



Ship detection on Sentinel-2 images with Mask R-CNN model
Last Updated on November 29, 2021 by Editorial Team
Author(s): Andrea C.
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Deep Learning
Ship Detection on Sentinel-2 Images with Mask R-CNN Model
A time analysis of maritime traffic using PyTorch and open data
As part of a larger ML project, we decided to explore the possibility to assess maritime traffic using publicly available satellite images. In particular, our goal was to estimate a time series that is representative of the volume of the maritime traffic observed over time in a given region. In this article, we discuss the methodology and results obtained.
Note: all code discussed in the following is available on my personal GitHub at https://github.com/andrea-ci/s2-ship-detection.
Why satellite data

Satellite’s gone up to the skies
Things like that drive me out of my mind
I watched it for a little while
I like to watch things on TV
Lou Reed, “Satellite of love”
In the last years, remote sensing has dramatically evolved and so have other fields such as computer vision and machine learning. In addition, more and more satellite imagery has become publicly available. Notable examples include Landsat and Sentinel-2 constellation imagery.
Satellites exhibit three fundamental advantages for the users:
- they allow access to information that is often difficult to obtain by other means;
- they provide a global geographic coverage;
- they collect information periodically and with high temporal resolution (the so-called revisit period).
Moreover, the spatial resolution of images, i.e. the ability to differentiate two close objects, is constantly increasing, thus enabling more and more new applications. A famous example is given by market research firms [1] that recently have exploited satellite imagery to count cars in parking, in order to estimate retail demand. In principle, similar methods can be used also for applications with social and administrative purposes, such as measuring urban traffic or counting crowds at political rallies.
Sentinel-2 mission
In this experiment, we consider the ESA Sentinel-2 mission. Sentinel-2 satellites are equipped with a Multi-Spectral Instrument (MSI) that collects data using 13 bands at 3 different resolutions: 10, 20, and 60 meters. In order to have the best available resolution, we have worked with B02, B03, and B04 bands, which are located in the visible spectrum and provide a resolution of 10 meters.
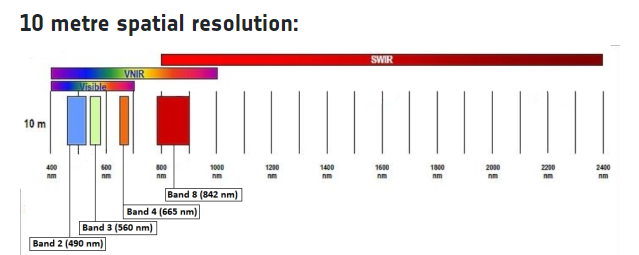
Sentinel-2 images can be accessed in different ways, including:
- Copernicus Open Access Hub, a website from ESA which provides free and open access to Sentinel-1, Sentinel-2, Sentinel-3, and Sentinel-5P user products;
- the Registry of Open Data, from Amazon AWS;
- Sentinel HUB, a Cloud API for satellite imagery for which also a convenient Python library, sentinelhub, is available.
Modeling approach
Detecting ships on images is a hard task because by construction the number of positive samples (i.e. pixels belonging to a ship) is extremely small compared to the number of negative ones. Thus, instead of attempting a semantic classification task, I chose to go for an object detection approach.
