



The NLP Cypher | 02.28.21
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
The NLP Cypher U+007C 02.28.21
Zeroshot
Hey welcome back! Plenty to talk about this week. But first some quick housekeeping. We’ll be updating the Super Duper NLP Repo this upcoming week… finally U+1F601. If you have an awesome NLP notebook to add drop us a note on our contact page and we’ll give you a shoutout on our update tweet. … U+1F680
Ok, if you own a KIA automobile please read this…U+1F447
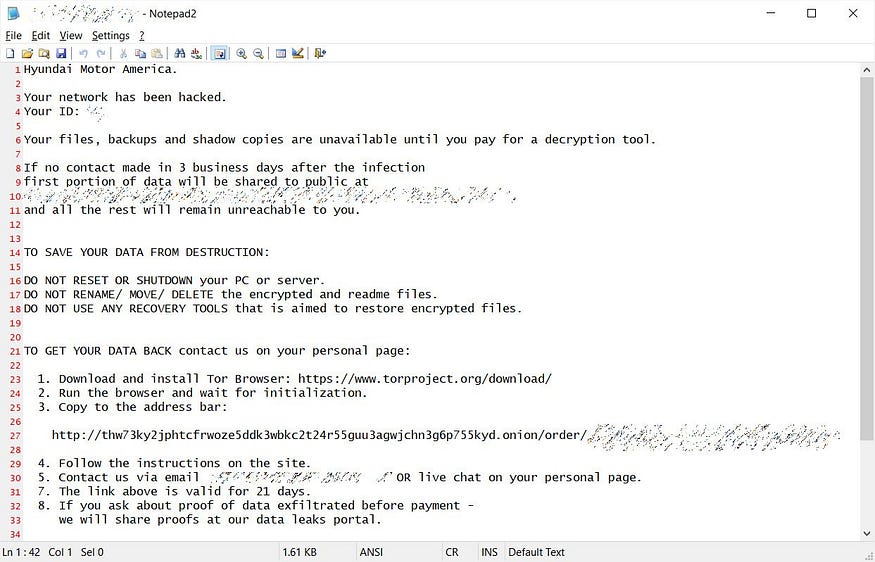
KIA was apparently hacked with ransomware earlier this month, and the actors want to be paid in full. They are asking for a cool $21 million in BTC. KIA has denied the allegations it was ever hacked although they recently suffered network outages.
Read more here.
Consequences of the Hack U+1F440
“Kia’s key connected services remain offline, meaning customers are unable to pay their car loans, remotely start their vehicles, or other functions using Kia’s infrastructure.” — the drive blog
A *PSEUDO* DALL-E Appears From the Ashes
OpenAI opened the week with a pre-emptive strike w/r/t its DALL-E project by releasing *part* of the model. They released the image reconstruction *part* d-VAE. The actual encoder language model remains out of pocket, and without this, we can’t actually achieve what they demo’d in their paper.
openai/DALL-E
PyTorch package for the discrete VAE used for DALL·E. – openai/DALL-E
github.com
OpenAI’s CLIP Implementations:
If you’re still interested in OpenAI’s CLIP, we found a YUUUGE list on Reddit highlighting a ton of Colab/Jupyter notebooks running the model!! U+1F525U+1F525
U+26A0 WARNING length of list may impair your judgement, we recommend you avoid driving or operating heavy machinery while reading. U+26A0
- The Big Sleep: BigGANxCLIP.ipynb — Colaboratory by advadnoun. Uses BigGAN to generate images. To my knowledge, this is the first CLIP-steered BigGAN app that was released. Instructions and examples. Notebook copy by levindabhi.
- (Added Feb. 15, 2021) Drive-Integrated The Big Sleep: BigGANxCLIP.ipynb — Colaboratory by advadnoun. Uses BigGAN to generate images.
- Big Sleep — Colaboratory by lucidrains. Uses BigGAN to generate images. The GitHub repo has a local machine version. GitHub.
- The Big Sleep Customized NMKD Public.ipynb — Colaboratory by nmkd. Uses BigGAN to generate images. Allows multiple samples to be generated in a run.
- Text2Image — Colaboratory by tg_bomze. Uses BigGAN to generate images. GitHub.
- Text2Image_v2 — Colaboratory by tg_bomze. Uses BigGAN to generate images. GitHub.
- Text2Image_v3 — Colaboratory by tg_bomze. Uses BigGAN (default) or Sigmoid to generate images. GitHub.
- (Added Feb. 26, 2021) Image Guided Big Sleep Public.ipynb — Colaboratory by jdude_. Uses BigGAN to generate images. Reddit post.
- ClipBigGAN.ipynb — Colaboratory by eyaler. Uses BigGAN to generate images/videos. GitHub. Notebook copy by levindabhi.
- WanderCLIP.ipynb — Colaboratory by eyaler. Uses BigGAN (default) or Sigmoid to generate images/videos. GitHub.
