


NLP News Cypher | 08.23.20
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 08.23.20
Fury
What a week. Let’s recap. If you haven’t heard, we released the NLP Model Forge U+1F648 , plus AI can now beat you in a dogfight, and Operation Fury is underway. If you enjoy this newsletter please follow us here on Medium, and also don’t forget to give it a clap U+1F44F.
To further comment on Fury, for those looking to intern in the short term, we have a position available to work in an NLP deep learning project in the healthcare domain. If this interests you and you have experience with deep learning modeling (and robust software engineering prowess), please reach out to us via info [at] quantumstat[dot] com.
NLP Model Forge
So… the NLP Model Forge, a collection of 1,400 NLP code snippets that you can seamlessly select to run inference in Colab! Why use the Model Forge?! Well, you can find out in our blog post here U+1F447 :
The NLP Model Forge
Unlocking Inference for 1,400 NLP Models
medium.com
Chains
In addition, here’s a Colab called chains. A notebook we created using the quick versatility of the Forge, showing how to link models together in a single pipeline for inference.
Google Colaboratory
Edit description
colab.research.google.com
DARPA’s Air Combat Evolution Program:
AI’s got the need for speed…
Artificial Intelligence Easily Beats Human Fighter Pilot in DARPA Trial – Air Force Magazine
The Heron Systems AI algorithm swept a human F-16 pilot in a simulated dogfight in DARPA's AlphaDogfight Trials on Aug…
www.airforcemag.com
Photo of the Week: Titanic crypto
This Week
Sentence Transformers
txtai: AI-Powered Search Engine
Fine-tuning Custom Datasets
Data API Endpoint With SQL
It’s LIT U+1F525
Broadcaster Stream API
Fast.ai New Release
Dataset of the Week: DialogRE
Sentence Transformers
If you wish to use sentence embeddings from SOTA NLP models in an unsupervised manner, you can check out the Sentence Transformers library. They fine-tuned BERT, RoBERTa, DistilBERT, ALBERT, XLNet models on siamese/triplet network structure to be used in several tasks: semantic textual similarity, clustering, and semantic search.
(They also provide code to train your own models U+1F60E AND multilingual models)
GitHub:
UKPLab/sentence-transformers
BERT / RoBERTa / XLM-RoBERTa produces out-of-the-box rather bad sentence embeddings. This repository fine-tunes BERT /…
github.com
txtai: AI-Powered Search Engine