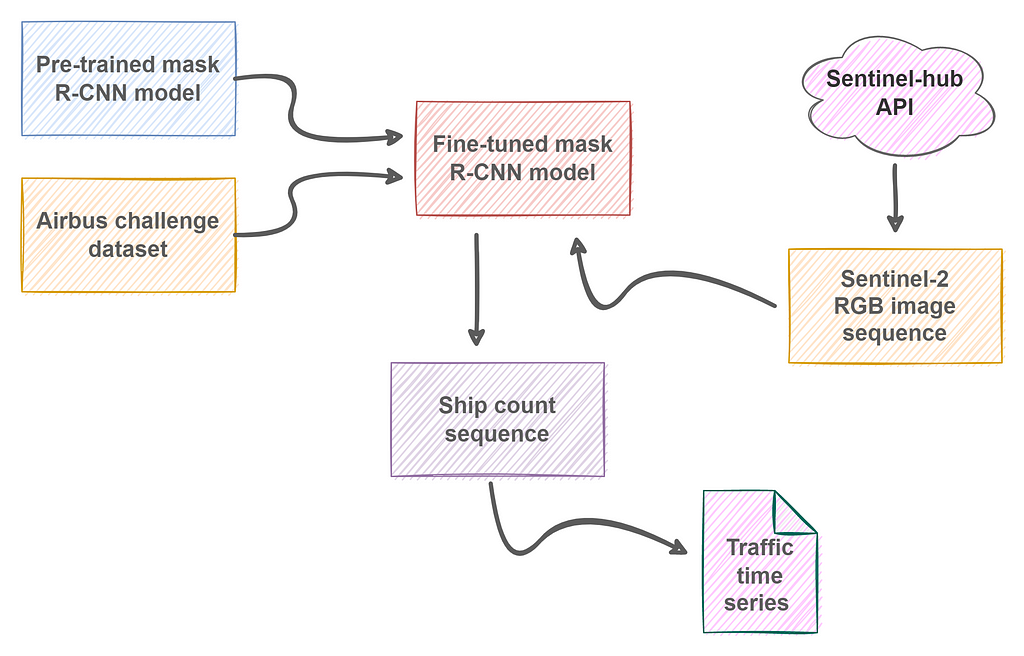
As a baseline, a pre-trained Mask R-CNN model has been considered. This model adds an extra branch to the Faster R-CNN model, which in turn is based on the architecture of Resnet, introduced in “Deep Residual Learning for Image Recognition”.
Resnet stands for Residual Network as this network introduces the concept of residual learning. Residual learning is an approach that aims to improve the performance of deep convolutional neural networks for classification and recognition tasks. Generally speaking, deep networks learn features at a low, middle, and high level through their layers. Residual networks learn instead the residuals, i.e. the difference between features, by using shortcut connections between layers. This approach has proven to make easier training, getting better accuracy values. Resnet models come in 5 variants, containing 18, 34, 50, 101, and 152 layers respectively.
For the deep learning implementation, I have used PyTorch with the Mask R-CNN model provided by TorchVision. It comes with 50 layers and is pre-trained on COCO dataset.
Now it’s time to finetune the model.
Model finetuning: data and training
For fine-tuning the model, I have used competition data from Kaggle Airbus Ship Detection Challenge.
This dataset is composed of 192556 images, of which only 42556 contain at least one ship (22% of the total). Moreover, most of them (around 60%) contain exactly one ship. Thus, the dataset is highly unbalanced and the number of positive samples is quite limited.
To make things harder, ships contained in the images can differ significantly in size and they can be located in the open sea or at docks and marinas, e.g. adjacent to the land.
Dataset comes with a CSV file where ship masks are represented by run-length encoding. Since most of the images do not contain any ships, I remove them from the dataset. For the remaining ones, masks are generated so they can be used for the creation of the model targets.
