



Start using Liquid Clustering instead of Partitioning for Delta tables in Databricks
Last Updated on November 20, 2023 by Editorial Team
Author(s): Muttineni Sai Rohith
Originally published on Towards AI.
Revolutionizing the way we organize the data, Databricks introduced a game-changer called Liquid Clustering in this year’s Data + AI Summit. An innovative feature that redefines the boundaries of partitioning and clustering for Delta tables.
Partitioning and Z-Ordering
In Delta Databricks, Partitioning involves organizing data into logical subsets based on specific columns, making it easier to fit the data into subsets and optimize the query performance. Additionally, Z-Ordering is further utilized with Partitioning to enhance the Data Organization. Here, data is sorted and stored in the order preferred, Optimizing the query performance. Together, in this way, both partitioning and Z-ordering help optimize query performance.
For example, In a Commercial relationship management system —
- Sales Data is partitioned by Region and SubRegion so that data can be partitioned into logical subsets for easy access to data.
- Further, the partitioned data can be Z-Ordered by TimeStamp or AccountID to optimize the query performance.
Issues with Partitioning and Z-Ordering
While Partitioning and Z-ordering can be used for Efficient Storage and Retrieval, they might slow down the process when writing the data as data needs to be reorganized every time while writing the data. There are the following issues with Partitioning and Z-Ordering —
- Skewed Distribution and High Cardinality: Uneven distribution of data might lead to Data Skewness where few Partitions may contain significantly more data than others. In Z-ordering, columns that exhibit high Cardinality within a partition may lead to uneven distribution of the data. For example, a few regions may contain fewer customers, while a few regions may contain more.
- Overhead during Updates: Performing updates on existing data by modifying columns can result in the restructuring of data, thereby slowing down the process.
Together, Partitioning and Z-Ordering rely on Data Layout to perform Data Optimizations.
How Liquid Clustering Comes to Rescue —
Instead of being bound by fixed data layouts, Liquid Clustering automatically adjusts the data layout based on clustering keys without the need to rewrite the data, thereby addressing the overhead Issue. Further, Liquid Clustering dynamically clusters the data based on the data patterns and avoids the partitioning problems found with Skewed distribution of the data.
Liquid Clustering will be definitely helpful in the following scenarios —
- Tables with Skewed distribution or high Cardinality Columns.
- Tables that grow quickly and require maintenance and tuning effort.
- Tables with concurrent write requirements and access patterns that change over time.
Using Liquid Clustering
Liquid Clustering can be enabled easily by the ‘Cluster by’ expression while creating the table.
CREATE TABLE table1(col0 int, col1 string) USING DELTA CLUSTER BY (col0);
We can modify the existing table and enable clustering —
ALTER TABLE table_name CLUSTER BY (new_column1, new_column2);
Liquid clustering is not compatible with Partitioning and Z-Ordering so you cannot perform clustering if the table is already partitioned.
Once the clustering is done, It can be triggered using the ‘Optimize’ command
OPTIMIZE table_name;
Liquid Clustering works on Databricks Runtime 13.3 LTS or above
[1] Databricks provides row-level concurrency for clustered tables that can reduce the number of conflicts between concurrent write operations, including OPTIMIZE, INSERT, MERGE, UPDATE, and DELETE operations.
Writing data to a clustered table —
Most operations do not automatically cluster data on write. Operations that cluster on write include the following:
INSERT INTOoperationsCTASstatementsCOPY INTOfrom Parquet formatspark.write.format("delta").mode("append")
It is not applied in the following situations —
- If a write operation exceeds 512GB of data.
- If the
SELECTsubquery contains a transformation, filter, or join. - If the projected columns are not the same as the source table.
Because not all operations apply liquid clustering, Databricks recommends frequently running OPTIMIZE to ensure that all data is efficiently clustered.
Liquid clustering is incremental, meaning that data is only rewritten as necessary to accommodate data that needs to be clustered. For tables experiencing many updates or inserts, Databricks recommends scheduling a OPTIMIZE job every one or two hours. Because liquid clustering is incremental, most OPTIMIZE jobs for clustered tables run quickly.
Selecting Clustering Keys
Databricks recommends choosing clustering keys based on commonly used query filters. Clustering keys can be defined in any order. If two columns are correlated, you only need to add one of them as a clustering key.
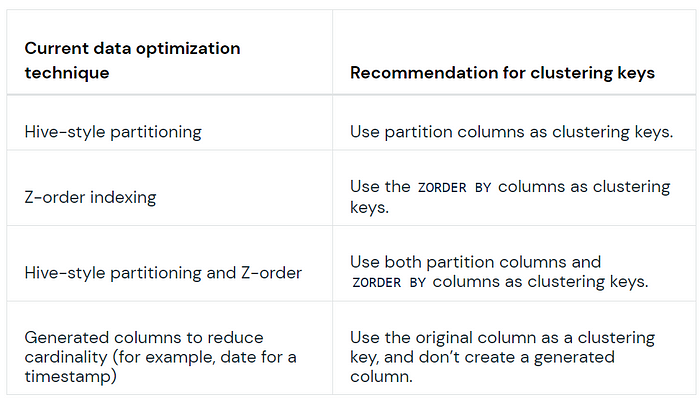
Note: We can have only 4 cluster keys for which the statistics are collected, by default first 32 columns in delta tables have their statistics collected, This number can be controlled through the table property — delta.dataSkippingNumIndexedCols. All columns with a position index less than that property value will have statistics collected.
I hope this will be helpful… If “YES” give it a try…
For most of this article, I have used https://docs.databricks.com/en/delta/clustering.html#see-how-table-is-clustered as a reference.
Happy Learning…
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")