



Self-Supervised Learning
Last Updated on November 3, 2021 by Editorial Team
Author(s): Adeel
Machine Learning
Predict everything from everything else
Machine learning is broadly divided into supervised, unsupervised, semi-supervised, and reinforcement learning problems. Machine learning has enjoyed the majority of success by tackling supervised learning problems. The data in supervised learning tasks are labeled and hence provide more performance enhancement opportunities for the state-of-the-art models.
Deep learning via supervised learning has also achieved a tremendous amount of success in recent times. From image classification to language translation, their performance has been improving. However, collecting large labeled datasets is expensive and impossible in several domains such as medical datasets for rare diseases. These types of datasets provide ample opportunities for self-supervised algorithms to further improve the performance of the predictive model.
Self-supervised learning aims to learn information representation from unlabeled data. Usually, in this case, the labeled data set is relatively small than the unlabeled data set. Self-supervised learning uses this unlabeled data and performs pretext tasks and contrastive learning.
In an excellent post on self-supervised learning, Jeremey Howard defines supervised learning into two phases: “the task that we use for pretraining is known as the pretext task. The tasks that we then use for fine-tuning are known as the downstream tasks”. Examples of self-supervised learning include future word prediction, masked word prediction inpainting, colorization, and super-resolution.
Self-supervised learning for Computer Vision
Self-supervised learning methods rely on the spatial and semantic structure of data. For images, spatial structures learning is extremely important. Different techniques including rotation, jigsaw puzzle, and colorization are utilized as pretext tasks for learning representation from images. For colorization, a grayscale photograph is given as an input and a color version of the photograph is generated. The paper by Zhang et al. [1] explains the colorization process that produces vibrant and realistic colorizations.

Another method that is widely used for self-supervised learning for computer vision is placing image patches. An example of that includes the paper by Doersch et al. [2]. In this work, a large unlabeled image data set is provided and random pairs of patches are extracted from it. After the initial step, a convolutional neural net predicts the position of the second patch relative to the first. Figure 2 illustrates the process.
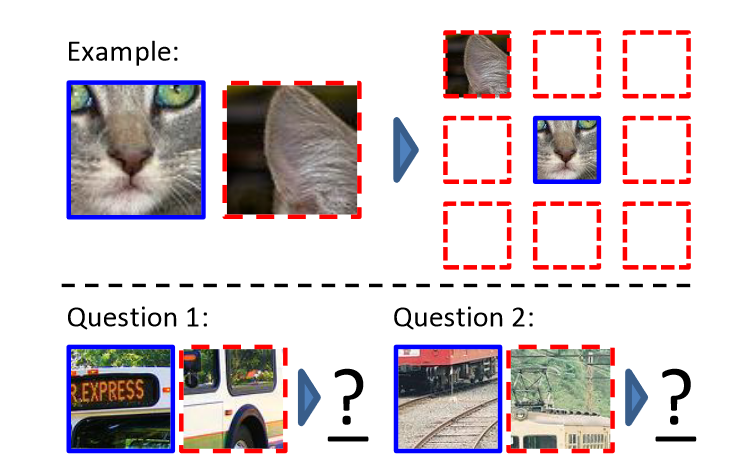
There are different other methods used for self-supervised learning including inpainting and classifying corrupted images. If you are interested in this topic, please check the reference [3]. It provides a literature review on the mentioned topic.
Self-supervised learning for Natural Language Processing
Self-supervised learning methods have been the most common in the case of natural language processing tasks. The “Continuous Bag of Words” approach of the Word2Vec paper is the most famous example of self-supervised learning.
Similarly, there are other different methods used for self-supervised learning including Neighbor Word Prediction, Neighbor Sentence Prediction, Auto-regressive Language Modeling, and Masked Language Modeling. The masked language modeling formulation has been used in the BERT, RoBERTa and ALBERT papers. In this task, a small subset of masked words is predicted.
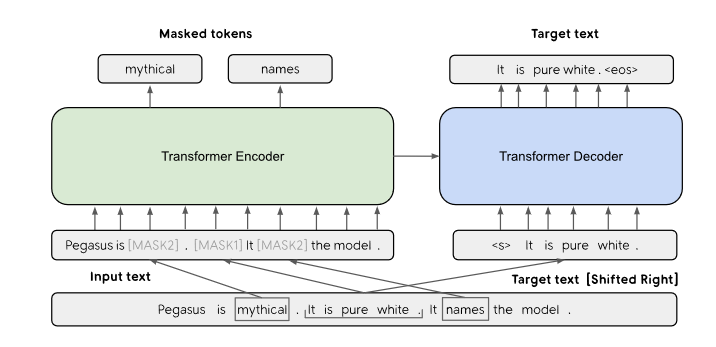
The latest example of self-supervised learning for text includes the paper by Zhang et al. [4]. The authors proposed a gap-sentence generation mechanism. This mechanism was used for the downstream task of summarizing the abstract.
A very interesting blog on this topic has been written by Liu. Please read it for more insights.
Self-supervised learning for Tabular Data
The self-supervised learning on images and text has been progressive. However, the existing self-supervised methods are not effective for tabular data. The tabular data has no underline spatial or semantic structure and hence the existing techniques relying on spatial and semantic structures are not useful.
