



Paper Review: Summarization using Reinforcement Learning From Human Feedback
Last Updated on July 25, 2023 by Editorial Team
Author(s): Building Blocks
Originally published on Towards AI.
AI Alignment, Reinforcement Learning from Human Feedback, Proximal Policy Optimization (PPO)
Introduction
OpenAI’s ChatGPT is the new cool AI in town and has taken the world by storm. We’ve all seen countless Twitter threads, medium articles, etc., that highlight the different ways ChatGPT can be used. Some developers have already started to build applications, plugins, services, etc., that leverage ChatGPT.
While the exact workings of ChatGPT aren’t yet known since OpenAI hasn’t released a paper or open-sourced their code yet. We do know that they leverage the idea of Reinforcement Learning from Human Feedback (RLHF)
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
In today’s article, we’ll dive into a prior work of OpenAI where they used RLHF to learn to summarize documents. This article will consist of the following sections.
- Dataset Creation
- Supervised Fine Tuning
- Training a Reward Model
- Reinforcement Learning
- Partial Policy Optimization
What are the datasets?
OpenAI creates a dataset by sampling from the Reddit TL;DR dataset. This dataset consists of posts followed by a TL;DR written by the creator of the post. The TL;DR is treated as the summary of the original post.
The original TL;DR dataset consists of 3 million posts. However, OpenAI runs a few filters for quality and also filter summaries that are between 24 to 48 tokens long. The reason for the length filter is to limit the influence of the length of a summary in determining its quality. Post filtering, their dataset contains 123,169 posts, out of which 5% is used as a validation set.
In the image above, you can see the distribution of posts and the subreddits that they are from. OpenAI has also made the dataset publicly available here.
Methodology
At a high level, the methodology consists of the following three primary steps:
- Supervised Finetuning (SFT)
- Creating a Reward Model
- Train a Reinforcement Learning Model that leverages the Reward Model.
Supervised Finetuning (SFT)
This step is similar to the fine-tuning step of any pre-trained transformer model so that it can make task-specific predictions. In this particular case, the authors train the model to predict/generate the summary given the post.
Instead of using an out-of-box pre-trained transformer model, they reproduce the standard transformer architecture and pre-train it to predict the next token. They use the following corpora for pre-training:
- CommonCrawl
- WebText
- Books
- Wikipedia
The input sent to the transformer model for predicting the summaries follows the template shown below:

Creating a Reward Model
Fundamentals of Reinforcement Learning
The idea behind Reinforcement learning (RL) is that an agent learns from the interactions it has with the environment/world that it is acting in. An example of an agent that learns from RL is a game like Pacman. The agent can choose to move in certain directions with every action it takes. The agent may receive some feedback from the environment as it makes certain actions. The feedback could be an increasing number of points, being killed, etc.
The feedback received is termed a reward, and all the information that the agent can perceive and utilize to decide on what action to take next is referred to as the observed state. In RL, the goal of an agent is to maximize the reward it can receive. A single action taken by an agent is referred to as a step, and a series of steps that lead to the end of a game is referred to as an episode.
In the context of summarization, the observed state is the textual content of a post, and the actions that the agent can take are to output a token one by one (per step) and generate a summary per episode. However, we need to find a way of rewarding the agent at the end of an episode. The reward needs to be a scalar value. In RLHF, we train a reward model that judges the output of our agent and provides a score that is used as the reward.
Collecting data for a Reward Model
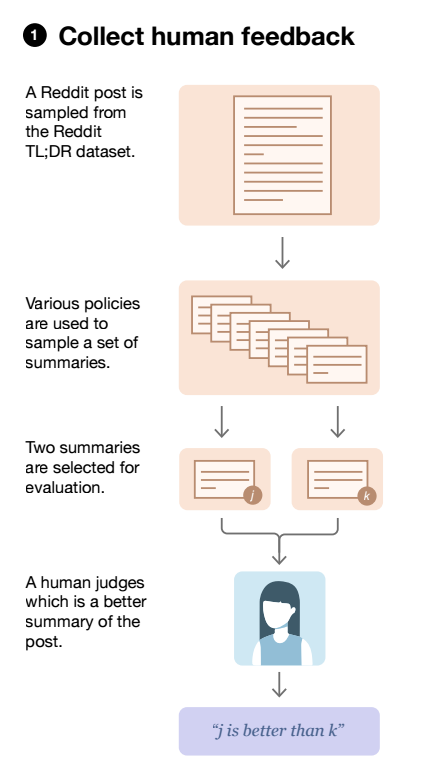
To train a reward model, the authors sample a post from their dataset and then obtain a bunch of summaries. Some of the ways they obtain summaries for a given post are:
- Sample from the SFT model
- Sample from the Pre-trained model without SFT by passing in some in-context examples of summarization.
- Use the ground truth summary written by the creator of the post.
A new task is created by taking pairs of summaries for a given post and asking contracted labelers to choose which summary they prefer between the two.
Training a Reward Model
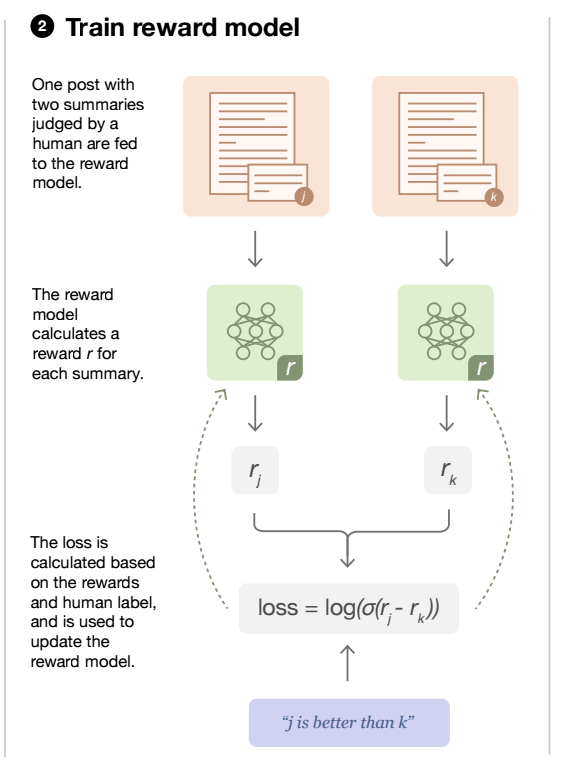
To obtain a reward model, the model resulting from SFT is used as a starting point, and the layer used to predict the tokens is replaced with a new head (linear layer) to obtain a scalar score for a post + summary document sent to the reward model. Keeping with our dataset created above, both of the candidate summaries for a given post are individually passed to the reward model to obtain a score for each summary.
The model is trained to maximize the difference in scores between the preferred summary and the other candidate summary or, in other words, minimize the negative difference in scores. This can be observed in the loss function shown below where y_i corresponds to the preferred human summary, y_(1-i) corresponds to the other candidate summary and, x corresponds to a post, r corresponds to our reward model, D corresponds to our dataset from which samples are drawn.

