



Sora vs. Mulholland Drive
Last Updated on February 28, 2024 by Editorial Team
Author(s): Kelvin Lu
Originally published on Towards AI.
Mulholland Drive scene
In 2001, David Lynch released one of his many masterpieces, Mulholland Drive. It’s a multi-layered, surprisingly resonant mind-boggler that explores themes of illusions, delusions, greed, jealousy, guilt, power, rotting aspirations, the mutability of identity, and Hollywood’s seamy underbelly. The movie is visually stunning and has a weird allure that attracts audiences. And even though it doesn’t have a clear narrative and nobody knows what it’s really about except for its creator, it often makes people’s “greatest of all time” lists. This is “a love story in the city of dreams,” David described.

It was the weirdest movie I have ever watched. I have to admit that, like the majority of the audience, I completely don’t understand what the story was. However, I couldn’t help but feel more and more captivated by the movie from the beginning. Eventually, when Diane pulled out the gun and shot herself, my heart was broken, and I wanted to cry out loudly. I felt like I was just waking up from a nightmare. When I woke up from a nightmare where the devil was chasing me, I would immediately feel relieved. However, I felt extremely painful, powerless, and depressed after watching Mulholland Drive. It was like the nightmare had extended into my real life.
That was strange because I have watched quite a few sad or violent movies. I’m not an emotional person. A movie has never moved me as much, especially when the story made no sense to me. I’m not sure whether someone committed suicide after watching the movie, but David Lynch is a master of manipulating people’s emotions.
When you are interested in watching the movie, be careful! You are warned!
Sora scene

OpenAI smashed the market again with their newly announced Sora project, which “is an AI model that can create realistic and imaginative scenes from text instructions.” Sora can generate high-resolution videos for up to a minute while maintaining visual quality and adherence to the user’s prompt.

Despite still not being publicly available, Sora is already creating hurricanes. The roaring development of generative AI astounded people. Many have already foreseen the Hollywood earthquake. We still have recent memories of the actors who went on strike last year over worries about being replaced by AI. In all aspects, Sora brings the filming industry a hard challenge.
This is a critical moment for the AI industry as well. According to OpenAI, “Sora serves as a foundation for models that can understand and simulate the real world, a capability we believe will be an important milestone for achieving AGI.”
Both the entertainment industry and the AI industry are curious about OpenAI’s road map towards AGI and its progression. In this article, let’s compare Sora with Mulholland Drive to see the differences between the human-produced movie and the AI-generated one. I selected Mulholland Drive due to its portrayal of fantastical elements and hallucinatory themes reminiscent of generative AI styles, a characteristic not often seen in conventional human-made films. Without a doubt, it is harder for generative AI to surpass Shakespeare than to make plausible fantasy movies.
Mechanism of Sora
OpenAI has provided the technical report for Sora. Based on the report, we can understand how Sora works, what it can do, and what its limits are. By its nature, Sora was built on top of three main concepts:
- Visual Transformer
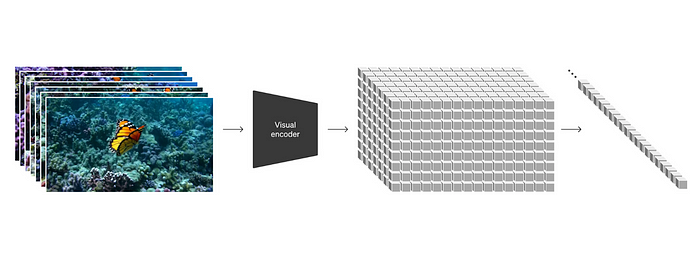
Inspired by the great success of large language models that use Transformer to learn the autoregression pattern of the language tokens, researchers started to apply transformers to computer vision tasks quite a few years ago. The idea was to divide the images into certain-sized patches, tokenize the patches, and flatten the 2-dimensional patches into a 1-dimensional array. After that preprocessing, the standard Transformer can be applied. Similar to the large language models, the visual transformers are beasts that learn from massive unlabeled data, are GPU-hungry, and produce superior performance than the previous supervised models.
The traditional visual transformer models mainly deal with static images. Sora evolved from the visual transformer models by generating videos. Instead of generating frames one by one, it generates all the frames at the same time. By doing so, it can remember the status of visual elements even when the elements are temporarily occluded. This is impossible if Sora generates video frames in sequence. Please notice how the dog stays consistent in the short video:

2. Defusion

You may already hear the name Stable-Defusion. Defusion is a type of computer vision technology that generates high-quality images from random noise.
3. Instructions following
Similar to ChatGPT, Sora can understand text prompting and can generate content by following instructions. Based on our experience with ChatGPT, we can assume that the main way to adjust the generated images would be through prompt engineering.
Gaps of Sora-generated videos
If we take human-produced movies like Mulholland Drive as the standard, we can easily identify the following issues with the Sora-created videos:
- No physical knowledge