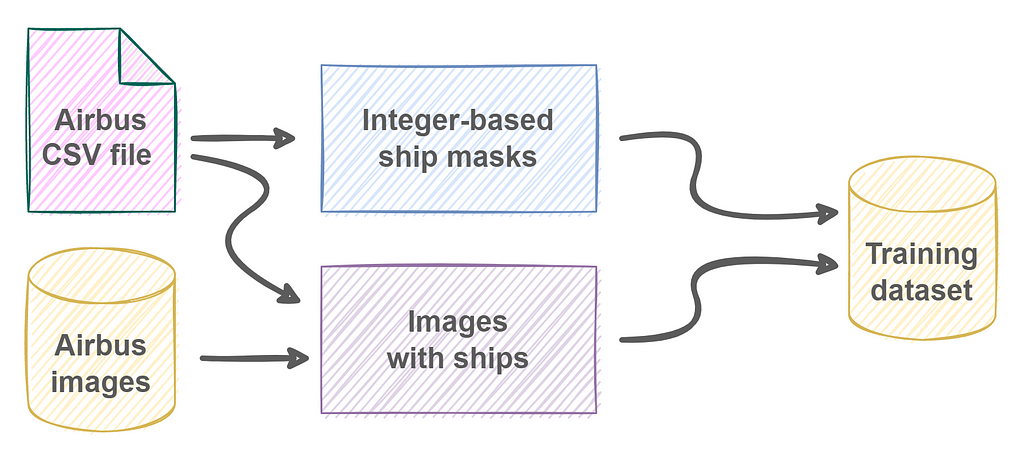
Masks are integer-based 2D arrays, meaning that for any pixel x:
- x=0, if it does not represent a ship;
- x=1, if it is part of the first ship;
- x=2, if it is part of the second ship;
- and so on.
Pixel numbering is needed to identify any eventual ship included in the image because the model returns objects (ships) and each object is characterized by a unique bounding box.
So, following the excellent tutorial provided by TorchVision I have prepared the code for the Airbus dataset as shown in the next snippet.
class AirbusShipDetection(Dataset):
def __init__(self, image_ids, dir_images, dir_masks, transforms = None):
self.image_ids = image_ids
self.dir_images = dir_images
self.dir_masks = dir_masks
self._transforms = transforms
def __getitem__(self, idx):
# Read the RGB image.
fn_image = f'{self.image_ids[idx]}.jpg'
path_image = path.join(self.dir_images, fn_image)
image = Image.open(path_image).convert("RGB")
# Read the integer-based mask.
fn_mask = f'{self.image_ids[idx]}_mask.png'
path_mask = path.join(self.dir_masks, fn_mask)
mask = np.array(Image.open(path_mask))
# Instances are encoded with different integers.
obj_ids = np.unique(mask)
# We remove the background (id=0) from the mask.
obj_ids = obj_ids[1:]
num_objs = len(obj_ids)
# Split the mask into a set of binary masks
# masks.shape[0] = number of istances
masks = mask == obj_ids[:, None, None]
# Get bounding box of each mask.
boxes = []
for mask in masks:
pos = np.where(mask)
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
# Enforce a positive area.
if xmax - xmin < 1:
xmax += 1
if ymax - ymin < 1:
ymax += 1
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype = torch.float32)
# Compute the area.
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# Only one class (ships).
labels = torch.ones((num_objs,), dtype = torch.int64)
masks = torch.as_tensor(masks, dtype = torch.uint8)
# Crowd flag not applicable here.
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
image_id = torch.tensor([idx])
target = {}
target['boxes'] = boxes
target['labels'] = labels
target['masks'] = masks
target['image_id'] = image_id
target['area'] = area
target['iscrowd'] = iscrowd
# Apply image augmentation.
if self._transforms:
image, target = self._transforms(image, target)
return image, target
def __len__(self):
# return length of
return len(self.image_ids)
The structure of the model output is clearly visible here: it consists of a dictionary with the information related to the object(s) detected by the model.
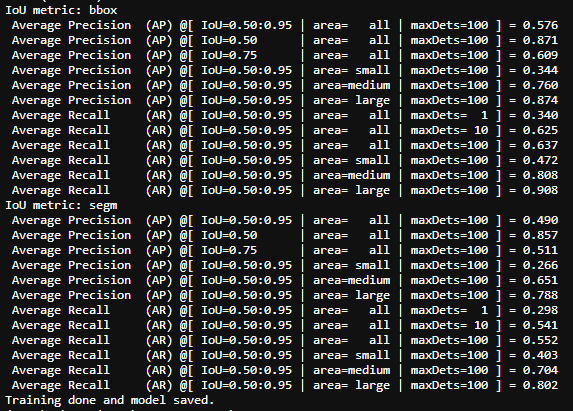
After 10 training epochs, evaluation metrics exhibit acceptable values so that training can be terminated and a model is finally ready to be applied on Sentinel-2 images.
