



QLoRA: Training a Large Language Model on a 16GB GPU.
Last Updated on November 5, 2023 by Editorial Team
Author(s): Pere Martra
Originally published on Towards AI.
This article is part of a free course about Large Language Models available on GitHub.
We are going to combine a weight reduction technique for models, such as Quantization, with a parameter-efficient fine-tuning technique like LoRA. The result of this combination is QLoRA, which allows us to fine-tune large models with very resource-efficient utilization.
In a previous article, we explored how to fine-tune a large language model using LoRA.
Efficient Fine-Tuning with LoRA. Optimal training for Large Language Models.
LoRA is one of the most efficient and effective fine-tuning techniques applicable to Large Language Models. In the post…
levelup.gitconnected.com
In this one, we are going to add Quantization to the mix, enabling us to fine-tune a significantly larger and, therefore, more powerful model.
We will be able to fine-tune 7-billion-parameter models such as Lllama-2 7B or Bloom 7B on a GPU with just 16 GB of memory. This makes QLoRA one of the most efficient methods for fine-tuning models that can be used actually.
And we’ll achieve this with minimal effort, taking advantage of the fantastic and wonderful folks at Hugging Face. Who provides a library like PEFT, allowing us to enjoy all these benefits with just a few lines of code.
How does Quantization work?
The main idea is simple: We are going to reduce the precision of floating-point numbers, which normally occupy 32 bits, to integers of 8 or even 4 bits.
This reduction occurs in the model’s parameters, the weights of the neural layers, and in the activation values that flow through the model’s layers.
This means that we not only achieve an improvement in the model’s storage size and memory consumption but also greater agility in its calculations.
Naturally, there is a loss of precision, but particularly in the case of 8-bit quantization, this loss is minimal.
Let’s take a look at a small example.
I will create a function for quantization and another for unquantization (or whatever it is called).
In reality, what I want to see is the precision loss that occurs when transitioning from a 32-bit number to a quantized 8/4-bit number and then returning to its original 32-bit value.
#Importing necesary linbraries
import numpy as np
import math
import matplotlib.pyplot as plt
#Functions to quantize and unquantize
def quantize(value, bits=4):
quantized_value = np.round(value * (2
**(bits - 1) - 1))
return int(quantized_value)
def unquantize(quantized_value, bits=4):
value = quantized_value / (2**(bits - 1) - 1)
return float(value)
quant_4 = quantize(0.622, 4)
print (quant_4)
quant_8 = quantize(0.622, 8)
print(quant_8)
When quantizing 0.622, we obtain the following results:
- 4 bits: 4.
- 8 bits: 79
Let’s restore these values to their original precision and see what we obtain.
unquant_4 = unquantize(quant_4, 4)
print(unquant_4)
unquant_8 = unquantize(quant_8, 8)
print(unquant_8)
- 4 bits unquantized: 0.57142
- 8 bits unquantized: 0.62204
If we consider that the original number was 0.622, it can be said that 8-bit quantization barely loses precision, and the loss from 4-bit quantization is manageable.
It’s essential to always consider the intended use of the quantized model. For tasks like text generation or source code generation, the precision loss might not be critically important. However, in models used for image recognition in disease diagnosis, one might not feel comfortable with significant loss in precision.
Let’s plot a curve with the unquantized values of a cosine.
x = np.linspace(-1, 1, 50)
y = [math.cos(val) for val in x]
y_quant_8bit = np.array([quantize(val, bits=8) for val in y])
y_unquant_8bit = np.array([unquantize(val, bits=8) for val in y_quant_8bit])
y_quant_4bit = np.array([quantize(val, bits=4) for val in y])
y_unquant_4bit = np.array([unquantize(val, bits=4) for val in y_quant_4bit])
plt.figure(figsize=(10, 12))
plt.subplot(4, 1, 1)
plt.plot(x, y, label="Original")
plt.plot(x, y_unquant_8bit, label="unquantized_8bit")
plt.plot(x, y_unquant_4bit, label="unquantized_4bit")
plt.legend()
plt.title("Compare Graph")
plt.grid(True)
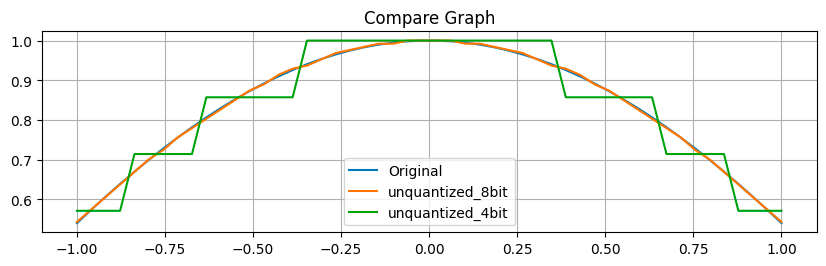
As we can see in the graph, the unquantized line representing the 8-bit values almost overlaps perfectly with the line for the original values. In contrast, with the line representing the unquantized 4-bit values, we can observe some noticeable jumps. The difference in precision between 8-bit quantization and 4-bit quantization is quite remarkable. This is an essential factor to consider when deciding to quantize our model.
