


Revolutionizing Autonomy: CNNs in Self-Driving Cars
Last Updated on May 13, 2024 by Editorial Team
Author(s): Cristian Rodríguez
Originally published on Towards AI.
This article uses the convolutional neural network (CNN) approach to implement a self-driving car by predicting the steering wheel angle from input images of three front cameras in the car’s center, left, and right. The architecture of the model used was developed by NVIDIA for its autonomous navigation system called DAVE-2. The CNN is tested on the Udacity simulator.
Introduction
Self-driving cars can sense their surroundings and move independently through traffic and other obstacles without human input [1]. The usage of autonomous vehicles (AVs) has become a leading industry in almost every area of the world. Over the years, faster and more valuable vehicles have been produced, but in our accelerated world with more and more cars, unfortunately, the number of accidents has increased. In most cases, accidents are the fault of the human driver. Therefore, they could be theoretically replaceable with the help of self-propelled cars [2]. Many relevant companies like Waymo, Zoox, NVIDIA, Continental, and Uber are developing this product. With this type of car, the safety, security, and efficiency of automotive transportation are increased, and human errors can be mitigated while the drive is made to its best [1].
Like humans, AVs rely on various sensor technologies to perceive the environment and make logical decisions based on the gathered information. The most common types of AV sensors are RADAR, LiDAR, ultrasonic, camera, and global navigation systems [3].
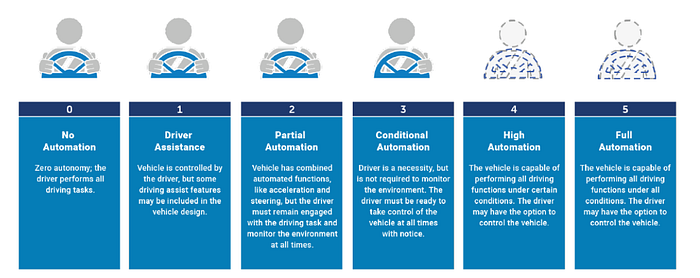
The Advanced Driver Assistance System (ADAS) is a sis-tiered system that categorizes the different levels of autonomy. It ranges from vehicles that are solely human-driven to those that are entirely autonomous, as shown in Figure 1.
Convolutional Neural Networks (CNNs)
The first work on modern CNNs occurred in the 1990s, inspired by the neocognitron. Yann LeCun et al., in their paper “Gradient-Based Learning Applied to Document Recognition,” demonstrated that a CNN model that aggregates more straightforward features into progressively more complicated features can be successfully used for handwritten character recognition [4].
A CNN is a neural network with one or more convolutional layers and is used mainly for image processing, classification, segmentation, and other auto-correlated data. Before the adoption of CNNs, most pattern recognition tasks were performed by hand during the initial feature extraction stage, followed by a classifier. With the advancement of CNNs, it has become possible for features to be learned automatically from training examples, surpassing human performance on standard datasets [5].
The CNN approach is compelling in image recognition tasks because the convolution operation captures 2D images. Also, using the convolution kernels to scan an entire image requires relatively few parameters to learn compared to the total number of operations [5].
Dataset
To obtain the data, the training mode was used in the Udacity simulator [6], driving the vehicle manually on the first track for four laps in one direction and four more laps in the opposite direction. The data log is saved in a CSV file and contains the path to the images, saved in a folder, as well as the steering wheel angle, throttle, reverse, and speed. The steering angles came pre-scaled by a factor of 1/25, so they are between -1 and 1. The data provided consisted of 6563 center, left, and right jpg images for a total data size of 19689 examples. The photos were 320 in width by 160 in height. An example of the left/center/right images taken at a one-time step from the car is shown below.

Data Augmentation
Augmentation helps to extract as much information from data as possible. Four different augmentation techniques were used to increase the number of images the model would see during training; this reduced the tendency of overfitting. The image augmentation techniques used are described as follows:
- Brightness reduction: changing brightness to simulate day and night conditions.
- Left and right camera images: we use left and right camera images to simulate the effect of a car wandering off to the side and recovering.
- Horizontal and vertical shifts: the camera images are shifted horizontally to simulate the car’s different positions on the road and vertically to simulate the effect of driving up or down the slope.
- Flipping: since the left and right turns in the training data are not even, image flipping was essential for model generalization.