Inference on Sentinel-2 data
For the experiment, I have focused on a small area surrounding the port of the city of Olbia, in Sardinia (Italy). This port is one of the main access points to the island for ferries coming from the Italian peninsula, especially during summer vacations.
A period included between 2017 and 2020 has been considered and two images have been acquired, at regular time intervals, for each month. As a result, the model input is composed of a sequence of 96 raw RGB images. Unfortunately, some of them resulted malformed, either because of API issues during the download or because they didn’t pass the quality checks of the Sentinel-2 processing chain so that they must be discarded.
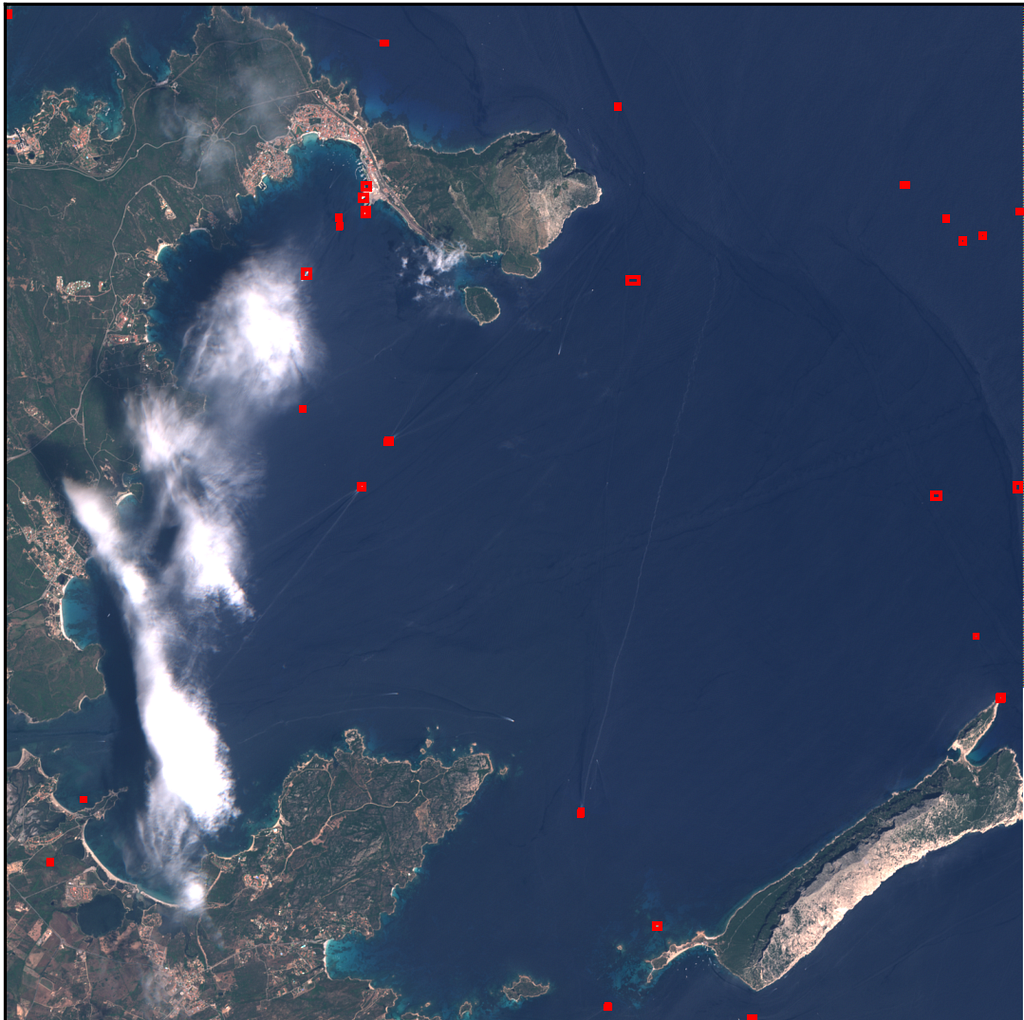
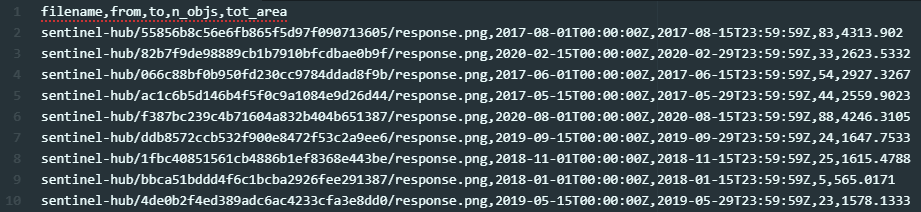
The sequence of images is processed by the model and detection results are saved to a CSV file: for each image, acquisition date and number of detected ships detected are reported. Also, the total area occupied by ships is included, although it is not used for this analysis.
