



SAM from Meta AI — The chatGPT Moment for Computer Vision AI
Last Updated on July 25, 2023 by Editorial Team
Author(s): Puneet Jindal
Originally published on Towards AI.
It’s a disruption.
What’s the news
Meta AI released a “Segment Anything Model”.
SAM is here to make image segmentation easy-peasy for all!
The moment this news erupted, a few of the queries that the community asked.
- Will it work for health sector data like X-ray images and MRI stacked data?
- How many human annotations?
- Someone mentioned that he tried the demo in one of my challenging scenes, his garage, and it had problems segmenting complete objects like an opened Costco toilet paper bag (outside plastic, one roll inside the opened outside plastic), an old storage box (front and side are segmented as different objects), or a bike with other surrounding objects. The challenge seems to be understanding that it is the same object with different objects around it without space between them.
- how can it be applied to video segmentation and 3D scene reconstruction?
and few showed a lot of excitement
eg, Sanyam Bhutani expressed his excitement by sharing a post
Someone else said
This work has will open open up a lot of downstream applications, especially those which integrate with the physical world, while lowering the labeling barrier significantly.

Let me summarize the problem statement
- It’s really hard to annotate a billion or even just a million images with image segmentation annotation.
- Companies have to employ a huge workforce to make an effort and it is a time-consuming and highly error-prone task because you have to annotate.
How did the community try solving this till now?
Companies have been using a mix of humans in the loop plus partial automation approach
- thresholding-based automation — it’s the most vanilla approach but good to understand for basics. You set a threshold on pixel intensity above which you would color code it with an alternate class.
- contour or edge-based segmentation — this is different from the previous such that it focuses on edges where there is pixel change happening. This probably is more efficient than the previous approach.
- region-based segmentation — This is more like running clustering on a group of pixels. You must have heard the saying “Birds of a feather flock together”. Here
- Graph-based segmentation — It represents an image as a graph, where the pixels are nodes and the edges represent the relationships between the pixels. In this approach, the goal is to partition the graph into disjoint regions or clusters, which correspond to the segments in the image. Though this technique is computationally expensive, especially for large images or high-dimensional feature spaces. It has been seen to perform better in the case of applications such as remote sensing, medical imaging, etc.
- Interactive segmentation: It leverages user interaction to refine the segmentation of an image. so this technique is generally used at the validation or review step and not as a base technique. Having a user-friendly interface is the key to maximizing the benefit of this technique.
- one most my favorites are deep learning-based approaches — These approaches leverage a lot of labeled data and feature engineering and it’s a learning algorithm. Some popular deep learning-based models for image segmentation include U-Net, Mask R-CNN, and Fully Convolutional Networks (FCNs)
What’s the new solution?
SAM — It’s not a human. Its full form is the “Segment Anything Model”. It’s a combination of large labeled dataset automatic segmentation coupled with interactive segmentation.
One interesting thing that has been done is that it is prompt-based, similar to the chatGPT interface.
As per Meta AI research’s words:-
Segment Anything Model (SAM): a new AI model from Meta AI that can “cut out” any object, in any image, with a single click
So this model can segment objects seen in the 1 billion dataset annotations it is trained on but it can also work with high efficiency and extract segments or propose masks from unseen images since it has been trained on such a huge highly curated dataset. So it’s differentiation it offers is that you don’t need to train on additional data. So you can call it a zero-shot generalization technique.
The only limitation is that it can’t tell you the object type or class it has segmented. So I am sure humans still have some work to do 🙂
One more interesting thing here is that its foundation architecture is the CLIP model for the text prompt-based capability. Now you must be thinking why I am referring to CLIP. So let me summarize its importance. Its full form is Contrastive Language-Image Pre-Training.
CLIP is used to power GPT (Generative Pre-trained Transformer) and ChatGPT by providing a way to incorporate visual information into the language models.

