



Paper Review: InstructOR One Embedder, Any Task
Last Updated on January 10, 2023 by Editorial Team
Author(s): Building Blocks
Originally published on Towards AI.
Towards Task-Specific Embeddings
Introduction
If you’ve ever worked on building a deep learning model for any sort of text-related task such as classification in the past few years you would’ve taken some pre-trained transformer model such as BERT and finetuned it against your dataset.
In some cases, you might’ve also pre-trained your model on the type of documents that you’d expect the model to see during test time or when it is in production so that the model can adapt to this new domain.
A major problem with these approaches is that they don’t scale well, especially in the real world, where you might want to create multiple models. For example, take the case of Medium. They might want to have models that can identify the topics and sub-topics of blogs, check for plagiarism, quality, and if it contains any harmful/adult content.
It is also likely that companies/organizations need more than just classification models. They might want models for other tasks such as semantic search, similar document retrieval for things like recommendation engines, question-answering models for FAQ chatbots, etc.
In reality, it can be common for a company to deploy hundreds of different models that solve different problems. Re-training and deploying these relatively large and numerous models is time and resource-consuming. Wouldn’t it be great if we had a single model that could generate different embeddings for different tasks even though the document is the same?
This is exactly the problem the authors of InstructOR solve. In today’s article, we will detail what the InstructOR model is and how it works. In keeping with the trends of InstructGPT and ChatGPT, the authors leverage the use of human-generated instructions.
What does InstructOR do?
InstructOR stands for Instruction-based Omnifarious Representations.
omnifarious (adjective) : of all varieties, forms, or kinds
Huff, that’s a mouthful. Let’s break it down.
- The model’s embeddings are the way it represents a document.
- The model is given instructions/descriptions of the task the embeddings will be used for, along with the document that it should embed.
- Since a single document can be represented uniquely for each task (instruction) that is provided, it means that we can solve a large variety of tasks.
Ultimately, InstructOR is capable of generating task-specific embeddings for a given document.
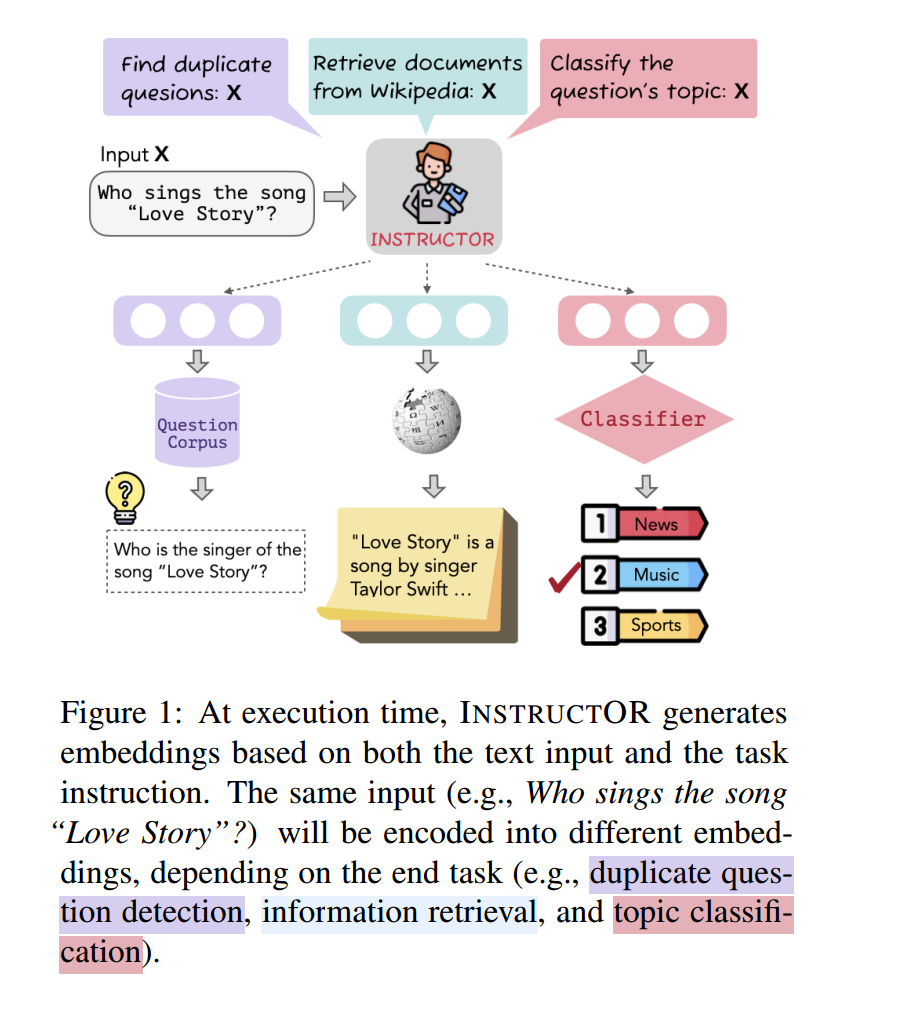
As can be seen from the image above, let’s say we have a document, “Who sings the song Love Story?” we assume that we want to solve three different tasks.