Analysis of results
Using Pandas it is easy to extract and visualize the time series from the CSV file. The counts reported in the file are averaged on a monthly basis so to obtain a time series of vessels observed daily in the reference month.
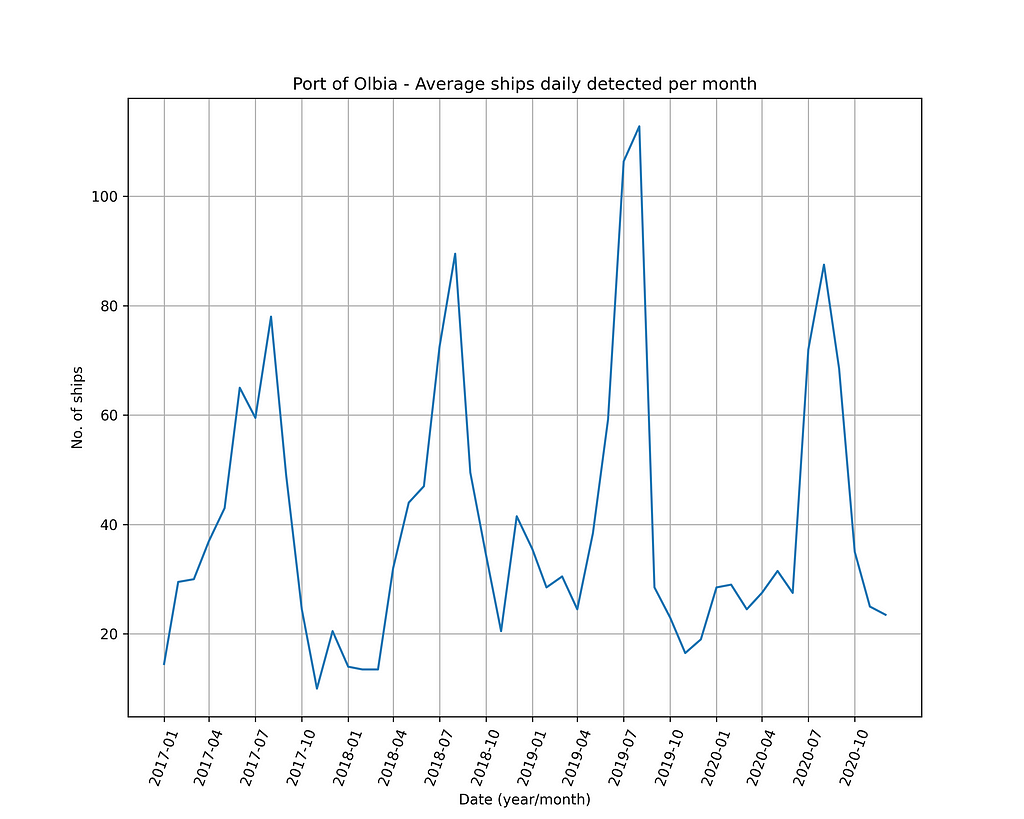
The time series shows a strong seasonality. Most likely this behavior is due to a couple of different reasons:
- activities of the port are mainly of touristic type and the flow of tourists is larger in the summer;
- conditions of weather in summer favor the acquisition of cleaner images (i.e. with low cloudiness), thus allowing a larger number of ships to be correctly detected.
