



Python Statistical Analysis: A Guide to Identifying and Handling Outliers
Last Updated on July 17, 2023 by Editorial Team
Author(s): MicroBioscopicData
Originally published on Towards AI.
Welcome to this tutorial on the detection, plotting, and treatment of outliers with Python. In this tutorial, we will start by discussing what outliers are and why they matter. We will then cover methods for detecting outliers, including a graphical method and statistical tests. Once we have identified outliers in our data, we will explore different approaches for handling them, such as removing them or replacing them. Throughout the tutorial, we will use practical examples and a real-world dataset (Figure 1 -B) to illustrate the concepts and techniques. The dataset named “cells” (can be found here) is based on an experiment where the diameter of cells/spores of the fungus Aspergillus nidulans was measured under the microscope (Figure 1 -A). The dataset consists of a single column of numerical values representing the diameter of the cells in micrometers. By the end of this tutorial, you should have a solid understanding of how to detect and handle outliers in your data, enabling you to produce more robust and accurate analyses and models.
Table of contents:
· What is the source of outliers?
· What is the effect of the outliers?
· Visualize outliers
∘ Boxplot
· Detecting outliers
∘ Z-score method
· Treating outliers
∘ Capping outliers
∘ Trimming outliers
· References:
While there may be variations in its definition, an outlier is typically characterized as a data point that falls well outside the expected range for a given variable or population (Osborne & Overbay, 2004). Outliers are data points that deviate significantly from the rest of the data set. In scientific studies, outliers can have a significant impact on the interpretation of data, as they can skew statistical analyses, affect the accuracy of predictive models, and distort conclusions (Osborne & Overbay, 2004).
What is the source of outliers?
Outliers can be attributed to various mechanisms or factors, including errors in the data, which are often the result of human error, as well as inherent variability within the data itself (Anscombe & Guttman, 1960). The source of outliers can also depend on the specific domain or application. For example, in finance, outliers can be caused by extreme market events, such as stock market crashes or sudden changes in interest rates. In healthcare and biology, outliers can be caused by rare diseases or unexpected responses to treatments.
What is the effect of the outliers?
Statistical analyses can be adversely affected by outliers in multiple ways. Firstly, they can lead to reduced statistical power, for example, by diminishing the probability of detecting a true effect. Secondly, if their distribution is non-random and instead clustered or skewed in one direction, this can result in a non-normal distribution, disrupting normality. Outliers can also distort data visualization, making it difficult to identify patterns or relationships in the data (Osborne & Overbay, 2004).
Visualize outliers
Boxplot
One way to visualize outliers is by using boxplots (Figure 2). Boxplots are a type of graph that shows the distribution of a dataset. They are useful for summarizing the main features of the data in a clear and concise way.
Boxplots are a type of graph that provides a visual representation of the distribution of a dataset through five main summary statistics (Figure 2): the minimum and maximum values, the first and third quartiles, and the median. The box in the plot represents the interquartile range (IQR), which is the range of values that covers the middle 50% of the data (see also below). The whiskers extending from the box indicate the range of the data that is not considered an outlier. Any data points that fall outside of the whiskers are shown as individual points and are considered outliers. Boxplots are particularly useful for comparing the distribution of one variable across multiple groups or conditions, allowing for easy identification of differences in the distribution or presence of outliers.

Python offers several libraries for creating boxplots, including matplotlib and seaborn. Boxplots are a powerful tool for identifying potential anomalies in our data. However, depending on the nature of the data and the research question, there may be other visualizations that are more appropriate for detecting outliers, such as scatterplots, histograms, and violin plots.
The code below is an example of how to create boxplots (Figure 3) in Python using the matplotlib and seaborn libraries to visualize outliers in the “cell” dataframe.
#Importing libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#Importing "cell" dataframe
df = pd.read_csv("cells.csv", index_col="Cell ID")
fig, [ax1,ax2] = plt.subplots( nrows=1, ncols=2, figsize=(7,5))
# Create a boxplot using Matplotlib
ax1.boxplot(df['Diameter (micrometer)'])
# Add labels and title
ax1.set_xlabel("Data", fontsize=12)
ax1.set_ylabel('Cell diameter', fontsize=12)
ax1.set_title('Boxplot using Matplotlib', fontsize=14)
# Create a boxplot using Seaborn
sns.boxplot(y=df['Diameter (micrometer)'],ax =ax2)
# Add labels and title
ax2.set_xlabel("Data", fontsize=12)
ax2.set_ylabel('Cell diameter', fontsize=12)
ax2.set_title('Boxplot using Seaborn', fontsize=14)
# The plt.tight_layout() function is called to fit the plots within the figure cleanly.
# The pad parameter controls the padding between the subplots
plt.tight_layout(pad=3.1)
fig.suptitle("Visualizing outliers using boxplots", fontsize=20, y=1.01)