The following images show examples of the data augmentation applied.



Data Preprocessing
After augmenting the images, data preprocessing was applied to format them before using them by model training. Preprocessing aims to improve the quality of the image so that it can be analyzed better. The image preprocessing techniques used are described as follows:
- Cropping: the bottom 25 and top 40 pixels from each image were cropped to remove the front of the car and most of the sky above the horizon from the pictures.
- RGB to YUV: the images were converted from RGB to YUV type as it has more advantages in illumination change and shape detection.
- Resizing: to be consistent with the NVIDIA model, all the images were resized to 66 x 200.
- Normalization: dividing by 255 the image pixel values to have just pixel values between 0 and 1.
The following figure shows an example of the image preprocessing applied.

Data Generator
As thousands of new training instances are needed from each original image, generating and storing all this data on the disk is impossible. Therefore, a Keras generator was used to read original data from the log file, augment it on the fly, and use it to train the model, producing new images at each batch.
Model Proposal
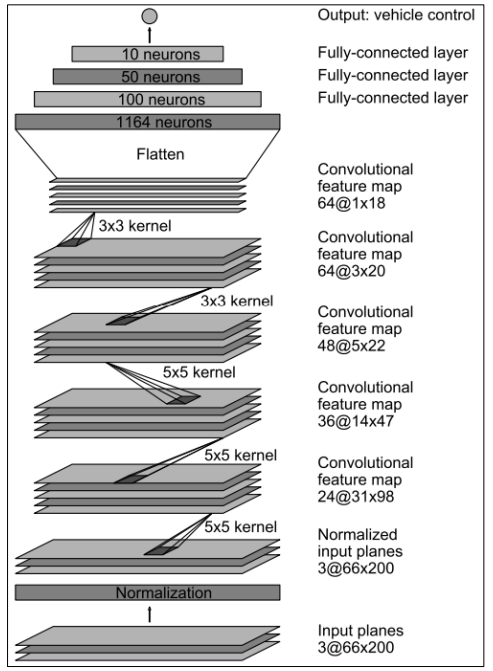
As previously mentioned, a CNN model was used. The model architecture, inspired by the NVIDIA model used in its DAVE-2 system, is shown in Figure 7.
This model has the following characteristics:
- The input image is 66 x 200.
- It has a series of three 5×5 convolutional layers, and as one goes deeper into the network, each layer’s respective depth is 24, 36, and 48.
- Then, there are two consecutive 3×3 convolutional layers with a depth 64.
- The result is flattened to enter the fully connected phase.
- Finally, a series of fully connected layers of gradually decreasing sizes: 1164, 200, 50, and 10.
- The output layer is size one since the prediction is just one variable, the steering angle.
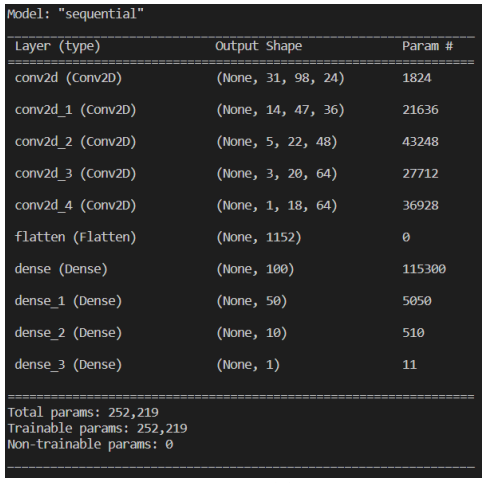
- It has 252219 trainable parameters.
Figure 8 shows the complete summary of the implemented model.
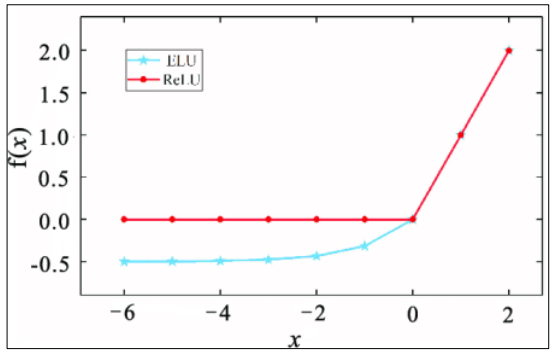
The model uses the exponential linear unit (ELU) nonlinear as an activation function. In contrast to ReLU, ELU has negative values, which allows it to push mean unit activations closer to zero. Figure 9 shows the difference between ReLU and ELU.