Most of the tabular data involve categorical features and these features do not possess meaningful convex combinations. Even for continuous variables, there is no guarantee that the data manifold is convex. The challenge produces a novel research direction for researchers. I will briefly explain some of the work done in this area.
Work done by Vincent et al. [5] proposes a mechanism of de-noising auto-encoders. The pretext task is to recover the original sample from a corrupted sample. In another paper, Pathak et al. [6] proposed a context encoder, the pretext task is to reconstruct the original sample from both the corrupted sample and mask vector.
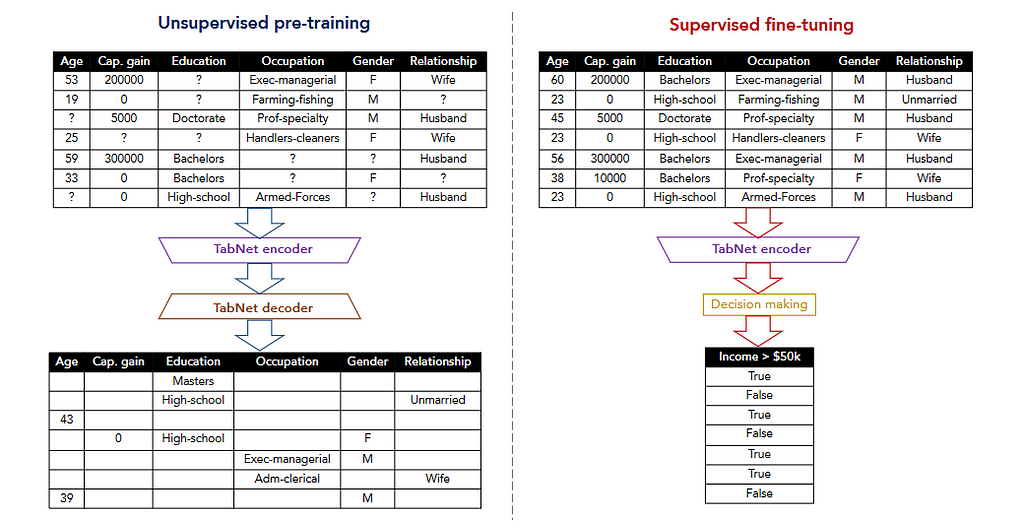
The research on Tabnet [7] and TaBERT [8]is also a progressive work towards self-supervised learning. In both of these studies, the pretext task is to recover corrupted tabular data. TabNet focuses on attention mechanism and chooses features to reason from at each step and on the other hand, TABERT, learns representations for natural language sentences and semi-structured tables.
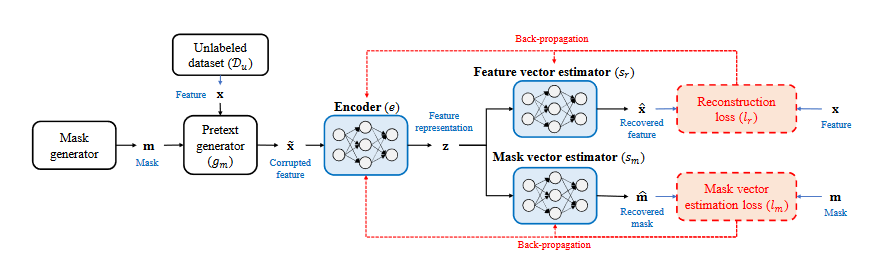
A recent work (VIME) [9] suggests a novel pretext task to recover the mask vector and the original sample with a novel corrupted sample generation technique. The authors also propose a novel tabular data augmentation mechanism that can be combined with contrastive learning to extend supervised learning for tabular data. As explained in my previous blog: “A corrupted sample is created using the masked generator that generates the binary mask vector and input sample. Note that the input sample is generated from the unlabeled data set”.
Self-supervised learning is the new norm in deep learning. The self-supervised learning techniques for both images and text data is amazing as they rely on spatial and sequential correlations respectively. However, there is no common correlation structure in tabular data. This makes self-supervised learning for tabular data more challenging.
Thanks for reading my article. Until next time…
Happy Reading!
References:
[1] Richard Zhang, Phillip Isola, and Alexei A. Efros, Colorful image colorization (2016), In European conference on computer vision
[2] Carl Doersch, Abhinav Gupta, and Alexei A. Efros, Unsupervised visual representation learning by context prediction (2015), In Proceedings of the IEEE international conference on computer vision
[3] Longlong Jing, and Yingli Tian, Self-supervised visual feature learning with deep neural networks: A survey (2020), IEEE transactions on pattern analysis and machine intelligence
[4] Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu, Pegasus: Pre-training with extracted gap-sentences for abstractive summarization (2020), In International Conference on Machine Learning
[5] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol, Extracting and composing robust features with denoising autoencoders (2008), In Proceedings of the 25th international conference on Machine learning
[6] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, Context encoders: Feature learning by inpainting (2016), In Proceedings of the IEEE conference on computer vision and pattern recognition
[7] Sercan Ö. Arik, and Tomas Pfister, Tabnet: Attentive interpretable tabular learning (2021), In Proceedings of the AAAI Conference on Artificial Intelligence
[8] Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel, TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data (2020), In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
[9] Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar, Vime: Extending the success of self-and semi-supervised learning to tabular domain (2020), Advances in Neural Information Processing Systems
Self-Supervised Learning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