Detecting outliers
Z-score method
One of the commonly used methods for detecting outliers is the z-score method. The z-score method is based on the concept of standard deviation, which measures the amount of variation or dispersion of a set of data from its mean. The z-score transformation calculates the number of standard deviations an observation is away from the mean of the dataset. Typically, observations that have a z-score greater than 3 or less than -3 are considered outliers. This is because, in a normal distribution, approximately 99.7% of the data falls within three standard deviations of the mean. Therefore, any observation that is more than three standard deviations away from the mean is considered an outlier.
To use the Z-score transformation for outlier detection:
- Calculate the mean and standard deviation of the dataset.
- For each observation, calculate its z-score using the formula: z = (xi — μ) / σ, where x is the observation value, μ is the mean of the dataset, and σ is the standard deviation of the dataset.
- Identify any observations with a z-score greater than 3 or less than -3.
The z-score transformation is often used in outlier detection because it provides a way to identify observations that are significantly different from the rest of the data.
The code below calculates the z-scores for the “Diameter (micrometer)” column in the “df” DataFrame. First, it calculates the mean and standard deviation of the column using the “.mean()” and “.std()” methods, respectively. Then it calculates the z-score for each observation in the column using the formula “z = (xi — μ) / σ”, where xi is the observation, μ is the mean, and σ is the standard deviation. It assigns the z-scores to a new column in the DataFrame called “Z-score”. Next, it identifies any observations with a z-score greater than 3 or less than -3 using boolean indexing with the “U+007C” operator (logical OR) to find rows where the z-score is greater than 3 or less than -3. The resulting DataFrame is printed to the console. Finally, it creates a histogram (Figure 4) of the “Diameter (micrometer)” column using the Seaborn library’s “histplot” function and plots it using Matplotlib with the specified figure size. The histogram shows the distribution of the “Diameter (micrometer)” data and can help identify any potential outliers in the dataset.
#Calculate the mean
mean = df['Diameter (micrometer)'].mean()
#Calculate the Standard deviation
std =df['Diameter (micrometer)'].std()
# Calculate z-scores and asign them to a new column
df["Z-score"] = (df['Diameter (micrometer)']-mean)/std
# Find observations with a z-score greater than 3 or less than -3
print(df[(df["Z-score"]>3) U+007C (df["Z-score"]<-3)])
fig,ax = plt.subplots(figsize=(9,6))
# Plot histogram using Seaborn library to show distribution of dataset.
sns.histplot(x=df['Diameter (micrometer)'], data = df, ax=ax)