- Identify duplicate questions
- Retrieve the relevant document from Wikipedia that can answer the question
- Classify the question under a topic
By passing in a different natural language instruction/description of the task for the same input document, we obtain 3 unique embeddings!
How was InstructOR trained?
Model Architecture
InstructOR uses Generalizable T5-based dense Retrievers GTR models. GTR models have shown good performance in retrieval-based tasks. T5 models have an Encoder-Decoder style architecture; however, GTR models only use the encoder of T5.
The GTR models are initialized from T5 models, pretrained on a web corpus, and fine-tuned on information search datasets
Training Process and Loss Function
As mentioned before Instructor takes in two inputs:
- The Instruction that explains the task and domain
- The document
To generate useful embeddings where the embeddings of similar documents are close to each other in the vector space, the authors leverage contrastive learning.
It is important to note that the notion of similarity changes with the task at hand. For example, if we are working on Sentiment Classification, we’d say that it is possible that documents with the same sentiment are more similar than documents with opposing sentiments.
During training, the model is provided with a pair of instructions and documents. Assuming that x, y are documents and I_x, I_y are instructions of how x and y are to be used, InstructOR is tasked with producing two embeddings and identifying if the pair of embeddings for (I_x + x) and (I_y + y) are similar or not.
The embedding E corresponds to the mean of all tokens belonging to the document x, note that the embeddings of the instruction tokens are not considered. The similarity is determined by computing the Cosine Similarity between the two embeddings.
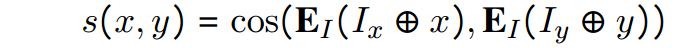
Determining Ground Truth
- For classification tasks, a positive pair comprises documents belonging to the same class. In such tasks, the Instruction for both documents would be the same.
- For retrieval tasks, we have a query document and a candidate document. Each of them has its instruction because we want query embeddings to be different from candidate embeddings. In these scenarios, a positive pair is if a given candidate is relevant to the query.
- For textual similarity tasks such as duplicate questions, a positive pair consists of two documents that are either structurally and semantically similar or/and originate from the same source.
Loss Function
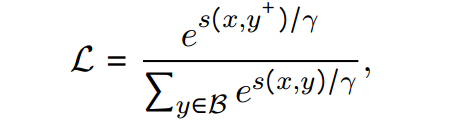
The goal is to maximize the similarity between positive pairs and minimize the similarity between negative pairs. It can be seen that the denominator is the summation of the similarity of the positive pair + all negative pairs.
From the image above, it can be seen that the loss function is essentially the Cross-Entropy Loss function. The major difference is the use of cosine similarity scores instead of logit scores. Where the positive, positive pair is treated as the true label, and all the negative pairs are treated as negative labels.
Annotating Instructions
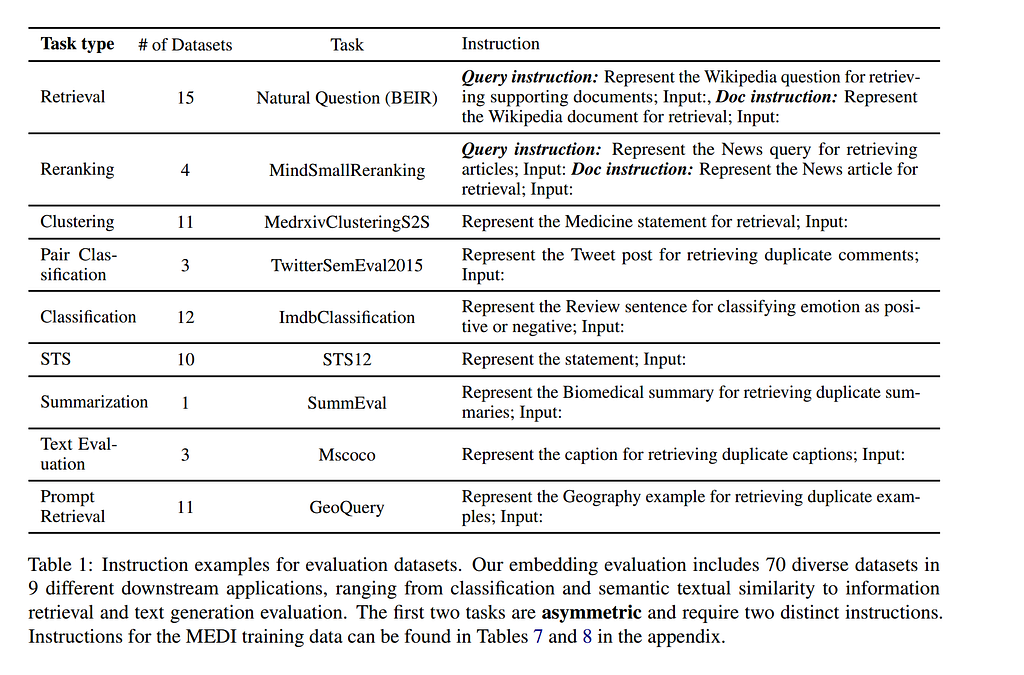
The authors created a template for generating instructions for all of the different tasks that the model was trained on. The template follows the following structure:
REPRESENT THE (DOMAIN) TEXT TYPE FOR THE TASK OBJECTIVE; INPUT:
The words in bold are placeholders in the template:
DOMAIN: Refers to the domain of the task. For example, if we were classifying news articles into different topics, the domain would be news. This field is optional since some tasks might span multiple domains.
