



Shadow Deployment of ML Models With Amazon SageMaker
Last Updated on July 17, 2023 by Editorial Team
Author(s): Vinayak Shanawad
Originally published on Towards AI.
Validate the performance of new ML models by comparing them to production models with Amazon SageMaker shadow testing
AWS has announced the shadow model deployment strategy support in Amazon SageMaker in AWS re:Invent 2022. Shadow testing helps us to minimize the risk of deploying a low-performing model, minimize the downtime and monitor the model performance of the new model version for some time and can roll back if there is an issue with the new version.
Shadow testing features
U+2705 Run multiple model versions in parallel with one serving live traffic.
U+2705 Validate the new model version (shadow variant) without impact.
U+2705 Production variant accepts the request and serves the prediction response.
U+2705 Shadow variant will accept a user-defined portion of the requests. If required, we can capture the response of the shadow variant in S3, but it will not serve prediction responses to consumers.
Once we are comfortable with the shadow variant, then we can promote that shadow variant as a Production variant and serve predictions from that model.
Note: Some of us might be using the Canary deployment process, but the disadvantage of canary deployment is there might be the risk of serving a low-performing model to a small user group for a shorter period of time.
Shadow or challenger deployment use cases
- Evaluate the model performance metrics such as model latency, overhead latency, model errors, invocation 5xx errors, etc.
- Evaluate the model evaluation metrics such as accuracy, f1 score, precision, recall, MSE, etc.
- Evaluate the changes to model-serving infrastructure, like installing new dependencies, upgrading the model-serving framework and container versions, etc.
If the new or updated model performs better than the existing production model wrt the above use cases, then we can promote a new model as a production model.
In AWS re:Invent 2022, they demonstrated the capabilities of shadow testing by using the SageMaker console and SageMaker inference APIs for the first use case. We often improve the existing production models by collecting feedback from customers, retraining a model with new samples of data, or making use of model monitoring (model and data drift) components. So I would like to demonstrate how we can utilize the shadow testing feature in the second use case.
In my previous post, I discussed how to fine-tune a HuggingFace BERT model on the disaster tweets classification dataset using on-demand and spot instances, deploy that model on a real-time endpoint, and update that endpoint.
Let’s deploy a HuggingFace BERT model as a Production variant that is fine-tuned with two epochs and consider a shadow variant that is fine-tuned with three epochs.
Prepare model artifacts
# Fine-tuned with 2 epochs
model_v1_path = "s3://sagemaker-xx-xxxx-x-xxxxxxxxxxxx/sagemaker/social-media/models/model_v1/model_v1.tar.gz"
# Fine-tuned with 3 epochs
model_v2_path = "s3://sagemaker-xx-xxxx-x-xxxxxxxxxxxx/sagemaker/social-media/models/model_v2/model_v2.tar.gz"
Deploy tweet-classifier-v1 model (as production variant)
tweet_cls_v1_model_name = name_with_timestamp('tweet-classifier-v1-model')
tweet_cls_v1_epc_name = name_with_timestamp('tweet-classifier-v1-epc')
tweet_cls_endpoint_name = name_with_timestamp('tweet-classifier-ep')
production_variant_name = "production"
# Create a tweet-classifier-v1 model as production variant
from sagemaker import get_execution_role
image_uri = sagemaker.image_uris.retrieve(framework="pytorch", region=region, py_version="py38", image_scope="inference", version="1.9", instance_type="ml.m5.xlarge")
primary_container = {'Image': image_uri, 'ModelDataUrl': model_v1_path,
'Environment': {
'SAGEMAKER_PROGRAM': 'train_deploy.py',
'SAGEMAKER_REGION': region,
'SAGEMAKER_SUBMIT_DIRECTORY': model_v1_path
}
}