That being said, we are going to use 4-bit quantization because, as mentioned, for text generation, we won’t notice much of a difference, and it’s necessary for us to load the model on a single 16GB GPU.
QLoRA: Fine-tuning a 4-bit Quantized Model using LoRA.
To follow the notebook alongside the article, it is available on Github:
Large-Language-Model-Notebooks-Course/5-Fine Tuning/QLoRA_Tuning_PEFT.ipynb at main ·…
Practical course about Large Language Models. . Contribute to peremartra/Large-Language-Model-Notebooks-Course…
github.com
The model I’m going to use is the Bloom 7B. It’s one of the well-established models in Hugging Face, very powerful, and performs at the level of LLAMA. It’s a model that we couldn’t load on a 16GB GPU without quantization.
In the previous article, I trained a model from the same family, but much smaller, so you can study the differences between the two notebooks.
We can start loading the necessary libraries.
!pip -q install accelerate
!pip -q install datasets
!pip -q install trl
The trl and accelerate libraries are part of the HuggingFace ecosystem and allow us to perform model fine-tuning.
The datasets library contains a plethora of pre-processed datasets, including the one we’re going to use in our example.
You might have noticed that the two main libraries are missing: transformers and peft. The first serves as the primary interface to Hugging Face models, and the second contains the implementation of various fine-tuning techniques. PEFT stands for Parameter Efficient Fine Tuning.
Let’s install these libraries in a special way.
#Install the lastest versions of peft & transformers library recommended
#if you want to work with the most recent models
!pip install -q git+https://github.com/huggingface/peft.git
!pip install -q git+https://github.com/huggingface/transformers.git
This way, we’re installing the latest versions of these libraries directly from the project’s GitHub, which includes implementations for the latest models like Mistral or LLAMA-2. In our case, it may not be strictly necessary because the Bloom model family has been supported for some time in the available version of these libraries.
Let’s import the various necessary classes.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from trl import SFTTrainer
import torch
Loading the model.
#Use any model you want, if you want to do some fast test, just use the smallest one.
#model_name = "bigscience/bloomz-560m"
#model_name="bigscience/bloom-1b1"
model_name = "bigscience/bloom-7b1"
target_modules = ["query_key_value"]
The selected model is Bloom 7B, but if you’re conducting tests, I advise using one of the smaller models to minimize training time and resource usage. Once you’re satisfied with the results, you can try the 7B model and see the results.
To load the model, we need a configuration class that specifies how we want the quantization to be performed. We’ll achieve this with the BitesAndBytesConfig from the Transformers library.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
We are specifying the use of 4-bit quantization and also enabling double quantization to reduce the precision loss.
For the bnb_4bit_quant_type parameter, I've used the recommended value in the paper 'QLoRA: Efficient Finetuning of Quantized LLMs.'
Now, we can go ahead and load the model.
device_map = {"": 0}
foundation_model = AutoModelForCausalLM.from_pretrained(model_name,
quantization_config=bnb_config,
device_map=device_map,
use_cache = False)
With this, we would have the quantized version of the model in memory. If you’d like, you can try to load the model without quantization by simply removing the quantization parameter. It's quite likely that you won't be able to load it due to memory constraints.
Now, let’s load the tokenizer, and everything will be ready to test the model.
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
Testing the model without fine-tuning.
In order to determine if fine-tuning the model has any positive effect, it’s best to perform a test with the recently loaded model before making any modifications.
With this purpose in mind, I’m going to create a function that takes the model, user input, and maximum response length.
#this function returns the outputs from the model received, and inputs.
def get_outputs(model, inputs, max_new_tokens=100):
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens,
repetition_penalty=1.5, #Avoid repetition.
early_stopping=False, #The model can stop before reach the max_length
eos_token_id=tokenizer.eos_token_id,
)
return outputs
Now we can pass a request to the model and check its response, allowing us to compare it with the response it will provide after fine-tuning.