TEXT TYPE: This field states what type of text we’re embedding, such as a post, query, document to be retrieved, etc.
TASK OBJECTIVE: This states the task that we’re trying to solve, such as summarizing, classifying emotion, etc.
Some of the instructions for certain datasets and tasks in the evaluation set can be seen in the image below.
Datasets
For training, the authors collect 330 different datasets and combine them to form a single dataset that they name Multitask Embeddings Data
with Instructions (MEDI). The datasets span multiple task types and domains.
For evaluating their model, they leverage the Massive Text Embedding Benchmark (MTEB).
MTEB is a massive benchmark for measuring the performance of text embedding models on diverse embedding tasks. MTEB includes 56 datasets across 8 task.
An important thing to point out is that out of the 70 different evaluation tasks, 66 of these tasks were unseen during training. This means that the model can generalize well enough to perform well on tasks that it hasn’t seen before! An unseen task could also correspond to a new instruction that wasn’t seen during training, meaning that the role instructions play can also be generalized by the model.
Another point to note that is tasks like retrieval, ranking, etc. just need the embeddings from the model. For classification tasks, you’d still need to freeze the InstructOR model and train a Multi-Layer Perceptron on top of the embeddings produced by InstructOR to obtain the predicted class label.
However, given that MLPs are much smaller in size, the amount of time and memory resources consumed in training them is far less compared to re-training an entire transformer model, this approach is still a win.
Hyperparams
The authors train three models:
- GTR-Large with 330 million parameters
- GTR-XL with 1.3 billion parmaeters
Finetune it on MEDI using the AdamW optimizer with learning rate 2e-5 and warmup ratio 0.1. We use a softmax temperature of 0.01 and finetune INSTRUCTOR for 20K steps.
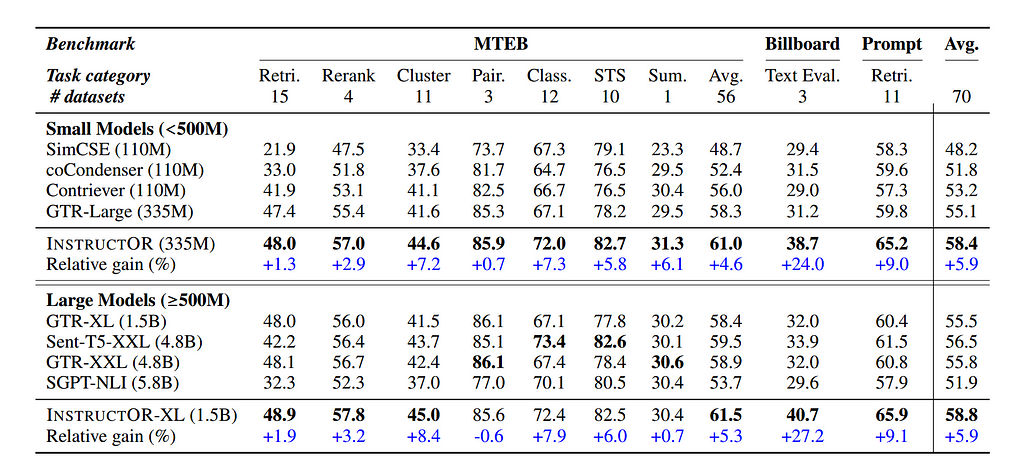
To put that in context, GPT-3 has 175 billion parameters, and InstructGPT has 1.3 billion parameters. Interestingly, the authors found that the smallest model, GTR-Large, with 330 million parameters, outperformed existing benchmarks on a large number of tasks and performed competitively on the ones it didn’t top. Instructors is on top of the MTEB leaderboard on average across all tasks.