create_model_response = sm_boto3.create_model(ModelName = tweet_cls_v1_model_name, ExecutionRoleArn = get_execution_role(), PrimaryContainer = primary_container)
print('ModelArn= {}'.format(create_model_response['ModelArn']))
# Create an endpoint config
endpoint_config_response = sm_boto3.create_endpoint_config(EndpointConfigName = tweet_cls_v1_epc_name,
ProductionVariants=[
{
'InstanceType':'ml.m5.xlarge',
'InitialInstanceCount':1,
'ModelName':tweet_cls_v1_model_name,
'VariantName':production_variant_name,
'InitialVariantWeight':1
}
])
print('Endpoint configuration arn: {}'.format(endpoint_config_response['EndpointConfigArn']))
# Create an endpoint
endpoint_params = {'EndpointName': tweet_cls_endpoint_name, 'EndpointConfigName': tweet_cls_v1_epc_name}
endpoint_response = sm_boto3.create_endpoint(EndpointName=tweet_cls_endpoint_name, EndpointConfigName=tweet_cls_v1_epc_name)
print('EndpointArn = {}'.format(endpoint_response['EndpointArn']))
Get predictions from the tweet-classifier-v1 model
import boto3
import json
sm = boto3.client('sagemaker-runtime')
payload = ["Just witnessed a beautiful sunset on my evening walk. Sometimes it's the little things that can make our day. #sunset #beauty"]
payload = json.dumps(payload)
response = sm.invoke_endpoint(EndpointName=tweet_cls_endpoint_name, Body=payload, ContentType='application/json')
result = json.loads(response['Body'].read())
print(result)
{'prob_score': '0.7350', 'label': 'Not a disaster'}
Deploy tweet-classifier-v2 model (as shadow variant)
Let’s deploy a tweet-classifier-v2 model as a shadow variant which is fine-tuned with three epochs.
We capture the 100% request and the response of both production and shadow variants using Data Capture options by providing S3 URI. As per the settings below, SageMaker routes the 50% (InitialVariantWeight=0.5) copy of the inference requests received by the production variant to the shadow variant.
tweet_cls_v2_model_name = name_with_timestamp('tweet-classifier-v2-model')
tweet_cls_v2_shadow_epc_name = name_with_timestamp('tweet-classifier-v2-shadow-epc')
shadow_variant_name = "shadow"
# Create a tweet-classifier-v2 model as shadow variant
primary_container = {'Image': image_uri, 'ModelDataUrl': model_v2_path,
'Environment': {
'SAGEMAKER_PROGRAM': 'train_deploy.py',
'SAGEMAKER_REGION': region,
'SAGEMAKER_SUBMIT_DIRECTORY': model_v2_path
}
}
create_model_response = sm_boto3.create_model(ModelName = tweet_cls_v2_model_name, ExecutionRoleArn = get_execution_role(), PrimaryContainer = primary_container)
print('ModelArn= {}'.format(create_model_response['ModelArn']))
# Create an endpoint config with production and shadow variants
data_capture_prefix = "sagemaker/social-media/models"
endpoint_config_response = sm_boto3.create_endpoint_config(
EndpointConfigName = tweet_cls_v2_shadow_epc_name,
ProductionVariants=[
{
'InstanceType':'ml.m5.xlarge',
'InitialInstanceCount':1,
'ModelName':tweet_cls_v1_model_name,
'VariantName':production_variant_name,
'InitialVariantWeight':1
}
],
# Type: Array of ShadowProductionVariants
ShadowProductionVariants = [
{
"ModelName": tweet_cls_v2_model_name,
'VariantName':shadow_variant_name,
"InitialInstanceCount": 1,
"InitialVariantWeight": 0.5,
"InstanceType": "ml.m5.xlarge"
}
],
DataCaptureConfig={
'EnableCapture': True,
'InitialSamplingPercentage': 100,
'DestinationS3Uri': "s3://{}/{}".format(bucket, data_capture_prefix),
'CaptureOptions': [{'CaptureMode': 'Input'}, {'CaptureMode': 'Output'}],
'CaptureContentTypeHeader': {'JsonContentTypes': ['application/json']}
})
print('Endpoint configuration arn: {}'.format(endpoint_config_response['EndpointConfigArn']))
# Update an endpoint with shadow endpoint config
endpoint_params = {'EndpointName': tweet_cls_endpoint_name, 'EndpointConfigName': tweet_cls_v2_shadow_epc_name}
endpoint_response = sm_boto3.update_endpoint(EndpointName=tweet_cls_endpoint_name, EndpointConfigName=tweet_cls_v2_shadow_epc_name)
print('EndpointArn = {}'.format(endpoint_response['EndpointArn']))
Verify the production and shadow variants settings in the AWS console.