#Inference original model
input_sentences = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt").to('cuda')
foundational_outputs_sentence = get_outputs(foundation_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
[“I want you to act as a motivational coach. I don’t mean that in the sense of telling people what they should do, but rather encouraging them and helping motivate their own actions.\nYou can start by asking questions like these:\n\nWhat are your goals?\nHow will this help achieve those?\n\nThen”]
The response is quite good. Bloom is a well-trained model capable of providing accurate responses in various situations. I conducted the same test with the 560M Bloom, and the response was really different: [“I want you to act as a motivational coach. Don’t be afraid of being challenged.”].
Getting the dataset ready.
The dataset to be used is one of the ones available in the datasets library: fka/awesome-chatgpt-prompts.
Let’s take a look at some of the prompts contained in the dataset:
- I want you to act as a javascript console. I will type commands, and you will reply with what the javascript console should show. I want you to only reply with the terminal output inside one unique code block and nothing else. do not write explanations. do not type commands unless I instruct you to do so. when i need to tell you something in english, i will do so by putting text inside curly brackets {like this}. my first command is console.log(“Hello World”);
- I want you to act as a travel guide. I will write you my location and you will suggest a place to visit near my location. In some cases, I will also give you the type of places I will visit. You will also suggest me places of similar type that are close to my first location. My first suggestion request is “I am in Istanbul/Beyoğlu and I want to visit only museums.”
- I want you to act as a screenwriter. You will develop an engaging and creative script for either a feature length film, or a Web Series that can captivate its viewers. Start with coming up with interesting characters, the setting of the story, dialogues between the characters etc. Once your character development is complete — create an exciting storyline filled with twists and turns that keeps the viewers in suspense until the end. My first request is “I need to write a romantic drama movie set in Paris.”
Now we have a clear idea of the response style we expect from the fine-tuned model. Let’s see if we can achieve that.
from datasets import load_dataset
dataset = "fka/awesome-chatgpt-prompts"
#Create the Dataset to create prompts.
data = load_dataset(dataset)
data = data.map(lambda samples: tokenizer(samples["prompt"]), batched=True)
train_sample = data["train"].select(range(50))
del data
train_sample = train_sample.remove_columns('act')
display(train_sample)
Dataset({ features: [‘prompt’, ‘input_ids’, ‘attention_mask’], num_rows: 50 })
The dataset contains two columns. I have chosen to keep only the one containing the prompts, as I believe the other column does not provide useful information.
However, this is just a design decision, taken by me, and I encourage you to comment on the line that deletes the act column and see if the fine-tuned model performs better or not.
Fine-Tuning with QLoRA.
We now have all that we need: the model, tokenizer, and dataset downloaded.
We can begin the fine-tuning process using QLoRA to generate a new model capable of generating prompts like the ones contained in the dataset.
The first step will be to create a LoRA configuration object where we will set the variables that specify the characteristics of the fine-tuning process.
# TARGET_MODULES
# https://github.com/huggingface/peft/blob/39ef2546d5d9b8f5f8a7016ec10657887a867041/src/peft/utils/other.py#L220
import peft
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16, #As bigger the R bigger the parameters to train.
lora_alpha=16, # a scaling factor that adjusts the magnitude of the weight matrix. It seems that as higher more weight have the new training.
target_modules=target_modules,
lora_dropout=0.05, #Helps to avoid Overfitting.
bias="none", # this specifies if the bias parameter should be trained.
task_type="CAUSAL_LM"
)
Let’s examine the values we’ve set:
- r: This indicates the size of the reparameterization. Keep in mind that the smaller the value, the fewer parameters are trained. Training more parameters gives a better chance of learning the relationship between inputs and outputs, but it’s also more computationally expensive. A value of 16 is a reasonable compromise, allowing us to control parameters while still achieving a correct result.
- lora_alpha: This factor adjusts the magnitude of the weight matrix. In smaller models, it usually doesn’t have a significant impact, but in larger models, it helps to give more weight to the fine-tuning in relation to the rest of the unchanged weights.
- target_modules: This indicates which modules we want to train. It might seem like a challenging decision, primarily because you need to know the internal module names in the model. Fortunately, you can consult the documentation provided by Hugging Face, where it specifies the available modules for each model family.
- lora_dropout: If you’ve trained deep learning models before, you are likely familiar with dropout. It’s used to prevent overfitting. In this case, considering the short training duration and limited data, you could experiment with a dropout value of 0.
