


NLP News Cypher | 05.31.20
Last Updated on July 27, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 05.31.20
To the Stars
We did it, we’ve returned to space. SpaceX is the first private company to propel humans into orbit. After traveling for just under 19 hours, the Dragon crew docked with the ISS that currently hovers 254 miles above in low-earth orbit. Next hurdle: reentry. Godspeed.
Elon, how does it feel?
FYI, we added another great update to The Big Bad NLP Database! 79 new datasets bringing us to 481 total. Thank you to all contributors: Issa Moradnejad, Joshua Eisenberg, Kelvin Jiang, Aadarsh Singh, Johnny Dunn, Jonathan Kummerfeld & Tomasz Pędzimąż.
If you’re already bored, then check out this AI history timeline from Parisa Rashidi:

This Week:
GPT-3, the Sureshot
Dev Overflow
DeepPavlov Update
NLP Resources
Emoji Automata
From RAGs to Answers
CMUs Low Resource NLP Repo
NLP Viewer
RASA, NLU, and BERT
Dataset of the Week: Quda
GPT-3, the Sureshot
OpenAI has swag. Why? Because they have yet to publicly announce GPT-3 and it’s already on U+1F525U+1F525. However, this didn’t stop the AI community from noticing on Thursday night when the planet’s largest language model was introduced to the world.
Well, just the paper was released, the model is still parked in Greg Brockman’s garage.
At the extreme end, the model is modest in size U+1F601, it’s ONLY 175 billion parameters U+1F92A, 10X more than any previous non-sparse language model. If you are thinking of using this model, if it ever comes out, think again. Here’s a thread from GPT-3’s repo on the challenges that developers will face with the largest sized model:
Model release · Issue #1 · openai/gpt-3
Great work by the OpenAI team! The paper does not discuss it, so I'll be the first to ask: What's the release…
github.com
How does it perform?
On some tasks like COPA and ReCoRD, GPT-2 it achieves nearly SOTA performance with zero-shot (meaning it wasn’t fine-tuned for downstream tasks, it’s how it performs out of the box).
On its limitations:
“GPT-3 appears to be weak in the few-shot or one-shot setting at some tasks that involve comparing two sentences or snippets, for example, whether a word is used the same way in two sentences (WiC), whether one sentence is a paraphrase of another, or whether one sentence implies another,”
Paper:
Zero-Shot from U+1F917
Hugging Face didn't waste any time, the following day they released their zero-shot demo for you to play with:
Streamlit
Edit description
huggingface.co
Hey, remember when a 1.5B param model was “too dangerous” for release? U+1F602
Dev Overflow
Stack Overflow came out with their annual developer survey. Here are a few highlights:
Top 3 ‘Loved’ Languages: Rust, TypeScript, & Python
Most Wanted Platform: Docker
Most Loved Platform: Linux (duh)
What Do Developers Do When They Are Stuck? U+1F60211% panic U+1F602:
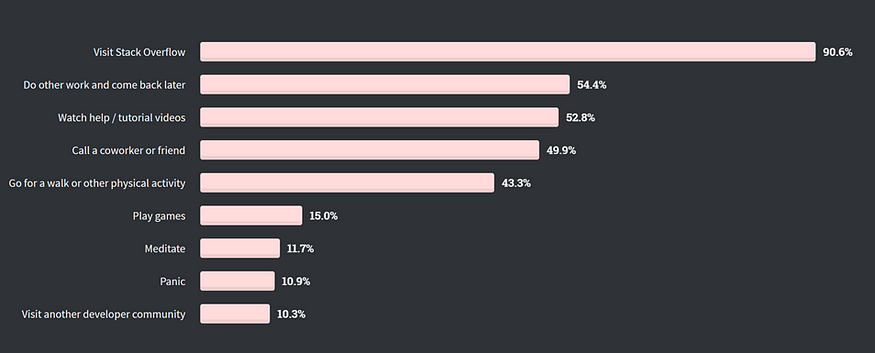
Full Survey Results:
Stack Overflow Developer Survey 2020
Each month, about 50 million people visit Stack Overflow to learn, share, and build their careers. Industry estimates…
insights.stackoverflow.com
DeepPavlov Update
Framework update from the great developers at DeepPavlov:
They have a new knowledge base QA model that can answer these question types:
Complex questions with numerical values:
- “What position did Angela Merkel hold on November 10, 1994?”
Complex question where the answer is number or date:
- “When did Jean-Paul Sartre move to Le Havre?”
Questions with counting of answer entities:
- “How many sponsors are for Juventus F.C.?”
Questions with ordering of answer entities by ascending or descending of some parameter:
- “Which country has highest individual tax rate?”
Simple questions:
- “What is crew member Yuri Gagarin’s Vostok?”
deepmipt/DeepPavlov
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
github.com
NLP Resources
Thank you to Mr. Vollet, a new educational NLP site went up with various resources for you to grapple with! Covers everything from beginner to advanced difficulty in various mediums such as articles, books, tutorials, notebooks, and even YouTube videos. You may find a few familiar resources that I’ve previously discussed U+1F9D0U+1F601.
Brainsources for #NLP enthusiasts
A Digital U+1F9E0 Board of Learnings from Articles, Books, Tutorials, Notebooks, Youtube & More.
www.notion.so
Emoji Automata
In this matplotlib blog, they show how you can create emoji-art from images using Python. Yay! (Code included)
What is emoji art? U+1F447 Her face is a bunch of emojis.

Emoji Mosaic Art
A while back, I came across this cool repository to create emoji-art from images. I wanted to use it to transform my…
matplotlib.org
From RAGs to Answers
Just when we thought T5 & BART were awesome for QA, Facebook AI released their RAG model that “achieves state-of-the-art results on open Natural Questions, WebQuestions, and CuratedTrec.”
The takeaway is that instead of purely storing knowledge in pre-trained parameters (like T5 & BART), it is best to use a hybrid model (where one combines parametric and non-parametric (Wikipedia) approaches) to yield better results.
Open domain question answering is on fire in 2020. As far as I know, code is not out yet.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve…
arxiv.org
CMUs Low Resource NLP Repo
For those interested in low-resource NLP, you should check out CMUs bootcamp held earlier this month. Their bootcamp shared slides on several topics that you don’t see everyday for low-resource languages like speech synthesis and speech recognition! Videos and more materials coming soon!
GitHub:
neubig/lowresource-nlp-bootcamp-2020
This is a page for a low-resource natural language and speech processing bootcamp held by the Carnegie Mellon…
github.com
NLP Viewer
Visualize the structure of your favorite dataset from Hugging Face’s NLP viewer. In their demo, they have displayed a healthy amount of NLP datasets and how you can visualize them by split and other filters. This is awesome!
Demo:
Streamlit
huggingface.co
RASA, NLU, and BERT
If this question interests you: “When do the benefits of using large pre-trained models outweighs the increases in training time and compute resources?” then please read this article from RASA showing how they used BERT and other model pipelines for NLU purposes.
How to Use BERT in Rasa NLU
Since the release of DIET with Rasa Open Source 1.8.0, you can use pre-trained embeddings from language models like…
blog.rasa.com
Dataset of the Week: Quda
What is it?
Dataset contains 14,035 diverse user queries annotated with 10 low-level analytic tasks that assist in the deployment of state-of-the-art machine/deep learning techniques for parsing complex human language.
Sample:

Where is it?
quda
Edit description
freenli.github.io
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
If you enjoyed this article, help us out and share with friends!
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