Get predictions from the tweet-classifier-v2 model
input = [
"Exciting news! Our team has just launched a new product that is going to change the game in the industry. Stay tuned for more details. #innovation #success",
"Happy to announce that we've hit a new milestone - 1 million followers on our social media page! Thank you all for your support. #milestone #grateful",
"Just witnessed a beautiful sunset on my evening walk. Sometimes it's the little things that can make our day. #sunset #beauty",
"The new Star Wars movie is finally out and it's amazing! So much action and plot twists, a must see for any fan. #StarWars #MovieNight",
"Just finished a great book, definitely recommend it to anyone who loves a good thriller. Can't wait to start the next one. #bookrecommendation #reading",
"Devastating wildfires continue to ravage the western United States, with thousands of acres burned and entire communities forced to evacuate. #wildfire #disaster",
"Hurricane Maria makes landfall in Puerto Rico, causing widespread damage and power outages. Our thoughts are with those affected. #hurricane #disaster",
"Breaking news: a major earthquake strikes the central coast of Chile, measuring 8.3 on the Richter scale. #earthquake #disaster",
"Flash floods hit the midwest, leaving several towns underwater and causing significant damage to infrastructure. #flood #disaster",
"Tropical Storm Eta causes widespread flooding and landslides in Central America, leaving many dead and missing. #tropicalstorm #disaster"
]
sm = boto3.client('sagemaker-runtime')
for i in range(len(input)):
payload = json.dumps(input[i])
response = sm.invoke_endpoint(EndpointName=tweet_cls_endpoint_name, Body=payload, ContentType='application/json')
result = json.loads(response['Body'].read())
print(result)
{'prob_score': '0.8252', 'label': 'Not a disaster'}
{'prob_score': '0.8272', 'label': 'Not a disaster'}
{'prob_score': '0.7350', 'label': 'Not a disaster'}
{'prob_score': '0.8160', 'label': 'Not a disaster'}
{'prob_score': '0.8111', 'label': 'Not a disaster'}
{'prob_score': '0.8492', 'label': 'Real disaster'}
{'prob_score': '0.8494', 'label': 'Real disaster'}
{'prob_score': '0.8465', 'label': 'Real disaster'}
{'prob_score': '0.8507', 'label': 'Real disaster'}
{'prob_score': '0.8502', 'label': 'Real disaster'}
View production variant captured data from S3
Note: It takes a few minutes for the capture data to appear in S3.