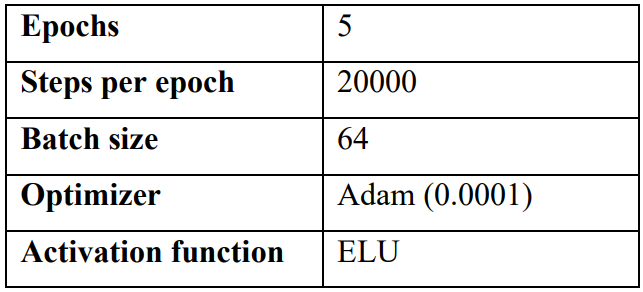
Also, the Adam optimizer was used, an extension to stochastic gradient descent; it uses the squared gradients to scale the learning rate, updating the network weights iteratively based on training data. The learning rate used was an alpha of 0.0001. Table 1 summarizes the parameters used for the model.
The model was trained using an NVIDIA GeForce RTX 3050 GPU, and the entire training took about 6 hours.
Test & Validation
The initial dataset was divided into training and validation, with 80% for training and 20% for validation. Figure 10 shows the loss comparison between training and validation.
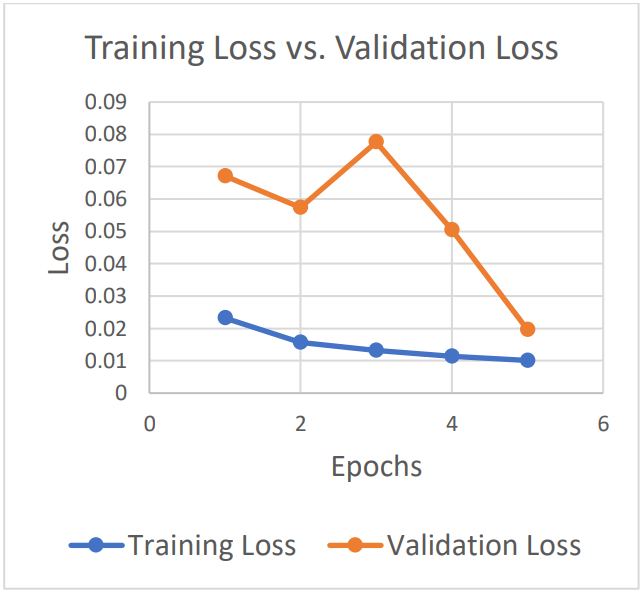
As we can see in Figure 10, as the epoch increases, the loss value decreases. Although a significant gap exists between training loss and validation loss initially, they become almost equal.
The model was tested on both tracks. The model ran smoothly on the first track, where the training data was collected. However, it is unstable, making many small turns between left and right.
On the other hand, track 2 has better behavior and runs entirely with excellent performance, so the model generalizes well.
The video of the performance on both tracks is available at the following link: Self-Driving Car: Predicting Steering Wheel Angle using Udacity’s Simulator — Model Performance (youtube.com)
Conclusions
It has been demonstrated that a model that reliably predicts a vehicle’s steering wheel angles can be created using deep neural networks and various data augmentation techniques.
After observing the results, the obtained model is very good since it performed well on both tracks. However, better training can be done by adjusting the parameters and increasing the number of epochs.
An even better model with the same performance as the current one can be achieved with less training time by adjusting the model parameters.
In the future, it would be good to explore the performance using another model architecture, other data augmentation techniques, an experiment with a reinforcement learning model, and even test the model’s performance on a real car.
Thanks for reading!
GitHub Code
References
[1] Manikandan, T. (2020). Self-driving car
[2] Szikora, P. (2017). Self-driving cars — The human side
[3] Vargas, J., et al. (2021). An Overview of Autonomous Vehicles Sensors and Their Vulnerability to Weather Conditions
[4] Draelos, R. (2019). The History of Convolutional Neural Networks
[5] Bojarski, M., et al. (2016). End to End Learning for Self-Driving Cars
[6] Udacity. (2016). Udacity’s Self-Driving Car Simulator.
[7] Yang, L., et al. (2020). Random Noise Attenuation Based on Residual Convolutional Neural Network in Seismic Datasets
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