Great now we have a reward model that should produce high scores for good summaries and low ones for bad summaries! The next step is to leverage the reward model in an RL environment.
Reinforcement Learning Using Proximal Policy Optimization
Fundamentals of Proximal Policy Optimization
A policy in RL determines what action(a) an agent should take given a state(s). A policy is often represented by the symbol π. In the context of this paper, our initial policy is our transformer model that generates a summary.
In RL, we’re trying to learn the best possible policy so that our agent can get the highest reward possible. We update our policy by updating the weights of our summarization model at the end of each episode. An episode in the context of this paper would be a batch of posts for which our policy generates summaries. PPO is an algorithm that focuses on how to update the parameters corresponding to our policy. The loss for the policy model can be represented by the following three equations :

Based on equation 1 we want to find the ratio between the probability of taking some action a for a given state s based on our current policy and the probability of taking the same action a, for the same state s according to our previous/old policy.
The idea behind Proximal Policy Optimization (PPO) is that we want to avoid changing the policy drastically in a single step. The perils of changing the policy too drastically are that the agent might forget what it learned so far and end up in a space where performance is very low, and re-learning what it forgot could take a lot of time. The ratio computed from equation 1 gives us an idea of the magnitude of the change in the policy.
The Advantage function depicted in equation 2 is a measure of how much better or worse taking action a at state s is compared to the average reward expected at that state. Essentially it is a way of telling whether we are taking a good action or not. If you’re unfamiliar with Q-values and the Value function, I’d recommend diving into the RL course created by Huggingface, linked in the reference section.
In equation 3, the clip function binds the values of the ratio between the range of 1-epsilon and 1+epsilon, epsilon is usually a constant value in the range of [0.1–0.2]. The Loss function L_ppo ensures that the gradient is 0 when:
- Ratio < 1-epsilon and Advantage < 0
- Ratio > 1+epsilon and Advantage > 0
To sum up those two cases up, we don’t want to update our policy any further if we are already aware that the action we are taking is pretty good or pretty bad and update it in all other cases. If you’re unclear on why the gradients would be zero for the above two cases, please refer to this article.
Updated Reward Equation
The authors of the paper also add a KL divergence penalty to ensure that the updated policy doesn’t diverge too far from the original SFT model. This is to ensure that the model doesn’t find a way of maximizing the reward function by cheating and producing an incoherent summary. It also ensures that the output summaries generated by the new policies aren’t too dissimilar from what the reward model was trained on.
The final equation for the Reward is
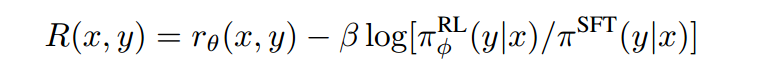

The PPO-Clip algorithm can follow an Actor-Critic based training paradigm. The Critic is responsible for giving us the Q-values (Q(s, a)) also referred to as a Value function. The value function is represented by another Transformer model initialized with the same weights as the reward model.
Since the authors don’t mention any other information regarding the Value function, we assume that they optimize it by minimizing the difference between the Value function’s predicted reward and the actual reward provided by the Reward function.
To summarize, we have three different models:
- Policy Model
- Reward Model
- Value Function Model
All three models are based on the transformer architecture.
Conclusion
The authors of the paper make the following conclusions based on their experiments:
- “Training with human feedback significantly outperforms very strong baselines on English summarization.” : This was based on the evaluations run by the labelers.
- “Human feedback models generalize much better to new domains than supervised models”: This is based on the performance of the model trained on the TL;DR dataset against the CNN/DailyMail dataset.
In today’s article, we discussed how Reinforcement Learning from Human Feedback could be used in an NLP setting to summarize documents. If you have any queries or thoughts on the paper, please do drop a comment.
References
- Huggingface DeepRL Class
- Proximal Policy Optimization (PPO)
- https://towardsdatascience.com/proximal-policy-optimization-tutorial-part-1-actor-critic-method-d53f9afffbf6
- https://github.com/openai/summarize-from-feedback
- https://openai.com/blog/learning-to-summarize-with-human-feedback/
- https://keras.io/examples/rl/ppo_cartpole/
- https://spinningup.openai.com/en/latest/algorithms/ppo.html
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

