



Precision vs Recall. What Do They Actually Tell You?
Last Updated on July 8, 2022 by Editorial Team
Author(s): Nikita Andriievskyi
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Understand the idea behind Precision and Recall
If you asked any data scientist or machine learning engineer about the easiest and most confusing topic they learned — one of the first things that would come to their mind would be Precision vs Recall.
On the one hand, this topic is indeed confusing, and I myself spent a ton of time trying to understand the difference, and most importantly, what these two terms tell you.
On the other hand, the topic is very simple and requires no understanding of math, programming, or anything else complex. And in this article, I will combine all resources that I’ve come across, and I will do my best in explaining the topic to you so that you don’t have to ever worry about it anymore.
First of all, we have to understand that Precision and Recall are other ways to evaluate your model. Often, a simple accuracy measurement is not going to suffice.
Why can’t I just use accuracy?
Let’s say you have a dataset of 1000 fruit images, 990 apples, and 10 oranges. You trained a model to classify apples vs oranges on this dataset, and your model decided to say that all the images are apples. If you compute the accuracy (correct predictions / all predictions): 990/1000, then you would get an accuracy of 99%!! Even though your model has amazing accuracy, it completely misclassifies all oranges.
But, if we also evaluated the model using Precision and Recall, we would get humbled immediately.
Before going into the explanation of the two terms, we do have to know what True Positive, True Negative, False Positive, and False Negative mean.
Note: If you already know the difference perfectly, you can skip this part
Let’s first look at the True “class”.
True here means that the model predicted correctly.
- So, if we created a model to classify images of dogs vs not dogs — a True Positive prediction would be when the model classified an image as a dog, and it was indeed a dog.
- A True Negative prediction would be if the model classified an image as not a dog, and it was actually not a dog.
What about the False class?
As you might have guessed, False means that the model predicted incorrectly.
- False Positive— the model classified an image as a dog, but it was actually not a dog.
- False Negative — the model classified an image as not a dog, but it was actually a dog.
As you see, True and False tell you if the model was right or wrong. Whereas Positive and Negative tell you what class the model predicted. (In our example, the Positive class was dog images, and the Negative class was non-dog images)
NOTE
The Positive class doesn’t necessarily have to be images of dogs, you could also say that the Positive class is images of not dogs. But mostly, data scientists refer to Positive as the class that they target/focus on.
Hopefully, by now you understand the previous part well because we are going to need it in understanding Precision vs Recall.
Precision
Let’s say we’ve created a model to classify images of dogs vs not dogs, and we tested our model on 10 images, let’s focus on the dog class:
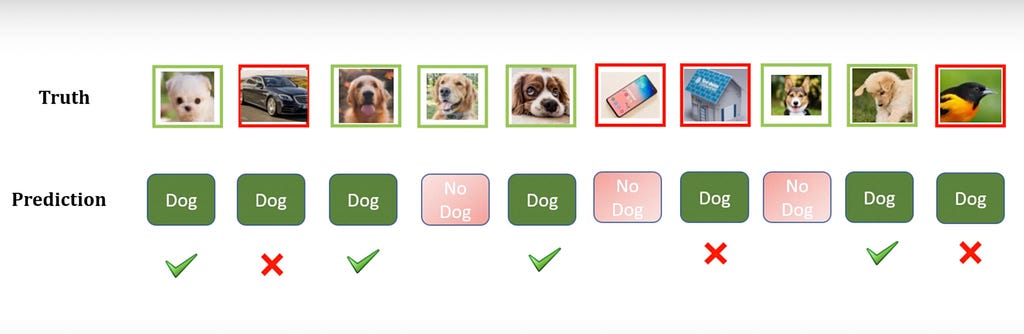
Let’s see… There are 6 images of dogs, and 4 non-dog images. Our model classified 7 images as a dog, however, only 4 of them are correct.
The formula for Precision:
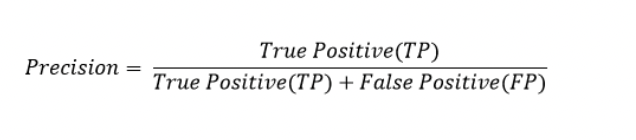
Let’s compute Precision for the dog class together: there are 4 True Positive images (4 dog images that were classified as dogs). Now we divide it by 4 True Positives + 3 False Positives (3 images of not dogs that were classified as dogs).
4/7= 0.57.
What does it tell us?
Well, basically, it tells us what percentage of dog images was classified correctly among all images classified as dogs.
When we calculate Precision, we focus on the predictions.
If we have 100% Precision, we can be 100% sure that If our model classifies an image as a dog, it’s definitely correct. Even if it has not classified most dog images as dogs, those that are classified as dogs — are 100% correct. In Precision, we only care about the predicted targeted class being correctly classified.
Recall
Let’s keep the same example, I will attach the same photo, so you don’t have to scroll up again:
The formula for Recall:

Let’s compute it together: 4 True Positives divided by 4 True Positives + 2 False Negatives (2 images of dogs that were classified as not dogs).
4/6 = 0.67
What does it tell us?
So, if Precision showed us the percentage of dog images that were correctly classified among predicted images of dogs— Recall shows us the percentage of dog images correctly classified among actual images of dogs.
When we calculate Recall, we focus on the actual data.
If we have a 100% Recall, we can be 100% sure that if given a set of, let’s say, 20 images, 8 of which are dog images, our model will classify all 8 dog images as dogs. However, it might also say that the other 12 images are dogs too, but in Recall we only care about the actual targeted images being classified correctly.
Precision vs Recall Tradeoff
I won’t focus on this topic a lot, if you want me to write a post about it, do let me know in the comments. But basically, usually, when the Precision goes up, the Recall goes down, and vice versa.
How do I know what I need to focus on more? (Real-world examples)
You might have a question like: “Okay, I understand the difference, and that there is a tradeoff, but when do you I need a higher precision, and when do I need a higher recall?”
When do we care about Precision more?
Let’s imagine we are working for Google, specifically, we are working on a model that will detect email as spam vs not spam, and all spam emails will be hidden. In this case, we don’t want to accidentally classify an important email as spam, since it will be hidden. Therefore, we want to be sure that if the model classifies an email as spam, it’s correct. We don’t really care if some spam emails won’t get hidden from the user, they will be able to hide it on their own. Take a while to process it, and try to understand how Precision fits the example.
What about Recall? When do we focus on it more?
Let’s imagine we are working at an airport, and we have built a model to classify dangerous people. If our model doesn’t classify a dangerous person as a dangerous person, they might get undetected by security too, and then cause a lot of damage. This is why we need to classify every dangerous person as a dangerous person.
On the other hand, if the model classifies a regular civilian as dangerous, we don’t really care, they will get checked, and then move on.
Exercises
- Take the example data with dogs vs not dogs, and try to calculate Precision and Recall for the not a dog class. (Think of the not a dog class as your Positive class).
- Try to come up with your own definition for Precision and Recall.
- Think of a project or even a real-world problem where Precision would be more important, and vice versa.
- Let me know your answers in the comments, and I will tell you if you are right or wrong.
I do hope this article helped you, I tried to make everything as clear as it can get. But if you still have some questions, do ask them in the comments, and I will try to help you.
Precision vs Recall. What Do They Actually Tell You? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

