



SQL for Data Scientists/Analysts
Last Updated on August 6, 2021 by Editorial Team
Author(s): Saniya Parveez
Introduction
SQL is an important part of data and data science for the storage and retrieval of data. With extensive data being gathered and churned out every day in the industries, as long as the data remains in a SQL-compliant database, SQL is still the ablest tool to help to investigate, filter, and aggregate data to get a thorough understanding of data.
I have seen many times that SQL is an underrated skill for data science because it has been taken for granted as a necessary yet uncool way of obtaining data out from the database to feed into pandas. People think that SQL is just SELECT, JOIN, and ORDER BY. But, it is way more than just SELECT, JOIN, and ORDER By statements.
SQL Tricks for Every Day
COALESCE() Function
This function is used to handle NULL values. It replaces NULL values with another desired value.
Let's take an Employee table:
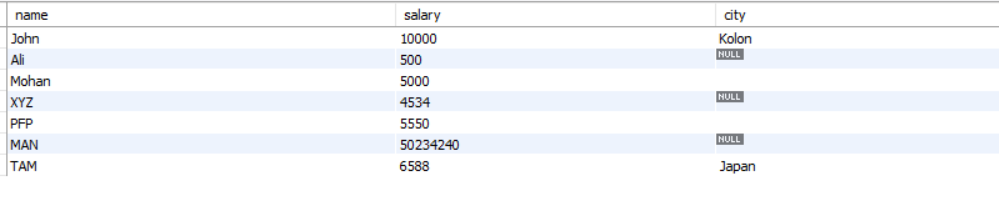
In the above table, the city row has many null values. Let’s query the Null values of the city with a default value.
SELECT name, salary, city,
COALESCE(city, 'New Delhi') AS city_null_value
FROM
Employee
ORDER BY name;

ROW_NUMBER() function
This function creates a unique incrementing integer value to each row of the result. This column of values is supposed pseudo-column as it does not naturally exist in our data table. Because of this, the result is returned in the order determined by the analysts in the ORDER BY clause.
Let’s create a rownumber in the Employee table.
SELECT
rownumber,
name,
salary,
city
FROM
(
SELECT
ROW_NUMBER() OVER (PARTITION BY city ORDER BY name DESC) AS rownumber,
tab.*
FROM Employee tab
) dat
ORDER BY name, rownumber;

WITH Statement
It is used to define “statement scoped views”. These are not stored in the database schema. It is also called Common Table Expression (CTE) and subquery factoring.
Let’s take the OrderDetail table as below:

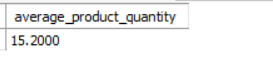
Now, query to return the average quantity ordered per ProductId.
WITH cte_quantity
AS
(SELECT
SUM(Quantity) as Total
FROM OrderDetails
GROUP BY ProductID)
SELECT
AVG(Total) average_product_quantity
FROM cte_quantity;
Output:
GROUP_CONCAT() function
It is used to concatenate data from multiple rows into one field. It returns a string with a concatenated non-NULL value from a group. It returns NULL when there are no non-NULL values.
Let’s take an example of the “Book master” table as below:

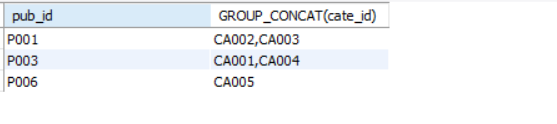
Query to return a list of comma(,) separated ‘cate_id’s for each group of ‘pub_id’.
SELECT pub_id,GROUP_CONCAT(cate_id)
FROM book_mast
GROUP BY pub_id;
Integrate SQL Query with Python
Panda is a wonderful library that gives one line code to query from SQL. Below code to query from Pandas:
query = "SELECT * FROM CURRENT_TABLE"
sql_data = pandas.read_sql(query, connection)
Conclusion
Data scientists or analysts should understand SQL. In fact, all professionals working with data and analytics should know SQL. SQL is still the most powerful tool to help you investigate, filter, and aggregate to get a thorough understanding of your data.
SQL for Data Scientists/Analysts was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