- Story2Hallucination.ipynb — Colaboratory by bonkerfield. Uses BigGAN to generate images/videos. GitHub.
- (Added around Feb. 7, 2021) Story2Hallucination_GIF.ipynb — Colaboratory by bonkerfield. Uses BigGAN to generate images. GitHub.
- (Added Feb. 24, 2021) Colab-BigGANxCLIP.ipynb — Colaboratory by styler00dollar. Uses BigGAN to generate images. “Just a more compressed/smaller version of that [advadnoun’s] notebook”. GitHub.
- CLIP-GLaSS.ipynb — Colaboratory by Galatolo. Uses BigGAN (default) or StyleGAN to generate images. The GPT2 config is for image-to-text, not text-to-image. GitHub.
- (Added Feb. 15, 2021) dank.xyz. Uses BigGAN or StyleGAN to generate images. An easy-to-use website for accessing The Big Sleep and CLIP-GLaSS. To my knowledge this site is not affiliated with the developers of The Big Sleep or CLIP-GLaSS. Reddit reference.
- (Added Feb. 25, 2021) Aleph-Image: CLIPxDAll-E.ipynb — Colaboratory by advadnoun. Uses DALL-E’s discrete VAE (variational autoencoder) component to generate images. Twitter reference. Reddit post.
- (Added Feb. 26, 2021) Aleph2Image (delta): CLIP+DALL-E decoder.ipynb — Colaboratory by advadnoun. Uses DALL-E’s discrete VAE (variational autoencoder) component to generate images. Twitter reference. Reddit post.
- (Added Feb. 27, 2021) Copy of working wow good of gamma aleph2img.ipynb — Colaboratory by advadnoun. Uses DALL-E’s discrete VAE (variational autoencoder) component to generate images. Twitter reference.
- (Added Feb. 27, 2021) Aleph-Image: CLIPxDAll-E (with white blotch fix #2) — Colaboratory by thomash. Uses DALL-E’s discrete VAE (variational autoencoder) component to generate images. Applies the white blotch fix mentioned here to advadnoun’s “Aleph-Image: CLIPxDAll-E” notebook.
- (Added Feb. 14, 2021) GA StyleGAN2 WikiArt CLIP Experiments — Pytorch — clean — Colaboratory by pbaylies. Uses StyleGAN to generate images. More info.
- (Added Feb. 15, 2021) StyleCLIP — Colaboratory by orpatashnik. Uses StyleGAN to generate images. GitHub. Twitter reference. Reddit post.
- (Added Feb. 15, 2021) StyleCLIP by vipermu. Uses StyleGAN to generate images.
- (Added Feb. 24, 2021) CLIP_StyleGAN.ipynb — Colaboratory by levindabhi. Uses StyleGAN to generate images.
- (Added Feb. 23, 2021) TediGAN — Colaboratory by weihaox. Uses StyleGAN to generate images. GitHub. I got error “No pre-trained weights found for perceptual model!” when I used the Colab notebook, which was fixed when I made the change mentioned here. After this change, I still got an error in the cell that displays the images, but the results were in the remote file system. Use the “Files” icon on the left to browse the remote file system.
- TADNE and CLIP — Colaboratory by nagolinc. Uses TADNE (“This Anime Does Not Exist”) to generate images. GitHub.
- CLIP + TADNE (pytorch) v2 — Colaboratory by nagolinc. Uses TADNE (“This Anime Does Not Exist”) to generate images. Instructions and examples. GitHub. Notebook copy by levindabhi
- (Added Feb. 24, 2021) clipping-CLIP-to-GAN by cloneofsimo. Uses FastGAN to generate images.
- CLIP & gradient ascent for text-to-image (Deep Daze?).ipynb — Colaboratory by advadnoun. Uses SIREN to generate images. To my knowledge, this is the first app released that uses CLIP for steering image creation. Instructions and examples. Notebook copy by levindabhi.
- Deep Daze — Colaboratory by lucidrains. Uses SIREN to generate images. The GitHub repo has a local machine version. GitHub. Notebook copy by levindabhi.
- CLIP-SIREN-WithSampleDL.ipynb — Colaboratory by norod78. Uses SIREN to generate images.
- (Added Feb. 17, 2021) Text2Image Siren+.ipynb — Colaboratory by eps696. Uses SIREN to generate images. Twitter reference. Example #1. Example #2. Example #3.
- (Added Feb. 24, 2021) Colab-deep-daze — Colaboratory by styler00dollar. Uses SIREN to generate images. I did not get this notebook to work, but your results may vary. GitHub.
- (Added Feb. 18, 2021) Text2Image FFT.ipynb — Colaboratory by eps696. Uses FFT (Fast Fourier Transform) from Lucent/Lucid to generate images. Twitter reference. Example #1. Example #2.
