


![Named Entity Recognition in Ecommerce Industry — Custom model [Github Repo] — 03/07/24](https://miro.medium.com/v2/resize:fit:700/0*hQ4DJQL7UPQp5kKZ.png "Named Entity Recognition in Ecommerce Industry — Custom model [Github Repo] — 03/07/24")
Named Entity Recognition in Ecommerce Industry — Custom model [Github Repo] — 03/07/24
Last Updated on July 4, 2024 by Editorial Team
Author(s): Vaibhawkhemka
Originally published on Towards AI.
Github Repo: https://github.com/vaibhawkhemka/ML-Umbrella/tree/main/NLP/Product-Categorization

Motivation
From e-commerce to Customer support, all businesses require some kind of NER model to process huge amounts of texts from users.
To automate this whole, one requires NER models to extract relevant and important entities from text.
Final Result/Output
Input text = “EL D68 (Green, 32 GB) 3 GB RAM [‘3 GB RAM | 32 GB ROM | Expandable Upto 128 GB’, ‘15.46 cm (6.088 inch) Display’, ‘13MP Rear Camera | 8MP Front Camera’, ‘4000 mAh Battery’, ‘Quad-Core Processor’]”
Output =
Green ->>>> COLOR
32 GB ->>>> STORAGE
3 GB RAM ->>>> RAM
3 GB RAM ->>>> RAM
32 GB ROM ->>>> STORAGE
Expandable Upto 128 GB ->>>> EXPANDABLE_STORAGE
15.46 cm (6.088 inch) ->>>> SCREEN_SIZE
13MP Rear Camera ->>>> BACK_CAMERA
8MP Front Camera ->>>> FRONT_CAMERA
4000 mAh Battery ->>>> BATTERY_CAPACITY
Quad-Core Processor ->>>> PROCESSOR_CORE
Data Preparation
A tool for creating this dataset (https://github.com/tecoholic/ner-annotator),
Snapshot for the dataset for Mobile phone product description on Amazon:

A single record of the Data:

Converting into proper Spacy span format:
The proper format that Spacy Ner model understands

import jsonlines, json
file_path = "Training Data/Mobile/Mobile_training.jsonl"
laptop_classes = ["RAM","STORAGE","BATTERY CAPACITY","PROCESSOR_TYPE","SCREEN_SIZE","REFRESH_RATE","SCREEN_TYPE","BACK_CAMERA","FRONT_CAMERA"]
with jsonlines.open(file_path) as reader:
output_json = {"classes": laptop_classes, "annotations": []}
# Iterate over each line (JSON object)
for obj in reader:
processed_obj = [obj["text"],{"entities":obj["label"]}]
output_json["annotations"].append(processed_obj)
# Save the output JSON to a new file
with open('Training Data/Mobile/Mobile_annotations.json', 'w') as f:
json.dump(output_json, f, indent=None)
Above is the code for converting into proper data format. Check out jupyter notebook: NER_model_Mobile.ipynb
Final pandas dataframe from processed data:

Splitting the dataset — 10% test
### Split the data
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.1)
train.head()
Create spacy DocBin objects from annotated data to train Spacy NER model:
import spacy
from spacy.tokens import DocBin
from tqdm import tqdm
# Define a function to create spaCy DocBin objects from the annotated data
def get_spacy_doc(data):
# Create a blank spaCy pipeline
nlp = spacy.blank('en')
db = DocBin()
# Initialize a counter for None spans
none_spans = 0
spans = 0
for index, row in data.iterrows():
# Get the text and annotations
text = row["Description"]
annotations = row["Annotations"]
# Check if the text is not empty
if not text:
continue
# Process the text and annotations
doc = nlp(text)
if doc is None:
print(f"Failed to process text: {text}")
continue
ents = []
for start, end, label in annotations:
if start < 0 or end < 0:
print(f"Invalid annotation: {start}, {end}, {label}")
continue
#print(text)
span = doc.char_span(start, end, label=label)
if span is None:
print(f"Failed to create span for annotation: {start}, {end}, {label}")
none_spans += 1
continue
else:
spans+=1
ents.append(span)
doc.ents = ents
#Add the processed document to the DocBin
db.add(doc)
print(f"Number of None spans: {none_spans}")
print(f"Number of spans: {spans}")
return db
Modelling
Architecture:
The basic architecture for all spacy models:

Reference: https://explosion.ai/blog/deep-learning-formula-nlp
[Embed]HashEmbed → Sub-word features than character based→ richer representation and arbitrary sized vocabulary → Can use Word2vec/Glove etc
[Encode] → Context-independent to context-dependent using LSTM or CNN.
[Attend] — Attention mechanism by Key, Value pair, and context vectors
[Predict] — MLP
Tok2vec model [example]:

https://github.com/explosion/spaCy/blob/master/spacy/ml/models/tok2vec.py (Built using thinc framework)
NER Model — Transition-Based:
State(all three stack, buffer, and output) and Action
Structure Prediction.