Both of these factors lead to maximum traffic volumes in the summer, which then gradually decrease until they reach minimum values during the winter.
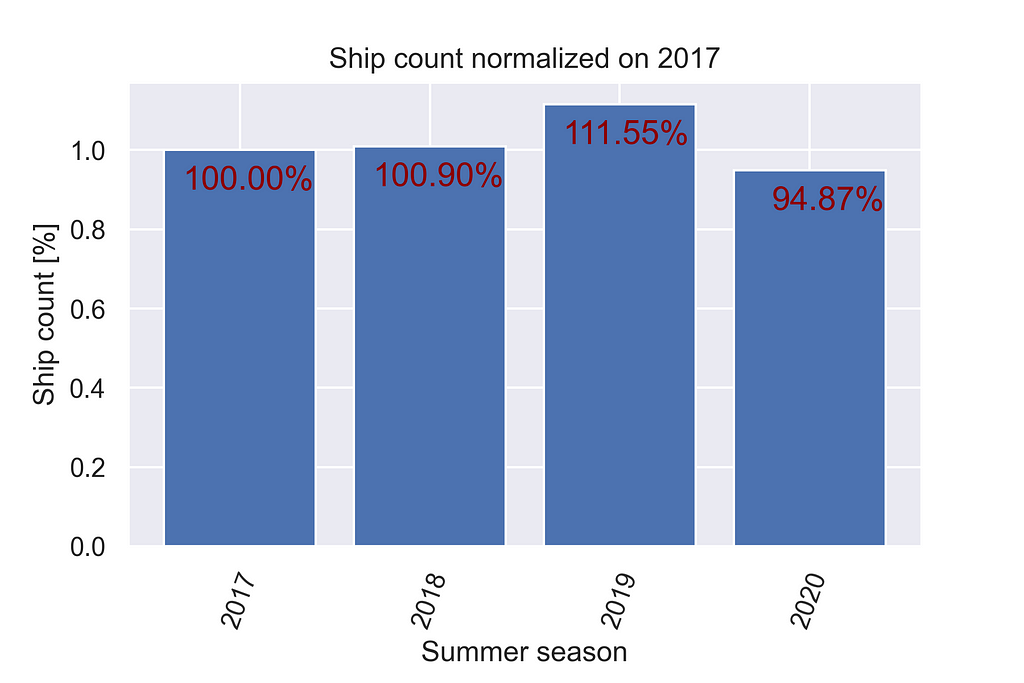
According to a local newspaper [2], in the summer season of 2020 port of Olbia has recorded a reduction in traffic of about 15% with the respect to 2019, due to pandemic restrictions that affected the whole country.
Considering the aggregated sum of the counts obtained during the summer season (i.e. between April and September, both inclusive), data obtained are consistent with this statement as they indicate a traffic reduction of about 16.28% in 2020.
Conclusions
Satellite images in the visible spectrum are highly sensitive to weather conditions and their usage must be carefully evaluated based on the specific project requirements (e.g. region of interest, revisit period, image resolution). However, their application to extract a proxy measure for maritime activities appears, in principle, to be possible.
References
[1] https://internationalbanker.com/brokerage/how-satellite-imagery-is-helping-hedge-funds-outperform/
[3] https://sentinel.esa.int/web/sentinel/missions/sentinel-2
[4] https://scihub.copernicus.eu/
[5] https://sentinelhub-py.readthedocs.io/en/latest/index.html
[6] https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html
[7] https://www.kaggle.com/c/airbus-ship-detection
Ship detection on Sentinel-2 images with Mask R-CNN model was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