Recent Advances in Language Model Fine-Tuning
Sebastian Ruder, one of the pioneers of transfer learning in NLP, has an awesome new blog post on the recent advances in fine-tuning. The five categories below are discussed. This is a must read if you are anywhere near the realm of NLP.

Recent Advances in Language Model Fine-tuning
Fine-tuning a pre-trained language model (LM) has become the de facto standard for doing transfer learning in natural…
ruder.io
Visualizing Community Structure in Graphs
Communities is a Python library for detecting community structure in graphs. It implements the following algorithms:
Louvain method
Girvan-Newman algorithm
Hierarchical clustering
Spectral clustering
Bron-Kerbosch algorithm
shobrook/communities
communities is a Python library for detecting community structure in graphs. It implements the following algorithms…
github.com
The Overflow U+007C Python Stats
Helpful post on the Stack Overflow blog discussing Python libraries such as numpy, pandas, matplotlib, and seaborn. There’s a YouTube Video on the page where they explore a New York City housing dataset. This is on the introductory level.
Level Up: Mastering statistics with Python – part 2 – Stack Overflow Blog
Welcome back! This is the second class in our Level Up series. If you're just tuning in, you can catch up on what we're…
stackoverflow.blog
BertViz
BertViz is a tool for visualizing attention in the Transformer model, supporting all models from the transformers library (BERT, GPT-2, XLNet, RoBERTa, XLM, CTRL, etc.)
Includes a Colab U+1F60E

jessevig/bertviz
BertViz is a tool for visualizing attention in the Transformer model, supporting all models from the transformers…
github.com
Contextualized Topic Models
Check out this awesome library if you are into topic modeling. They include a zeroshot cross-lingual variant and also a bag-of-words approach for various use-cases.
MilaNLProc/contextualized-topic-models
Contextualized Topic Models (CTM) are a family of topic models that use pre-trained representations of language (e.g…
github.com
Software UpdatesU+007C PyTorch Lightning

New Features:
- PyTorch autograd profiler
- DeepSpeed model parallelism
- Pruning
- quantization
- Stochastic weights averaging
PyTorch Lightning V1.2.0
Including new integrations with DeepSpeed, PyTorch profiler, Pruning, Quantization, SWA, PyTorch Geometric and more.
pytorch-lightning.medium.com
Software UpdatesU+007C Hugging Face
A new library from HF for pruning models resulting in fewer parameters while maintaining accuracy. Their sparsity notebook can be found on the Super Duper NLP Repo.
huggingface/nn_pruning
An interactive version of this site is available here. has been proved as a very efficient method to prune networks in…
github.com
Repo Cypher U+1F468U+1F4BB
A collection of recently released repos that caught our U+1F441
Few-Shot-Learning
A codebase to perform few-shot “in-context” learning using language models similar to the GPT-3 paper.
tonyzhaozh/few-shot-learning
This is a codebase to perform few-shot “in-context” learning using language models similar to the GPT-3 paper. In…
github.com
Connected Papers U+1F4C8
Graphs and Electronic Health Records
Model outperforms the existing graph and non-graph based methods in various electronic health records predictive tasks based on both public data and real-world clinical data.
NYUMedML/GNN_for_EHR
This repository contains the code for the paper Variationally Regularized Graph-based Representation Learning for…
github.com
Code Generation with GPT-2
Fine-tuning GPT-2 on CodeSearchNet for Code Generation
kandluis/code-gen
From /cs230/gpt-2-csn: $ pip install -r path/to/requirements.txt $ python download_model.py 117M Note that…
github.com
Connected Papers U+1F4C8
REMOD: Relation Extraction for Modeling Online Discourse
sdfsd
mjsumpter/remod
The following are the instructions to strictly reproduce the results cited in the paper. The necessary packages can be…
github.com
Connected Papers U+1F4C8
Argument Structure Prediction
This code can be used to train a set of neural networks to jointly perform Link Prediction, Relation Classification, and Component Classification on select argument mining corpora.
AGalassi/StructurePrediction18
Use of residual deep networks, ensemble learning, and attention for Argument Structure Prediction. This code can be…
github.com
Connected Papers U+1F4C8
Dataset of the Week: EmotionGIF 2020 Challenge
What is it?
Dataset contains 40,000 tweets and their GIF responses, labeled with the categories of the animated GIFs. The challenge: given unlabeled tweets, predict the category/categories of a GIF response. The GIFs are stored as MP4 files.
Sample
“idx”: 32,
“text”: “Fell right under my trap”,
“reply”: “Ouch!”,
“categories”: [‘awww’,’yes’,’oops’],
“mp4”: “fe6ec1cd04cd009f3a5975e2d288ff82.mp4”
Where is it?
EmotionGIF 2020 – Dataset
The EmotionGIF 2020 Challenge has ended. The big winner of both Rounds, with a total of participating teams, is Team…
sites.google.com
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