The above shows how the transition-based approach works with stack, buffer, output, and Transition/action.
Reference: https://www.microsoft.com/en-us/research/video/transition-based-natural-language-processing/
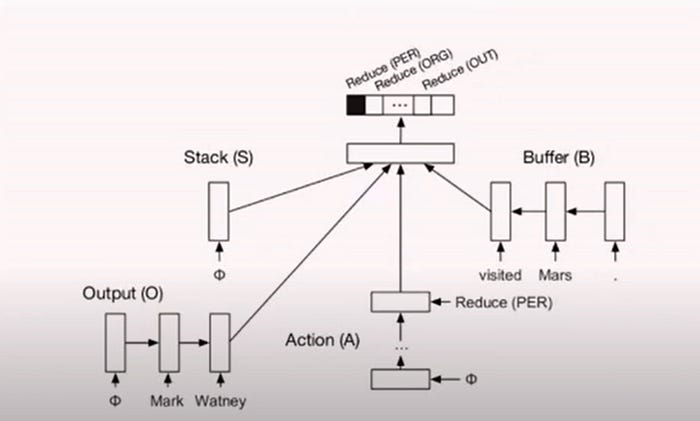
The above shows How stacked LSTM works for encoding for all states and actions.
The final Prediction from MLP is the Multiclassification task with labels as SHIFT, OUT, and REDUCE
Spacy model layer and Config Mapping:
Example of a tok2vec config:
Model in thinc framework:

Respective config for the model:
Thinc deep learning framework is used as a backend to build spacy models instead of pytorch or TensorFlow.
Difference between normal pytorch and spacy models. => Spacy(easy, reliable and productionable)
The user can define and create this model using a configuration file for any task: NER, Tok2Vec, Tagger, Dependency Parser, Sentiment etc
One can also create thinc models and wrap around pytorch and TensorFlow. I will build it next blog.
NER Config file created here:

Reference: https://spacy.io/usage/training
config_ner.cfg :
[paths]
train = null
dev = null
vectors = "en_core_web_lg"
init_tok2vec = null
[system]
gpu_allocator = null
seed = 0
[nlp]
lang = "en"
pipeline = ["tok2vec","ner"]
batch_size = 1000
disabled = []
before_creation = null
after_creation = null
after_pipeline_creation = null
tokenizer = {"@tokenizers":"spacy.Tokenizer.v1"}
vectors = {"@vectors":"spacy.Vectors.v1"}
[components]
[components.ner]
factory = "ner"
incorrect_spans_key = null
moves = null
scorer = {"@scorers":"spacy.ner_scorer.v1"}
update_with_oracle_cut_size = 100
[components.ner.model]
@architectures = "spacy.TransitionBasedParser.v2"
state_type = "ner"
extra_state_tokens = false
hidden_width = 64
maxout_pieces = 2
use_upper = true
nO = null
[components.ner.model.tok2vec]
@architectures = "spacy.Tok2VecListener.v1"
width = ${components.tok2vec.model.encode.width}
upstream = "*"
[components.tok2vec]
factory = "tok2vec"
[components.tok2vec.model]
@architectures = "spacy.Tok2Vec.v2"
[components.tok2vec.model.embed]
@architectures = "spacy.MultiHashEmbed.v2"
width = ${components.tok2vec.model.encode.width}
attrs = ["NORM","PREFIX","SUFFIX","SHAPE"]
rows = [5000,1000,2500,2500]
include_static_vectors = true
[components.tok2vec.model.encode]
@architectures = "spacy.MaxoutWindowEncoder.v2"
width = 256
depth = 8
window_size = 1
maxout_pieces = 3
[corpora]
[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[training]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
seed = ${system.seed}
gpu_allocator = ${system.gpu_allocator}
dropout = 0.1
accumulate_gradient = 1
patience = 1600
max_epochs = 0
max_steps = 20000
eval_frequency = 200
frozen_components = []
annotating_components = []
before_to_disk = null
before_update = null
[training.batcher]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = false
tolerance = 0.2
get_length = null
[training.batcher.size]
@schedules = "compounding.v1"
start = 100
stop = 1000
compound = 1.001
t = 0.0
[training.logger]
@loggers = "spacy.ConsoleLogger.v1"
progress_bar = false
[training.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 0.00000001
learn_rate = 0.001
[training.score_weights]
ents_f = 1.0
ents_p = 0.0
ents_r = 0.0
ents_per_type = null
[pretraining]
[initialize]
vectors = ${paths.vectors}
init_tok2vec = ${paths.init_tok2vec}
vocab_data = null
lookups = null
before_init = null
after_init = null
[initialize.components]
[initialize.tokenizer]
Output and Evaluation:

