


")
Review: IEF — Iterative Error Feedback (Human Pose Estimation)
Last Updated on July 20, 2023 by Editorial Team
Author(s): Sik-Ho Tsang
Originally published on Towards AI.
A Review on IEF U+007C Towards AI
Outperforms Tompson NIPS’14, and Tompson CVPR’15
In this story, IEF (Iterative Error Feedback), by UC Berkeley, is briefly reviewed. Instead of directly predicting the outputs in one go, a self-correcting model is used to progressively change an initial solution by feeding back error predictions. This is a 2016 CVPR paper with more than 300 citations. (
Sik-Ho Tsang @ Medium)
Outline
- IEF Architecture Overview
- Training
- Ablation Study
- Comparison with State-Of-The-Art Approaches
1. IEF Architecture Overview


- xt, the concatenation of input image I with a visual representation g, input to the model f. With 3-channel RGB images and K heatmaps for K key points, there are K+3 channels for xt.
- Then model f output/predict a “correction” et.
- yt+1 = et + yt to obtain a new y.
- yt+1 is converted into a visual representation of g. g is 2D Gaussian having a fixed standard deviation and centered on the keypoint location.
- This procedure is initialized with a guess of the output (y0) and is repeated until a predetermined termination criterion is met.
- y0 is the median of ground truth 2D keypoint locations on training images
2. Training
2.1. Loss Function

- et and e(y, yt) are the predicted and target bounded corrections, respectively.
- h is a measure of distance, such as a quadratic loss.
- T is the number of correction steps taken by the model. T=4.
2.2. Fixed Path Consolidation (FPC)
- The above is the iterative process, but we only got the final ground-truth. We do not have the intermediate ground-truth.
- The simplest strategy is to predefine yt for every iteration using a set of fixed corrections e(y, yt) starting from y0, obtaining (y0, y1, …, y).
- The target bounded corrections for every iteration are computed using a function:
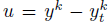

- where k is the k-th keypoint. L denotes the maximum displacement for each keypoint location. L = 20 pixels. u^ is the unit vector of u.
2.3. ConvNet
- ImageNet pre-trained GoogLeNet is used.
- The conv-1 filters are modified to be operated on 20 channel inputs. The weights of the first three conv-1 channels were initialized using the weights learned by pre-training on Imagenet. The weights corresponding to the remaining 17 channels were randomly initialized with the Gaussian noise of variance 0.1.
- The last layer of 1000 units that predicted the Imagenet classes is discarded. It is replaced with a layer containing 32 units, encoding the continuous 2D correction expressed in Cartesian coordinates (the 17th ”keypoint” is the location of one point anywhere inside a person used in both training and testing).
3. Ablation Study

3.1. Iterative v/s Direct Prediction
- IEF that additively regresses to keypoint locations achieves PCKh-0.5 of 81.0 as compared to PCKh of 74.8 achieved by directly regressing to the keypoints.
3.2. Iterative Error Feedback v/s Iterative Direct Prediction
- IEF achieves PCKh-0.5 of 81.0 as compared to PCKh of 73.4 by iterative direct prediction.
3.3. Importance of Fixed Path Consolidation (FPC)
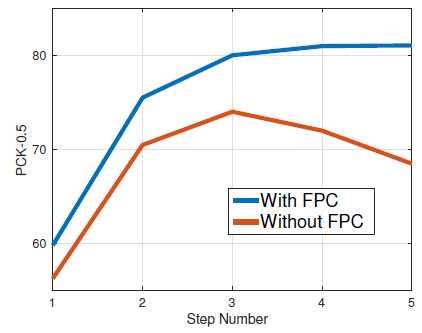
- Without FPC, the performance drops by almost 10 PCKh points on the validation set.
3.4. Learning Structure Outputs

- As a baseline, regression gets 64.6.
- The IEF model with a single additional input channel for the left knee gets PCKh of 69.2.
- Furthermore, the IEF model over both the left knee and left hip gets PCKh of 72.8.
- Finally, modeling all joints together with the image obtains a PCKh of 73.8.
3.5. Visualization

4. Comparison with State-Of-The-Art Approaches
4.1. MPII

- IEF outperforms SOTA such as Tompson CVPR’15.
4.2. LSP

- There is also no marking point on the torsos, so the 17th keypoints are initialized to be the center of the image.
- IEF outperforms SOTA such as Tompson NIPS’14.
Reference
[2016 CVPR] [IEF]
Human Pose Estimation with Iterative Error Feedback
My Previous Reviews
Image Classification [LeNet] [AlexNet] [Maxout] [NIN] [ZFNet] [VGGNet] [Highway] [SPPNet] [PReLU-Net] [STN] [DeepImage] [SqueezeNet] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2] [Inception-v3] [Inception-v4] [Xception] [MobileNetV1] [ResNet] [Pre-Activation ResNet] [RiR] [RoR] [Stochastic Depth] [WRN] [ResNet-38] [Shake-Shake] [FractalNet] [Trimps-Soushen] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [DMRNet / DFN-MR] [IGCNet / IGCV1] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2]
Object Detection [OverFeat] [R-CNN] [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net] [CRAFT] [R-FCN] [ION] [MultiPathNet] [NoC] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [G-RMI] [TDM] [SSD] [DSSD] [YOLOv1] [YOLOv2 / YOLO9000] [YOLOv3] [FPN] [RetinaNet] [DCN]
Semantic Segmentation [FCN] [DeconvNet] [DeepLabv1 & DeepLabv2] [CRF-RNN] [SegNet] [ParseNet] [DilatedNet] [DRN] [RefineNet] [GCN] [PSPNet] [DeepLabv3] [ResNet-38] [ResNet-DUC-HDC] [LC] [FC-DenseNet] [IDW-CNN] [DIS] [SDN] [DeepLabv3+]
Biomedical Image Segmentation [CUMedVision1] [CUMedVision2 / DCAN] [U-Net] [CFS-FCN] [U-Net+ResNet] [MultiChannel] [V-Net] [3D U-Net] [M²FCN] [SA] [QSA+QNT] [3D U-Net+ResNet] [Cascaded 3D U-Net] [Attention U-Net] [RU-Net & R2U-Net] [VoxResNet] [DenseVoxNet][UNet++] [H-DenseUNet] [DUNet]
Instance Segmentation [SDS] [Hypercolumn] [DeepMask] [SharpMask] [MultiPathNet] [MNC] [InstanceFCN] [FCIS]
Super Resolution [SRCNN] [FSRCNN] [VDSR] [ESPCN] [RED-Net] [DRCN] [DRRN] [LapSRN & MS-LapSRN] [SRDenseNet] [SR+STN]
Human Pose Estimation [DeepPose] [Tompson NIPS’14] [Tompson CVPR’15] [CPM] [FCGN] [IEF]
Codec Post-Processing [ARCNN] [Lin DCC’16] [IFCNN] [Li ICME’17] [VRCNN] [DCAD] [DS-CNN]
Generative Adversarial Network [GAN]
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