Talking about sentence embeddings…Want to use sentence transformer AI search and scale to millions of records? The answer is with Approximate Nearest Neighbor (ANN) search that is found in the new txtai library (built on top of transformers, sentence transformers). The library currently supports three ANN search libraries: faiss, annoy, and hnswlib. U+1F525U+1F525
On top of doing similarity search, txtai can also be leveraged for extractive question answering on the search results. Example taken from David Mezzeti’s blog post:
sections = ["Giants hit 3 HRs to down Dodgers",
"Giants 5 Dodgers 4 final",
"Dodgers drop Game 2 against the Giants, 5-4",
"Blue Jays 2 Red Sox 1 final",
"Red Sox lost to the Blue Jays, 2-1",
"Blue Jays at Red Sox is over. Score: 2-1",
"Phillies win over the Braves, 5-0",
"Phillies 5 Braves 0 final",
"Final: Braves lose to the Phillies in the series opener, 5-0",
"Final score: Flyers 4 Lightning 1",
"Flyers 4 Lightning 1 final",
"Flyers win 4-1"]
# Add unique id to each section to assist with qa extraction
sections = [(uid, section) for uid, section in enumerate(sections)]
questions = ["What team won the game?", "What was score?"]
execute = lambda query: extractor(sections, [(question, query, question, False) for question in questions])
for query in ["Red Sox - Blue Jays", "Phillies - Braves", "Dodgers - Giants", "Flyers - Lightning"]:
print("----", query, "----")
for answer in execute(query):
print(answer)
print()
# Ad-hoc questions
question = "What hockey team won?"
print("----", question, "----")
print(extractor(sections, [(question, question, question, False)]))
GitHub:
neuml/txtai
txtai builds an AI-powered index over sections of text. txtai supports building text indices to perform similarity…
github.com
Blog:
Introducing txtai, an AI-powered search engine built on Transformers
Add Natural Language Understanding to any application
towardsdatascience.com
Fine-tuning Custom Datasets
Hugging Face has a new doc write-up on how to fine-tune your own dataset with either PyTorch or TF framework (natively) or with their Trainer class. Now you can see how fun preprocessing really is U+1F601!
The examples explored:
- Sequence Classification with IMDb Reviews
- Token Classification with W-NUT Emerging Entities
- Question Answering with SQuAD 2.0
Fine-tuning with custom datasets – transformers 3.0.2 documentation
Note The datasets used in this tutorial are available and can be more easily accessed using the U+1F917 NLP library. We do…
huggingface.co
Data API Endpoint With SQL
If you like SQL and you like data, Port 5432 is open… Splitgraph allows users to connect to more than 40K datasets via a PostgreSQL client. U+1F440
Splitgraph
SELECT cambridge_cases. date AS date , chicago_cases.cases_total AS chicago_daily_cases…
www.splitgraph.com
If you are a Python/PostgreSQL nut, here’s the pyscopg2 code to get you started:
import psycopg2
# Your Splitgraph DDN username/password
API_KEY = "API_KEY"
API_SECRET = "API_SECRET"
QUERY = """SELECT candidate_normalized, SUM(votes)::integer AS total_votes
FROM "splitgraph/2016_election:latest".precinct_results
WHERE state_postal = 'CA'
GROUP BY candidate_normalized
ORDER BY total_votes DESC
LIMIT 5
"""
with psycopg2.connect(
dsn=f"postgresql://{API_KEY}:{API_SECRET}@data.splitgraph.com:5432/ddn?application_name=psycopg2"
) as conn:
with conn.cursor() as cur:
cur.execute(QUERY)
result = cur.fetchall()
print(result)
What kind of data?
Explore the 27.2K topics U+1F440
Splitgraph
Data-Ops Reimagined: One PostgreSQL endpoint, 40k+ datasets. Build, version, query and share reproducible data images.
www.splitgraph.com
It’s LIT U+1F525
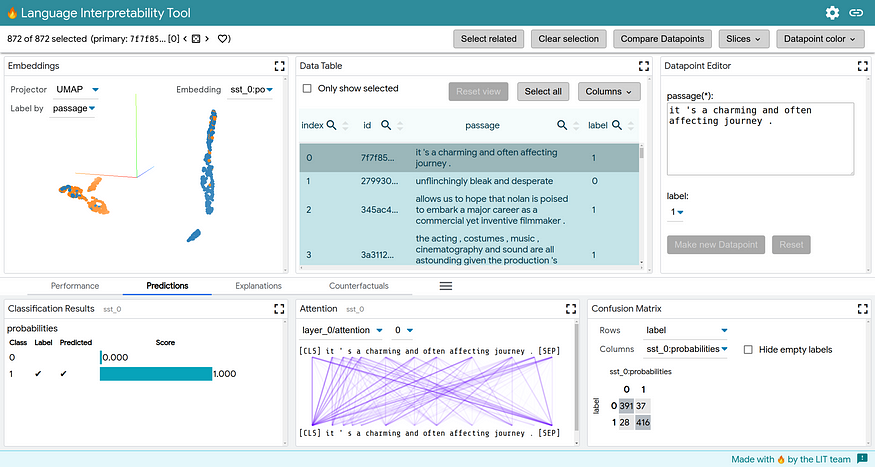
Google sneaked up on us with LIT. A toolkit that allows the developer to dig deep into language models, in addition to dataset visualization. I tend to view LIT as an ML demo on steroids for prototyping. Comes with a UI out of the box.
What can it do?
LIT supports local explanations — including salience maps, attention, and rich visualizations of model predictions — as well as aggregate analysis — including metrics, embedding spaces, and flexible slicing — and allows users to seamlessly hop between them to test local hypotheses and validate them over a dataset.
Google open-sources LIT, a toolset for evaluating natural language models
Google-affiliated researchers today released the Language Interpretability Tool (LIT), an open source…
venturebeat.com
GitHub:
PAIR-code/lit
The Language Interpretability Tool (LIT) is a visual, interactive model-understanding tool for NLP models. LIT is built…
github.com
Paper: https://arxiv.org/pdf/2008.05122.pdf
Broadcaster Stream API

As websockets for streaming data become more popular in the engineer’s stack, keeping your eye on the latest libraries is a must. Broadcaster is a simple websocket library that can run with several backends such as Redis PUB/SUB, Apache Kafka, and Postgres LISTEN/NOTIFY. If you have experience with FastAPI, this should be familiar to you.
GitHub:
encode/broadcaster
Broadcaster helps you develop realtime streaming functionality by providing a simple broadcast API onto a number of…
github.com
Fast.ai New Release
Fast.ai fans, there’s a new release with a ton of goodies. Read all about it on their blog post. (includes a handy book)
fast.ai releases new deep learning course, four libraries, and 600-page book
fast.ai is a self-funded research, software development, and teaching lab, focused on making deep learning more…
www.fast.ai
Colab of the Week:
Google Colaboratory
Edit description
colab.research.google.com
Dataset of the Week: DialogRE
What is it?
DialogRE is the first human-annotated dialogue-based relation extraction dataset, containing 1,788 dialogues originating from the complete transcripts of a famous American television situation comedy Friends.
Sample
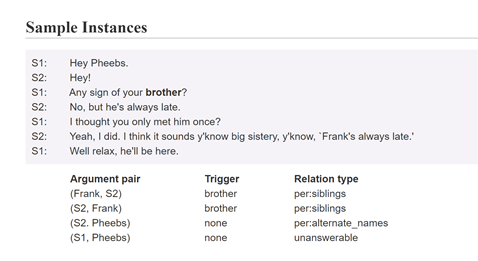
Where is it?
DialogRE: The First Human-Annotated Dialogue-Based Relation Extraction Dataset
DialogRE is the first human-annotated dialogue-based relation extraction dataset, containing 1,788 dialogues…
dataset.org
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
If you enjoyed this article, help us out and share with friends!
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