Analysis and Ablation Studies
Instruction Robustness
To prove that InstructOR can perform well even if instructions are phrased in different ways, the authors ran experiments by evaluating (not training) the model using five different paraphrased instructions compared to the ones used at training time.
They find that there isn’t much of a difference in performance across the 5 paraphrased instructions.
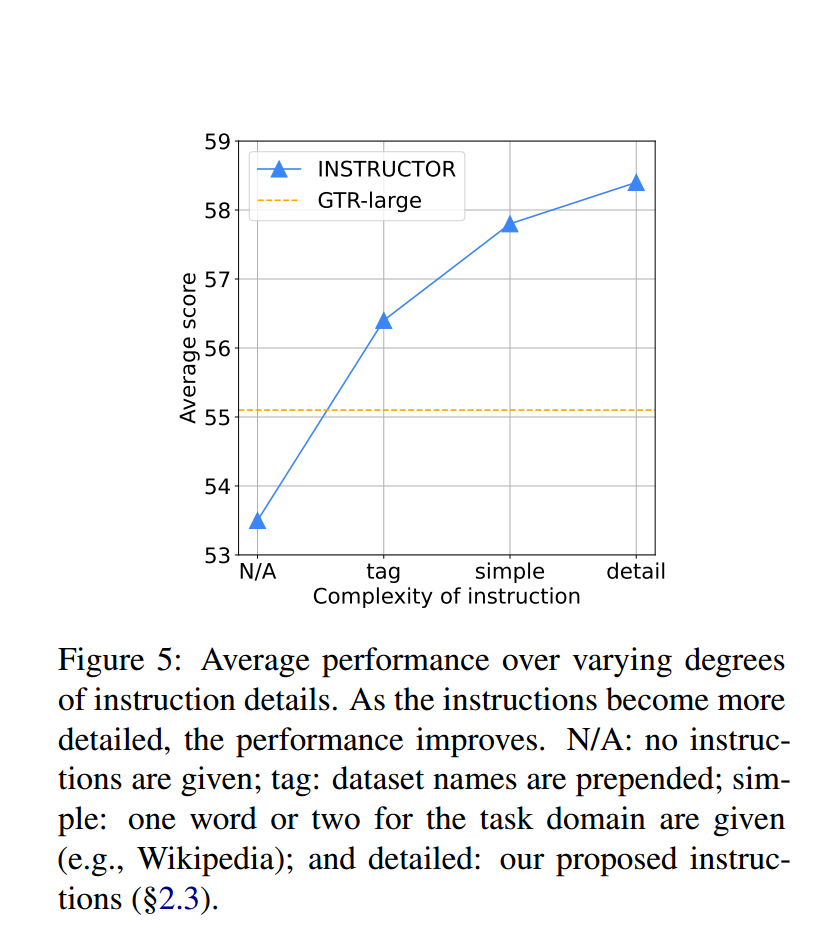
Complexity of Instructions
In another experiment, they show that the more detailed the instructions are, the better the model performs.
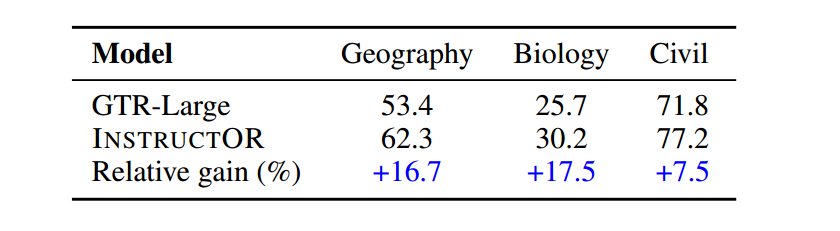
Performance on Unseen Domains
The authors also show that InstructOR embeddings can generalize better to domains of data that haven’t been seen during training time. This means that we can expect good performance without having to fine-tune the model against new domains.
Embedding Visualization
The authors visualize their embeddings using T-SNE to show how the distance between documents change based on the instructions provided. As can be seen below on providing instructions the documents that share the same sentiment are closer together, while the one’s with different sentiments move further apart!

Conclusion
In today’s article, we detailed how InstructOR can be used to generate task-specific embeddings. Some key takeaways are:
- InstructOR can generalize well to unseen tasks and domains of data meaning that we don’t need to fine-tune models on new tasks and domains.
- InstructOR shows robustness to the different ways instructions can be phrased, and performance improves with how detailed instructions are.
- InstructOR is a relatively small model with just 330 million parameters, making the expense associated with deploying such a model relatively less compared to others.
If you have any other thoughts you’d like to share please drop a comment below. Until the next time, take care and be kind.
Additional Resources
Paper Review: InstructOR One Embedder, Any Task was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