What is the impact going to be?
It has applications in many downstream computer vision and image understanding tasks.
- Robotics
- Augmented reality and virtual reality — In the AR/VR domain, SAM could enable selecting an object based on a user’s gaze and then “lifting” it into 3D
- Underwater photos or
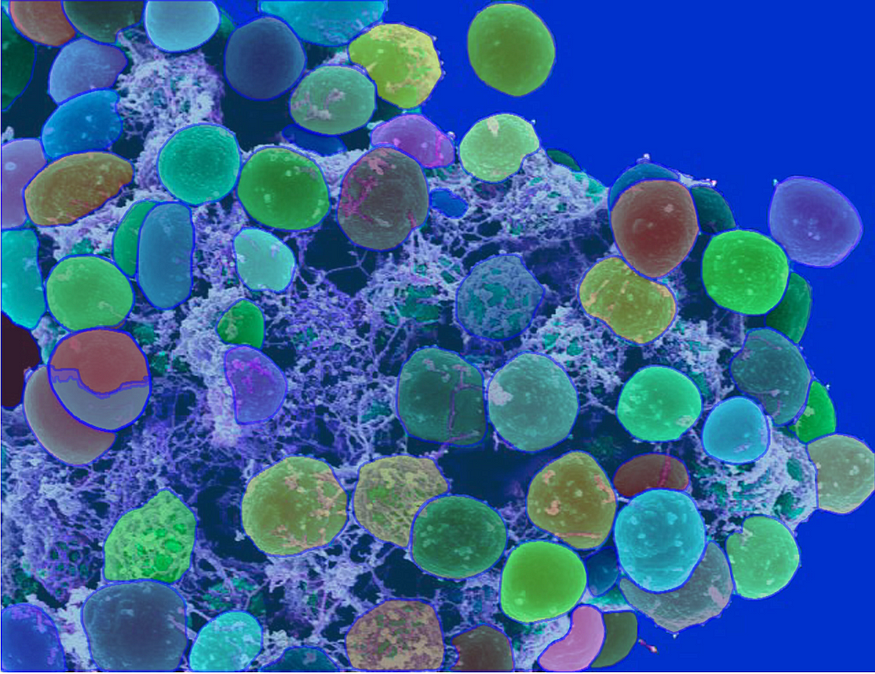
- Pathology cell microscopy
- Content creation space — content creators can extract any object or thing from an image and transport it to the target image.
- Surveillance — aids scientific study of natural occurrences on Earth or even in space, for example, by localizing animals or objects to study and track in the video.
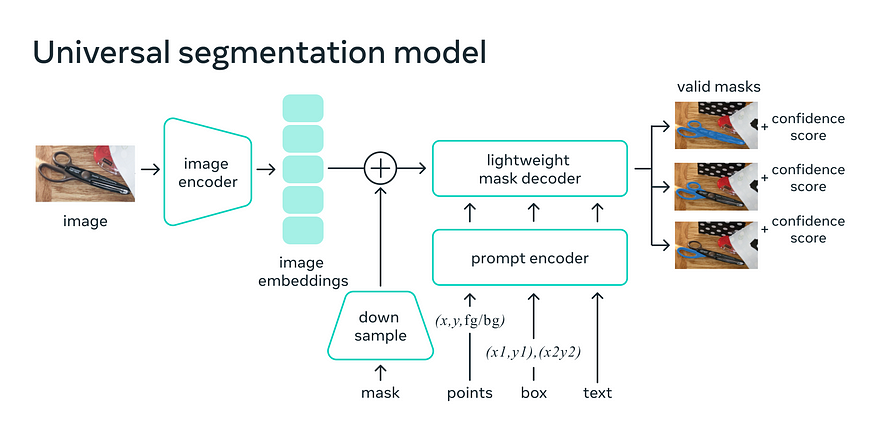
How does it work? with a few examples of scenarios I tried
It is a single model that can easily perform both interactive segmentation and automatic segmentation. However, the model provides prompts for interaction(clicks, boxes, text, and so on) similar to chatGPT.
It is trained on a diverse, high-quality dataset of over 1 billion masks (It has not been shared how the data was collected), which enables it to generalize to new types of objects and images beyond what it observed during training. and Meta AI research team claims that by and large, practitioners will no longer need to collect their segmentation data and fine-tune a model for their use case.
This model was trained to return a valid segmentation mask for any prompt, where a prompt can be foreground/background points, a rough box or mask, freeform text, or, in general, any information indicating what to segment in an image.
Architecture
Here is a quick glimpse of a comprehensive demo
Segment Anything
Meta AI Computer Vision Research segment-anything.com
I tried the below examples shown below.
Also, you can try it yourself on your images by heading over directly to
Segment Anything
Meta AI Computer Vision Research segment-anything.com
For a more detailed understanding, you can check this blog by one of my team members
My final question to you!
Do you believe that the future of AI will be ruled by a few large foundation models from the likes of Microsoft, Meta, and Google?
I would like to share what I think of it. Let’s connect over Linkedin as I write interesting and new aspects in computer vision data preparation, data ops, data pipelines, etc., and I am happy to chat on the same. Only technical deep dive!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

