


")
Review: G-RMI — 1st Runner Up in COCO KeyPoint Detection Challenge 2016 (Human Pose Estimation)
Last Updated on July 24, 2023 by Editorial Team
Author(s): Sik-Ho Tsang
Originally published on Towards AI.
Two-Stage Top-Down Approach: First, Person Detection. Then, Keypoint Detection.
In this story, G-RMI for person keypoint detection or human pose estimation, by Google Inc., is reviewed. G-RMI, Google Research, and Machine Intelligence should be the team name rather than the approach name.
To detect a multi-person and estimate the pose, a two-stage approach is proposed.
- First, multi-person are detected using Faster R-CNN.
- Then, fully convolutional ResNet is used to detect the keypoint of each person.
This is the 2017 CVPR paper with over 200 citations. (
Sik-Ho Tsang @ Medium)
Outline
- Person Box Detection
- Person Pose Estimation
- Ablation Study
- Comparison with SOTA Approaches
1. Person Box Detection
- Faster R-CNN is used.
- ResNet-101 is used as a backbone.
- Atrous convolution (Please refer it to DeepLabv1 & DeepLabv2) is used to have a stride of 8 instead of default 32.
- Pre-trained by ImageNet.
- Then, the network is trained using only the person category in the COCO dataset, and the box annotations for the remaining 79 COCO categories have been ignored.
- Multi-scale evaluation or model ensembling is not used.
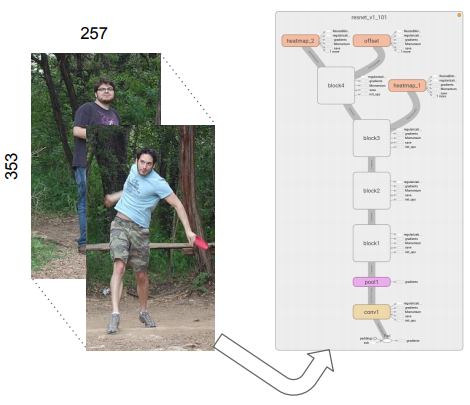
- After person detection, the detected box will be input to CNN for person pose estimation, which is mentioned below.
2. Person Pose Estimation

- A combined classification and regression approach is used.
- The network first classifies whether it is in the vicinity of each of the K keypoints or not (which we call a “heatmap”).
- Then predict a 2-D local offset vector to get a more precise estimate of the corresponding keypoint location.
2.1. Image Cropping
- First, make all boxes have the same fixed aspect ratio.
- Then, use a rescaling factor equal to 1.25 during evaluation and a random rescaling factor between 1.0 and 1.5 during training (for data augmentation).
- Next, crop from the resulting box the image and resize to a fixed crop of height 353 and width 257 pixels. (Aspect ratio of 1.37)
2.2. Heatmap and Offset Prediction
- Fully convolutional ResNet-101 is used to produce heatmaps (one channel per keypoint) and offsets (two channels per keypoint for the x and y-directions) for a total of 3K output channels, where K = 17 is the number of key points.
- ImageNet pre-trained ResNet-101 model is used with replacing its last layer with 1×1 convolution to have 3K outputs.
- Atrous convolution (Please refer it to DeepLabv1 & DeepLabv2) is used to have a stride of 8.
- Bilinearly upsampled is used to enlarge the network output back to the 353×257 crop size.
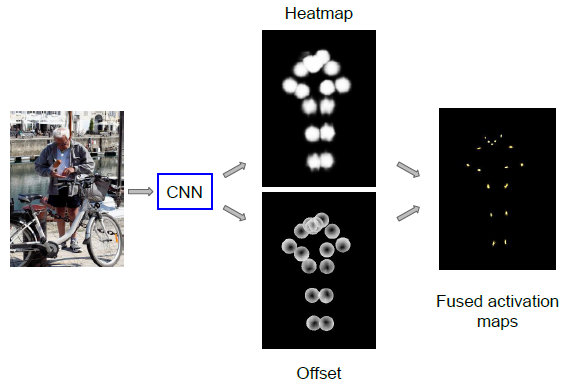

- First head: A sigmoid function to yield the heatmap probabilities hk(xi) for each position xi and each keypoint k.
- hk(xi) is the probability that the point xi is within a disk of radius R from the location lk of the k-th keypoint. If it is outside R, hk(xi)=0.
- The corresponding loss function Lh is the sum of logistic losses for each position and keypoint separately.
- Besides, an extra heatmap prediction layer at intermediate layer 50 of ResNet is added as auxiliary loss term to accelerate the training process.
- Second head: It is an offset regression head that penalizes the difference between the predicted and ground truth offsets.

- Huber robust loss H(u) is used where Fk(xi) is the predicted 2-D offset vector.
- At last, the final loss function is:

- where λh and λo are 4 and 1, respectively.
2.3. OKS-Based Non Maximum Suppression
- The standard approach measures overlap using intersection over union (IoU) of the boxes, and redundant boxes are removed.
- Now, G-RMI measures overlap using the object keypoint similarity (OKS) for two candidate pose detections.
- A relatively high IOU-NMS threshold (0.6) is used at the output of the person box detector to filter highly overlapping boxes.
- This is better suited to determine if two candidate detections correspond to false positives (double detection of the same person) or are true positives (two people in close proximity to each other).
3. Ablation Study
3.1. Box Detection Module

- COCO-only: Only using COCO for training.
- COCO+Int: COCO with additional Flickr images for training.
- A fast 600×900 variant that uses input images with small side 600 pixels and large side 900 pixels is tested
- An accurate 800×1200 variant that uses input images with small side 800 pixels and large side 1200 pixels is also tested.
- The accurate Faster R-CNN (800×1200) box detector is used.
3.2. Pose Estimation Module

- Smaller (257×185) for faster inference or larger (353×257) for higher accuracy.
- The accurate ResNet-101 (353×257) pose estimator with disk radius R = 25 pixels is used.
3.3. OKS-Based Non Maximum Suppression

- In all experiments, later on, the value of the IOU-NMS threshold at the output of the person box detector remains fixed at 0.6.
- The value of 0.5 is also good for OKS-based NMS.
4. Comparisons with SOTA Approaches

- G-RMI (COCO-Only) outperforms CMU-Pose and Mask R-CNN.
- G-RMI (COCO-Int) obtains an even higher AP of 0.685.

- Again, G-RMI (COCO-Only) outperforms CMU-Pose.
- And G-RMI (COCO-Int) obtains an even higher AP of 0.673.

- Heavily cluttered scenes (third row, rightmost and last row, right)
- Occlusions (the last row, left) and hallucinates occluded joints.
- Some of the false positive detections are, in reality, correct as they represent pictures of people (first row, middle) or toys (fourth row, middle).
- I hope I can review CMU-Pose/OpenPose and Mask R-CNN in the future.
Reference
[2017 CVPR] [G-RMI]
Towards Accurate Multi-person Pose Estimation in the Wild
My Previous Reviews on Human Pose Estimation
Human Pose Estimation [DeepPose] [Tompson NIPS’14] [Tompson CVPR’15] [CPM] [FCGN] [IEF] [DeepCut & DeeperCut] [Newell ECCV’16 & Newell POCV’16] [G-RMI] [CMUPose & OpenPose]
My Other Previous Reviews
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