# View Production variant captured data
import boto3
s3_client = boto3.Session().client('s3')
current_endpoint_capture_prefix = "{}/{}/{}".format(data_capture_prefix, tweet_cls_endpoint_name, production_variant_name)
result = s3_client.list_objects(Bucket=bucket, Prefix=current_endpoint_capture_prefix)
prod_var_capture_files = [capture_file.get("Key") for capture_file in result.get("Contents")]
def get_obj_body(obj_key):
return s3_client.get_object(Bucket=bucket, Key=obj_key).get('Body').read().decode("utf-8")
prod_var_capture_file = get_obj_body(prod_var_capture_files[-1])
# Print prouduction variant captured request and response
print(json.dumps(json.loads(prod_var_capture_file.split('\n')[0]), indent=2))
{
"captureData": {
"endpointInput": {
"observedContentType": "application/json",
"mode": "INPUT",
"data": "\"Exciting news! Our team has just launched a new product that is going to change the game in the industry. Stay tuned for more details. #innovation #success\"",
"encoding": "JSON"
},
"endpointOutput": {
"observedContentType": "application/json",
"mode": "OUTPUT",
"data": "{\"prob_score\": \"0.8252\", \"label\": \"Not a disaster\"}",
"encoding": "JSON"
}
},
"eventMetadata": {
"eventId": "9d66e263-19cd-40e9-ad08-40cb5d1026ef",
"inferenceTime": "2023-01-29T13:27:55Z"
},
"eventVersion": "0"
}
Notice that SageMaker generates an eventId for each invocation which helps in analysis.
Let’s convert the production variant captured data into a pandas data frame.
# Convert the production variant captured data into pandas dataframe
prod_input_list = []
for i in range(len(prod_var_capture_file.split('\n'))):
if not len(prod_var_capture_file.split('\n')[i]) == 0:
prod_input = {}
prod_input["input"] = json.loads(prod_var_capture_file.split('\n')[i])["captureData"]["endpointInput"]["data"]
data = json.loads(json.loads(prod_var_capture_file.split('\n')[i])["captureData"]["endpointOutput"]["data"])
prod_input["prod_output"] = data["label"]
prod_input["prod_prob_score"] = float(data["prob_score"])
prod_input["eventId"] = json.loads(prod_var_capture_file.split('\n')[i])["eventMetadata"]["eventId"]
prod_input_list.append(prod_input)
from pandas import json_normalize
prod_var_df = json_normalize(prod_input_list)
prod_var_df

View shadow variant captured data from S3
# View Shadow variant captured data
current_endpoint_capture_prefix = "{}/{}/{}".format(data_capture_prefix, tweet_cls_endpoint_name, shadow_variant_name)
result = s3_client.list_objects(Bucket=bucket, Prefix=current_endpoint_capture_prefix)
shadow_var_capture_files = [capture_file.get("Key") for capture_file in result.get("Contents")]
def get_obj_body(obj_key):
return s3_client.get_object(Bucket=bucket, Key=obj_key).get('Body').read().decode("utf-8")
shadow_var_capture_file = get_obj_body(shadow_var_capture_files[-1])
# Print shadow variant captured request and response
print(json.dumps(json.loads(shadow_var_capture_file.split('\n')[0]), indent=2))
{
"captureData": {
"endpointInput": {
"observedContentType": "application/json",
"mode": "INPUT",
"data": "\"Happy to announce that we've hit a new milestone - 1 million followers on our social media page! Thank you all for your support. #milestone #grateful\"",
"encoding": "JSON"
},
"endpointOutput": {
"observedContentType": "application/json",
"mode": "OUTPUT",
"data": "{\"prob_score\": \"0.8586\", \"label\": \"Not a disaster\"}",
"encoding": "JSON"
}
},
"eventMetadata": {
"eventId": "95512f59-6bf9-4e0f-a337-968429d92bd3",
"invocationSource": "ShadowExperiment",
"inferenceTime": "2023-01-29T13:27:56Z"
},
"eventVersion": "0"
}
Notice that SageMaker generates an eventId and capture invocationSource as ShadowExperiment which helps in identifying the captured data from the shadow variant and production variant.
# Convert the shadow variant captured data into pandas dataframe
shadow_input_list = []
for i in range(len(shadow_var_capture_file.split('\n'))):
if not len(shadow_var_capture_file.split('\n')[i]) == 0:
shadow_input = {}
data = json.loads(json.loads(shadow_var_capture_file.split('\n')[i])["captureData"]["endpointOutput"]["data"])
shadow_input["shadow_output"] = data["label"]
shadow_input["shadow_prob_score"] = float(data["prob_score"])
shadow_input["eventId"] = json.loads(shadow_var_capture_file.split('\n')[i])["eventMetadata"]["eventId"]
shadow_input_list.append(shadow_input)
shadow_var_df = json_normalize(shadow_input_list)

Compare the model evaluation metrics
Captured data will help us in Model monitoring, like detecting data and model drifts. There are a lot of ways in which we can gain insights from captured data.