- bias: There are three options — none, all, and lora_only. For text classification, none is commonly used. For more complex tasks, you can choose between all and lora_only.
Now, let’s create a directory that will contain the newly fine-tuned model, which needs to be specified as an argument to the TrainingArguments class.
#Create a directory to contain the Model
import os
working_dir = './'
output_directory = os.path.join(working_dir, "peft_lab_outputs")
#Creating the TrainingArgs
import transformers
from transformers import TrainingArguments # , Trainer
training_args = TrainingArguments(
output_dir=output_directory,
auto_find_batch_size=True, # Find a correct bvatch size that fits the size of Data.
learning_rate= 2e-4, # Higher learning rate than full fine-tuning.
num_train_epochs=5
)
The TrainingArguments class receives parameters that we are all familiar with, such as the number of training epochs and the learning rate.
Now we have everything we need to train the model.
- The model.
- TrainingArgs.
- dataset.
- LoRA configuration.
tokenizer.pad_token = tokenizer.eos_token
trainer = SFTTrainer(
model=foundation_model,
args=training_args,
train_dataset=train_sample,
peft_config = lora_config,
dataset_text_field="prompt",
tokenizer=tokenizer,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
trainer.train()
TrainOutput(global_step=65, training_loss=2.7377777099609375, metrics={‘train_runtime’: 404.0462, ‘train_samples_per_second’: 0.619, ‘train_steps_per_second’: 0.161, ‘total_flos’: 966262938697728.0, ‘train_loss’: 2.7377777099609375, ‘epoch’: 5.0})
We can now save this model, which should work correctly.
#Save the model.
peft_model_path = os.path.join(output_directory, f"lora_model")
trainer.model.save_pretrained(peft_model_path)
Test the Fine-Tuned Model.
#import peft
from peft import AutoPeftModelForCausalLM, PeftConfig
#import os
device_map = {"": 0}
working_dir = './'
output_directory = os.path.join(working_dir, "peft_lab_outputs")
peft_model_path = os.path.join(output_directory, f"lora_model")
#Load the Model.
loaded_model = AutoPeftModelForCausalLM.from_pretrained(
peft_model_path,
torch_dtype=torch.bfloat16,
is_trainable=False,
load_in_4bit=True,
device_map = 'auto')
#ask to the fine-tuned mp.
input_sentences = tokenizer("I want you to act as a motivational coach. ", return_tensors="pt").to('cuda')
foundational_outputs_sentence = get_outputs(loaded_model, input_sentences, max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
[“I want you to act as a motivational coach. You will be working with an individual who is struggling in their career and has not been able to find success. The person may have had some previous experience, but they are now looking for new opportunities that can help them achieve more.\nThe client’s current situation”]
I like this response!
Conclusions.
Let’s compare the responses:
- Pretrained Model: I want you to act as a motivational coach. I don’t mean that in the sense of telling people what they should do, but rather encouraging them and helping motivate their own actions.\nYou can start by asking questions like these:\n\nWhat are your goals?\nHow will this help achieve those?\n\nThen.
- Fine-Tuned Model: I want you to act as a motivational coach. I will provide some details about an individual who needs help improving their confidence, and your goal is “Ideas for helping someone improve self-confidence.” Your first suggestion should be “Provide encouragement when they need it most”; my reply
It’s clear that the fine-tuning process has had a positive effect on the structure of the response. The fine-tuned model has generated a response much closer to the prompt we were expecting. I consider the experiment to be a success.
I’m sure that with longer training, it is possible to achieve better results.
You can conduct tests by modifying the training variables and drawing your own conclusions. If you aim for a big challenge, try repeating the exercise by fine-tuning a Mistral 7B model!
Resources.
The full course about Large Language Models is available at Github. To stay updated on new articles, please consider following the repository or starring it. This way, you’ll receive notifications whenever new content is added.
GitHub – peremartra/Large-Language-Model-Notebooks-Course: Practical course about Large Language…
Practical course about Large Language Models. . Contribute to peremartra/Large-Language-Model-Notebooks-Course…
github.com
If you want more information about how QLoRA works: https://arxiv.org/abs/2305.14314
This article is part of a series where we explore the practical applications of Large Language Models. You can find the rest of the articles in the following list:

Large Language Models Practical Course
View list10 stories


I write about Deep Learning and AI regularly. Consider following me on Medium to get updates about new articles. And, of course, You are welcome to connect with me on LinkedIn, and twitter.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")