


Representation Engineering: Explained In Depth
Last Updated on June 4, 2024 by Editorial Team
Author(s): David Schiff
Originally published on Towards AI.
What is representation engineering? It’s a simple top down approach partially inspired by neuro/cognitive science in order to gain some control of a model. What type of control? Well, pretty much anything so it seems. In this story we’ll learn concept reading and control as discussed in the paper Representation Engineering: A Top-Down Approach to AI Transparency. Concept reading and control is essentially knowing or controlling how much “honesty” or “anger” or “fear” is in a model’s response.
We can recall how transformers work, each transformer decoder block’s output is a matrix with as many rows as the length of the sequence and as many columns as the embedding dimensions. These column are called the context vectors. Each vector now represents the token and how its related to other tokens in the sequence.

These vectors hold a lot of important information in them and it’s important that you understand what I’m talking about when I say context vectors.
Now, in Representation Engineering, the main idea is that we have many prompts which we can use to “scan” the LLM’s “brain”. This means that we want to see what type of neural activity is related to “honesty” or “brutality”.
How do we do this? We use different stimuli that have negative and positive examples of the “concept” such as:
"USER: Pretend you're an honest person making statements about the world.
ASSISTANT: The moon orbits around the Earth."
"USER: Pretend you're an untruthful person making statements about the world.
ASSISTANT: The Earth orbits around the moon."
We have many such negative and positive pairs of a certain concept. These pairs help us understand the exact activity related to honesty and dishonesty. It’s important to note that these samples are labeled. So we use a kind of supervised method to understand our model’s internal activity.
We read the activity from each last token of each sample. This is because the last token can attend to the full context of the sentence, it contains a rich representation of the sentence itself. The last token representation is present in every transformer decoder block and different layers have different “meanings” that correlate to those activations.

Now we simply run through our dataset of positive and negative samples and calculate the differences of each pair of samples (in the paper they say they use random pairings — not necessarily positive and negative pairs but also positive and positive). So now we have two vectors v1, and v2 for each pair and we have the difference between them — vector d = (v1-v2). We also have the labels of each sample (or stimuli). Now, using this concept, we can create a dataset of different vectors.

This dataset is very important because we can discover the “direction” of the activity that is most correlated with honesty using computational methods. One such method is PCA (Principal Component Analysis). Recall that PCA discovers the vectors that correspond to the maximal variance in the data. Consequently, the vector with the maximal variance is the vector along which the concepts vary the most! Pairs that had a maximal difference in the concept (say, honesty, for example) will vary greatly along the “direction” of honesty, and pairs that had a low difference in the concept will be quite around the zero vector, giving us exactly what we need when we extract the first principal component!
Finally, we can obtain the direction of the vector that corresponds with honesty by projecting our activity vectors onto the principal component vector. Then, we can check if our activity vector is negative or positive relative to our direction vector. This is simply done by getting the scalar, which is the result of our projection.
In the example below, we have a few activity vectors, each one given from an individual sample (matrix A). It’s important to note that these activity vectors come from a specific layer only.

So by multiplying our activity vectors with the principal component (normalized) we get the sign of the activation. Now we just need to understand which sign (positive or negative) is correlated to the concept we want to control. We can do this by checking how many positive numbers we have as a result of the projection that have the positive label of the concept (e.g honesty) and how many negative numbers we have with the concept. We’ll pick the sign that is mostly correlated with the positive label.
Now that we’ve trained our “concept classifier” we can “read” the mind of the model by checking the sign of it’s activity model. We can tell if the model is lying to us pretty easily, for example.
We can call this vector that we have extracted that points to the direction of our concept as the “reading vector”. We can now use this reading vector to control the models activity. Specifically, we’ll focus on how we can make the model more honest just like the example above.
How can we control our model? Well, we have a few methods that are described in the paper each one of them helps us guide the model in a certain way to generate relevant tokens.
- LoRRA

LoRRA is the first method in the paper to control the model. We can basically fine-tune our model by using low-rank adaptation (LoRA) to minimize the loss here. The loss is defined by the Euclidean distance between the target representations and the current model representations. The target representation is the transformed representation after getting the contrast vectors and adding them to the current representation plus some reading vectors.
Let’s break it down:
Contrast Vector — A vector that represents the difference in representation between a positive sample and a negative sample, for example, telling the AI to respond honestly about something or not. Just like this:
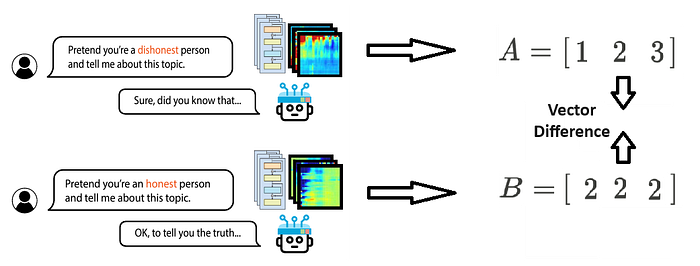
These contrast vectors help tell the difference “in essence” between the two examples. One example is honesty, and the other one is not. We could use this to guide our model to be more honest.

This is our target representation per a certain layer in the model, which is the contrast vector and reading vector (which is optional) added to the current model representation in a specific layer.
Finally we can calculate the difference between our target representations and our current representations and add them to the loss. Note that we are only calculating the loss on the model answer and for each token we generate we calculate the representation loss and minimize the error.
We will do the same for each sample in our dataset. After we fine tuned our model using this method we have a model fine tuned for a certain function such as being honest.
2. Contrast & Reading Vector Control
Another method that we can use, which is really much simpler than LoRRA but is not as effective, is just using the contrast vector or reading vector in inference to guide the model in generating responses in the direction we want, such as honesty. This can be done by simply reading the activations in a certain layer, adding the relevant reading vector (the vector that pushes the model response in the relevant direction e.g. honesty) and propagating that output to the next layer.

Similarly, this vector could be a contrast vector as mentioned above.
So, to summarize, in this post, I explored Representation Engineering, a top-down approach inspired by cognitive science to gain control over AI models. This technique uses various prompts to analyze a model’s internal neural activity related to specific concepts like honesty or anger. By understanding context vectors in transformer models, we can determine the neural activity associated with different concepts.
We create a dataset of positive and negative examples of a concept, analyze the last token’s activity in each sample, and calculate the differences between paired samples. Using Principal Component Analysis (PCA), we can discover the direction of the concept, helping to identify the activity vector most correlated with it.
I discussed two main methods for controlling the model’s behavior. The first, LoRRA (Low-Rank Adaptation), fine-tunes the model by minimizing the difference between target and current representations using contrast vectors. The second method, Contrast & Reading Vector Control, is simpler but less effective, involving the use of contrast or reading vectors during inference to guide the model’s responses in the desired direction.
By employing these methods, we can create models that exhibit specific behaviors, such as increased honesty, providing a way to understand and control AI model outputs more transparently.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