Let’s compare the probability scores from both production and shadow variants and check if the shadow variant results are better than the Production variant or not.
import pandas as pd
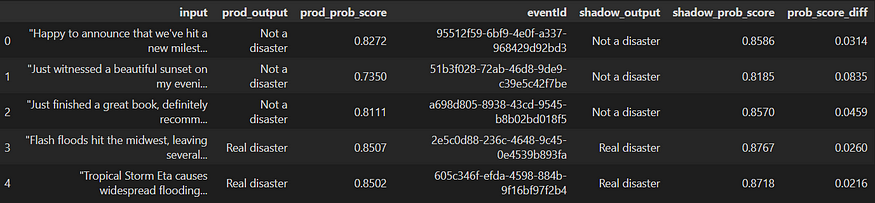
final_df = pd.merge(prod_var_df, shadow_var_df, on='eventId', how='right')
final_df = final_df.assign(prob_score_diff=final_df['shadow_prob_score'] - final_df['prod_prob_score'])
final_df
import matplotlib.pyplot as plt
import seaborn as sns
sns.pointplot(
x=final_df.index,
y=final_df.prob_score_diff,
data=final_df);
plt.show()

We can observe that the shadow variant (BERT model fine-tuned with 3 epochs) results are better than the existing Production variant (BERT model fine-tuned with 2 epochs); hence we can promote the shadow variant as a production variant.
Note: We can also leverage the Canary deployment strategy even after completing the shadow testing.
Promote the shadow variant as a production variant
tweet_cls_v2_prod_epc_name = name_with_timestamp('tweet-classifier-v2-prod-epc')
# Create an endpoint config with production variant
endpoint_config_response = sm_boto3.create_endpoint_config(
EndpointConfigName = tweet_cls_v2_prod_epc_name,
ProductionVariants=[
{
'InstanceType':'ml.m5.xlarge',
'InitialInstanceCount':1,
'ModelName':tweet_cls_v2_model_name,
'VariantName':production_variant_name,
'InitialVariantWeight':1
}
])
print('Endpoint configuration arn: {}'.format(endpoint_config_response['EndpointConfigArn']))
# Update an endpoint with production endpoint config
endpoint_params = {'EndpointName': tweet_cls_endpoint_name, 'EndpointConfigName': tweet_cls_v2_prod_epc_name}
endpoint_response = sm_boto3.update_endpoint(**endpoint_params)
Clean up
sm_boto3.delete_endpoint(EndpointName=tweet_cls_endpoint_name)
sm_boto3.delete_endpoint_config(EndpointConfigName=tweet_cls_v1_epc_name)
sm_boto3.delete_endpoint_config(EndpointConfigName=tweet_cls_v2_shadow_epc_name)
sm_boto3.delete_endpoint_config(EndpointConfigName=tweet_cls_v2_prod_epc_name)
sm_boto3.delete_model(ModelName=tweet_cls_v1_model_name)
sm_boto3.delete_model(ModelName=tweet_cls_v2_model_name)
References
- Introducing Amazon SageMaker support for shadow testing
- Minimize the production impact of ML model updates with Amazon SageMaker shadow testing
Acknowledgments
Special thanks to the AWS SageMaker team (Raghu Ramesha, Qiyun Zhao, Qingwei Li, and Tarun Sairam) for their contribution to introducing the SageMaker support for shadow testing.
Thanks for reading!! If you have any questions, feel free to contact me.
The complete source code for this post is available in the GitHub repo
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

