 10: Adversarial Attacks
Tutorial 11: Normalizing Flows
Tutorial 12: Autoregressive Image Modeling
Welcome to the UvA Deep Learning Tutorials! – UvA DL Notebooks v1.0 documentation
KELM | Converting WikiData to Natural Language
Google introduces the KELM dataset in a huge win for the factoid nerds. The dataset is a Wikidata knowledge graph converted into natural language with the idea of using the corpus for improving the factual knowledge in pretrained models! A T5 was used for this conversion. The corpus consists of ~18M sentences spanning ~45M triples and ~1500 relations.
KELM: Integrating Knowledge Graphs with Language Model Pre-training Corpora
Talkin’ about knowledge graphs…
An Introduction to Knowledge Graphs
No Trash Search!
LabML.AI Annotated PyTorch Papers
Learn from academic papers annotated with their corresponding code. Pretty cool if you want to decipher research.
labml.ai Annotated PyTorch Paper Implementations
Completely Normal (aka not suspect) Task
Repo Cypher ??
A collection of recently released repos that caught our ?
Measuring Coding Challenge Competence With APPS
A benchmark for code generation.
Check out the GPT-Neo results when compared to GPT-2/3, very interesting.
wikipiifed — Automated Dataset Creation and Federated Learning
A repo for automating dataset creation from wikipedia biography pages and utilizing the dataset for federated learning of BERT based named entity recognizer.
OpenMEVA Benchmark
OpenMEVA is a benchmark for evaluating open-ended story generation.
KLUE: Korean Language Understanding Evaluation
KLUE benchmark is composed of 8 tasks:
- Topic Classification (TC)
- Sentence Textual Similarity (STS)
- Natural Language Inference (NLI)
- Named Entity Recognition (NER)
- Relation Extraction (RE)
- (Part-Of-Speech) + Dependency Parsing (DP)
- Machine Reading Comprehension (MRC)
- Dialogue State Tracking (DST)
Contextual Machine Translation
Context-aware models for document-level machine translation. Also includes SCAT, an English-French dataset comprising supporting context words for 14K translations that professional translators found useful for pronoun disambiguation.
Most MT models are on the sentence level, so this is an interesting repo for those looking to go onto the document level.
Dataset of the Week: Few-NERD
What is it?
Few-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities and 4,601,223 tokens. Three benchmark tasks are built, one is supervised: Few-NERD (SUP) and the other two are few-shot: Few-NERD (INTRA) and Few-NERD (INTER).
Sample (in typical NER format)
Between O
1789 O
and O
1793 O
he O
sat O
on O
a O
committee O
reviewing O
the O
administrative MISC-law
constitution MISC-law
of MISC-law
Galicia MISC-law
to O
little O
effect O
. O
Where is it?
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat

The NLP Cypher | 05.23.21 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