Take a close look at the short video. In the video, each candle flame is swaying in its own direction. One of the candles even has two flames, each pointing in the opposite direction. And despite the old lady blowing, there seems to be no effect on the flames whatsoever.
That was because Sora didn’t know how to extract the physical information from the training videos. It tried its best to mimic the appearance of certain visual elements, but it had no idea of the physical rules. Sora doesn’t learn causality by itself.
This is an inherent limitation of all transformer models, including NLP transformers and visual transformers. It is impossible to switch off with the current model architecture, but it could be improved by the following methods:
- using RFHL to prevent models from making mistakes. However, this is a heavy process, requires a lot of expertise and computing resources, and can only work to fix fewer high-priority issues.
- prompt engineering. Like LLM applications, prompt engineering might be convenient for refining the generated videos in Sora. However, we’ll have to await Sora’s public release to assess its effectiveness. Potentially, we could rectify the issues using a prompt such as:
…
Ensure each candle has a single flame;
All flames should sway uniformly in one direction;
When the lady blows out the candles, her breath creates airflow causing the nearest flames to extinguish, while the flames further away sway in response.
The airflow should be sufficient to blow off the flames but not strong enough to blow away the candles or damage the cake.
…
I’m keen to find out how well Sora can understand the prompt. When the grandma got closer to the candles, her face got brighter and warmer because of the candlelight. Sora can map the visual items to the words and the actions to the visual presentations. However, whether Sora could understand the command or just repeat correlations is an interesting thing that we can only find out when we can play with Sora.
- No real-world knowledge

The puppies are another funny scene. The dogs seem to be playing near a teleport. They appear and vanish simultaneously. This is because the Sora is a next-token prediction model. Starting from the same initial status, it has problems choosing between all possible options. This is especially true when the model needs to predict multiple similar objects.
OpenAI reported that larger models made fewer mistakes than smaller models, which implies that even the larger model cannot switch off the issue, and maybe it requires an unimaginable larger model in the future to solve the problem.
The following is another interesting video. The octopus-crab fight looks impressive. If you look closer, can you notice that the crab has an unrealistic leg layout and that it looks more like a stuffed toy? Even the octopus looks like it has been cooked. It never changes colour like a live octopus does.

That exposed the fact that Sora is not learning real-world models. For example, the crab’s body structure and the octopus’ behavior in different scenarios were never learned. Sora just fills in similar visual items. It is still a statistical model that just learns the correlations. Sora will have to grow into a humongous model to remember all the sophisticated correlations and make itself look more casual, but indeed, Sora has no idea about the real world at all.
And that is why I am skeptical of Sora’s prompt-following potential. Unlike LLM, visual applications require a deeper understanding of the world. However, that is beyond Sora’s learning capability. It is more likely that prompting Sora is like talking to a parrot. Sometimes it seems like it can comprehend, but it doesn’t.
- Meaningless details
If we revisit the birthday celebration video, we can see that the people in the background are smelling, clapping, and waving hands. That is all pleasant. But wait a second! Why did the lady wave her hand? Does she express something? And why are the people clapping randomly? They are not singing Happy Birthday, they are not clapping to a song, and they are not even looking at the birthday grandma. All the details are just random. They are all mindless!
In comparison, the 2001 movie is so confusing that, in response to the urge of Mulholland Drive fans for explanations, Lynch created a promotional campaign of 10 clues. Clues included “Notice appearances of the red lampshade,” “Notice the robe, the ashtray, the coffee cup,” and “Where is Aunt Ruth?”
In human-made movies, every scene is planned, and every detail matters. There is even a Chekhov’s Gun concept that describes how every element of a story should contribute to the whole. It cited: “If you say in the first chapter that there is a rifle hanging on the wall, in the second or third chapter it absolutely must go off.”
- No story
Let’s talk about Mulholland Drive again. Although the movie has no obvious storylines and we don’t quite understand even after getting the 10 clues, we can still feel that there's a strong logical connection throughout the movie. In some sense, the whole movie becomes a maze, and people are thrilled to find out a reasonable explanation for all the puzzles.
Is Sora able to repeat the success of Mulholland Drive with its own puzzling hallucinations? I don’t think it’s possible with the current technical stack. Sora’s nature as a visual transformer model means it cannot follow a long storyline. It can only manage to keep the visual items consistent for a short period of time. The diffusion model makes Sora-generated videos filled with a lot of ‘decorative’ details. Turning those decorative details into meaningful ones is a game changer.
Human beings are strange animals. They are excited when they are challenged. However, they lose interest when they find out that the game is poorly organized. With that in mind, I don’t think Sora has any chance of making a serious movie. It can help make Avatar if we can find a way to control the randomness in the generated video. Like, let it fill up short sections between several anchor frames. It is still a helpful utility, not a revolutionary producer.
Yann LeCun said so
The following is what my favourite researcher, Yann LeCun, posted on X:

Conclusion
I’m sincerely curious about how OpenAI and other leading companies are going to advance towards AGI. In my view, the disparity between AGI and Sora is akin to comparing Elon Musk’s rocket with a firecracker. The idea is that you can’t extend your experience with a firecracker to build a heavy-duty rocket. They are completely different. While Sora represents a significant advancement in generative AI, LLM, and Transformer, its engine is running out of steam. There’s a pressing need for a breakthrough in generative AI to drive further improvement.

Last but not least, we haven’t considered the emotional factor of the generative videos. There’s nothing scarier than wasted potential, rejection, lost hope, heartbreak, and failure. And that’s what makes Mulholland Drive such a beautiful nightmare. This essence is something a machine can never truly comprehend.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