The Interquartile Range (IQR) method:
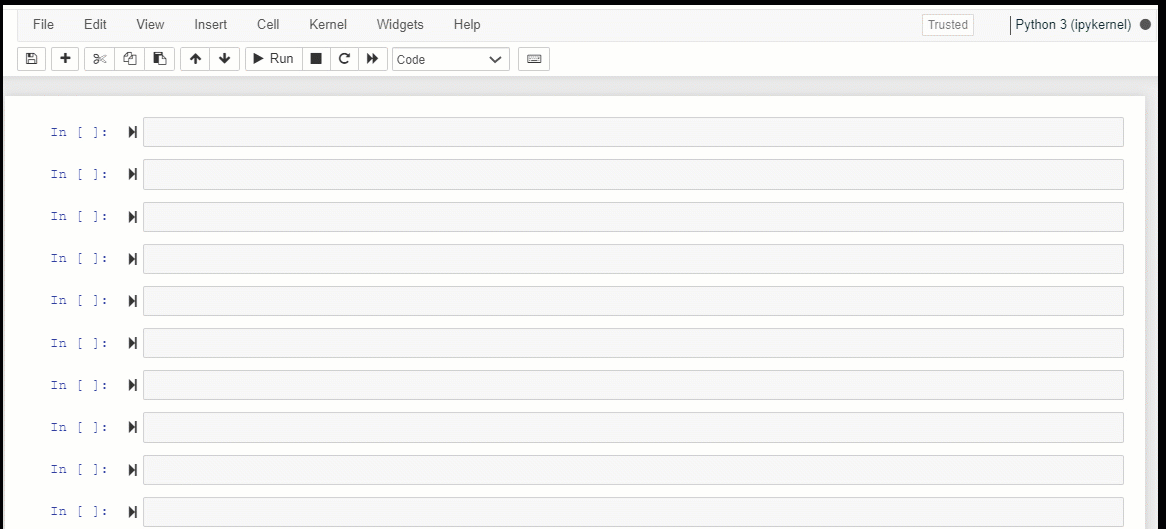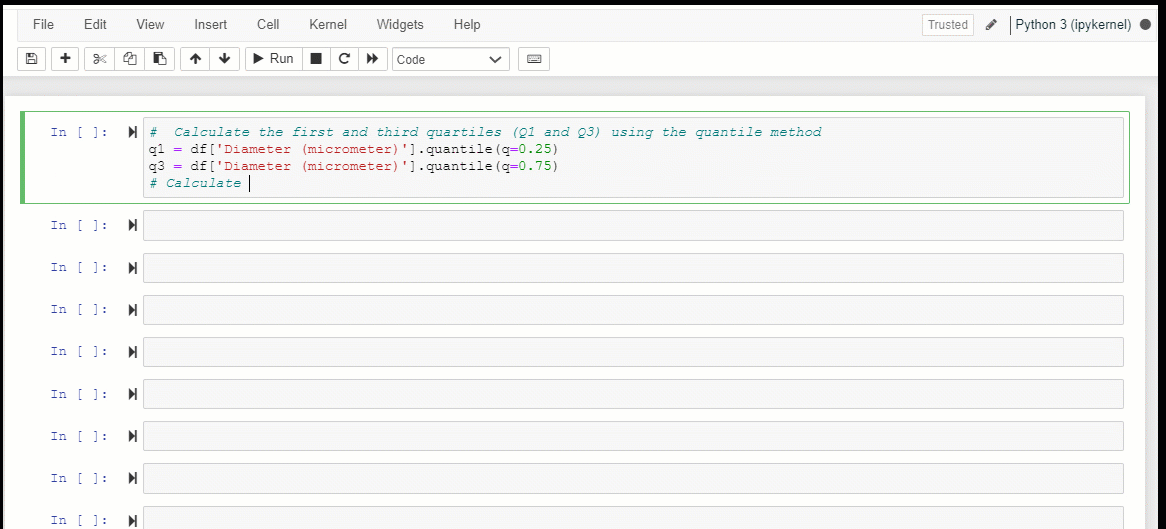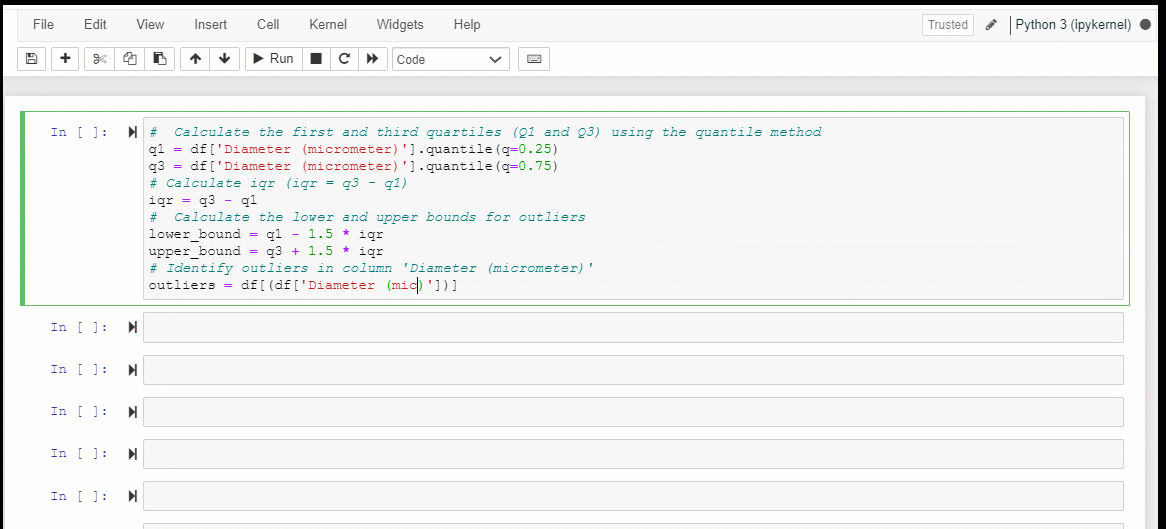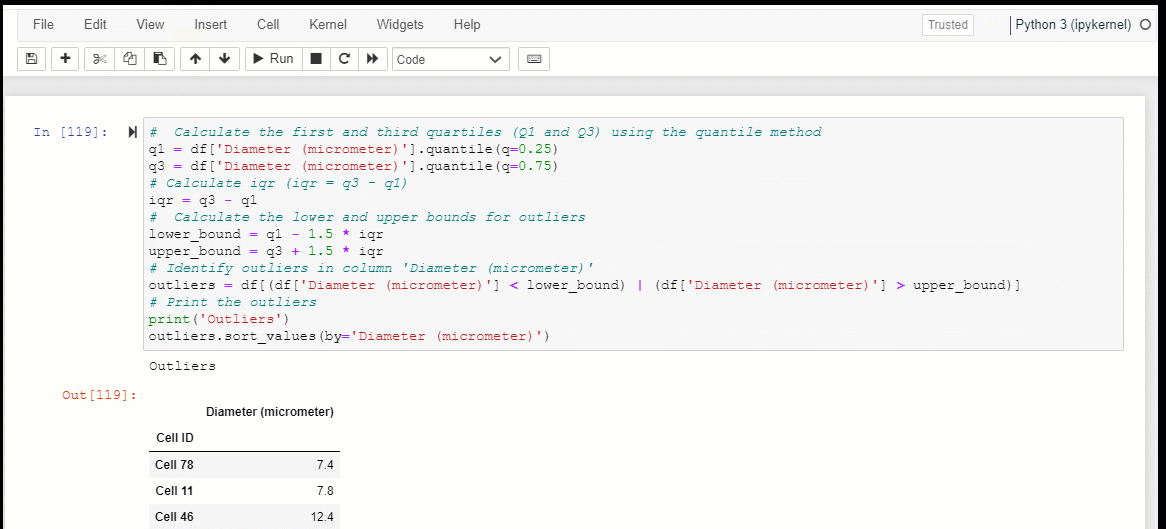
However, the Z-score method is only valid if the distribution of the original data is normal or approximately normal, with a bell-shaped histogram. The Interquartile Range (IQR) method is a commonly used method for detecting outliers in non-normal or skewed distributions. To apply the IQR method, first, order the dataset from smallest to largest. Next, calculate the first quartile (Q1) by finding the median of the lower half of the dataset. Then, calculate the third quartile (Q3) by finding the median of the upper half of the dataset. The interquartile range (IQR) can be calculated by subtracting Q1 from Q3: IQR = Q3 — Q1. The upper and lower whiskers can be defined as 1.5 times the IQR added to Q3 and subtracted from Q1, respectively. Any data points beyond the whiskers are considered outliers and should be plotted as individual points. A box plot can be generated using the calculated values for Q1, Q3, the IQR, and the whiskers to visualize the distribution and any detected outliers.
The IQR method is a simple and effective way to detect outliers in a dataset, particularly in cases where the data is non-normal or skewed. In contrast, the Z-score method may not work well in these situations. Here’s an example of how to implement the IQR method to detect outliers in Python:
Treating outliers
Treating outliers is an important step in data preprocessing to improve the accuracy and reliability of statistical analyses and machine learning models. Two common methods of treating outliers are capping and trimming.
Capping outliers
Capping involves setting the values of outliers to a specified upper or lower limit. This is done in order to reduce the impact of outliers on statistical analysis or machine learning models. The capping method is useful when the outliers are believed to be due to measurement errors or data entry errors. There are different ways to cap outliers in a dataset. One way is to replace the outliers with the maximum or minimum value of the range of acceptable values (Figure 6). Another way is to set the outliers to a specific percentile of the distribution. The percentile method is often used when the dataset has a skewed distribution.
Below is the code demonstrating how to perform capping of outliers in Python:

Trimming outliers
Trimming outliers is a method of removing extreme values from a dataset by simply removing them from the dataset. This is different from capping outliers, which replace extreme values with a predetermined value, such as the maximum or minimum value in the dataset or a user-defined cutoff. The idea behind trimming outliers is that extremely high or low values in a dataset may not be representative of the population being studied and may skew the results of statistical analysis. By removing these extreme values, the data can be made more normally distributed and better suited for analysis. However, it is important to note that trimming outliers can also result in a loss of information and a potential bias in the analysis. Therefore, the decision to trim outliers should be made carefully and based on a sound understanding of the data and the research question at hand.
Below is the code demonstrating how to perform trimming of outliers in Python:

In conclusion, outliers play a crucial role in scientific research. While they can be problematic for statistical analyses and interpretation of data, they can also provide valuable information and insights. Scientists should carefully consider the presence and significance of outliers in their data and make informed decisions about how to handle them in their analyses. In many scientific studies, outliers are treated with caution and may be removed from the analysis if they are deemed to be an anomaly. However, removing outliers can also be controversial, as it may introduce bias into the analysis and potentially obscure important patterns or relationships in the data. Thus, it is important for scientists to carefully evaluate the significance of outliers in their data and make informed decisions about whether to include or exclude them.
I have prepared a code review to accompany this blog post, which can be viewed in my GitHub.

References:
Anscombe, F. J., & Guttman, I. (1960). Rejection of Outliers. Technometrics, 2(2), 123–147. https://doi.org/10.2307/1266540
Osborne, J., & Overbay, A. (2004). The Power of Outliers (and Why Researchers Should Always Check for Them). Pract. Assess. Res. Eval., 9.
X Cohen, M. (2023). Master statistics & machine learning: Intuition, math, code. https://www.udemy.com/course/statsml_x/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