Evaluation is done based on ENTS_P(Precision), ENTS_R(Recall) and ENTS_F (F-Score).
After the 15th epoch Final ENTS_F is 57.64, which can be improved by providing more data for this case.
Intuition for Evaluation:
We evaluate the NER model based on Span-Identification and Span-Prediction.
Span-Identification:

https://cees-roele.medium.com/custom-evaluation-of-spans-in-spacy-f1f2e7a99ad8
As discussed, NER is a multiclass Classification problem with SHIFT, OUT, and REDUCE as output. But we evaluate our models only based on REDUCE.
The above picture shows how Precision, Recall, and F-Score are calculated.
The code used for evaluating PRF (Precision-Recall-Fscore) by spacy:
def get_ner_prf(examples: Iterable[Example], **kwargs) -> Dict[str, Any]:
"""Compute micro-PRF and per-entity PRF scores for a sequence of examples."""
score_per_type = defaultdict(PRFScore)
for eg in examples:
if not eg.y.has_annotation("ENT_IOB"):
continue
golds = {(e.label_, e.start, e.end) for e in eg.y.ents}
align_x2y = eg.alignment.x2y
for pred_ent in eg.x.ents:
if pred_ent.label_ not in score_per_type:
score_per_type[pred_ent.label_] = PRFScore()
indices = align_x2y[pred_ent.start : pred_ent.end]
if len(indices):
g_span = eg.y[indices[0] : indices[-1] + 1]
# Check we aren't missing annotation on this span. If so,
# our prediction is neither right nor wrong, we just
# ignore it.
if all(token.ent_iob != 0 for token in g_span):
key = (pred_ent.label_, indices[0], indices[-1] + 1)
if key in golds:
score_per_type[pred_ent.label_].tp += 1
golds.remove(key)
else:
score_per_type[pred_ent.label_].fp += 1
for label, start, end in golds:
score_per_type[label].fn += 1
totals = PRFScore()
for prf in score_per_type.values():
totals += prf
if len(totals) > 0:
return {
"ents_p": totals.precision,
"ents_r": totals.recall,
"ents_f": totals.fscore,
"ents_per_type": {k: v.to_dict() for k, v in score_per_type.items()},
}
else:
return {
"ents_p": None,
"ents_r": None,
"ents_f": None,
"ents_per_type": None,
}
Reference: https://github.com/explosion/spaCy/blob/master/spacy/scorer.py#L760
Span Prediction :
There are 9 different entires like ["RAM", "STORAGE", "BATTERY CAPACITY", "PROCESSOR_TYPE", "SCREEN_SIZE", "REFRESH_RATE", "SCREEN_TYPE", "BACK_CAMERA", "FRONT_CAMERA"] to predict for REDUCE class.
It uses categorical crossentropy loss function to optimize NER models (More details in later blogs)
Testing and Final Results:
Input text = “EL D68 (Green, 32 GB) 3 GB RAM [‘3 GB RAM | 32 GB ROM | Expandable Upto 128 GB’, ‘15.46 cm (6.088 inch) Display’, ‘13MP Rear Camera | 8MP Front Camera’, ‘4000 mAh Battery’, ‘Quad-Core Processor’]”
Output =
Green ->>>> COLOR
32 GB ->>>> STORAGE
3 GB RAM ->>>> RAM
3 GB RAM ->>>> RAM
32 GB ROM ->>>> STORAGE
Expandable Upto 128 GB ->>>> EXPANDABLE_STORAGE
15.46 cm (6.088 inch) ->>>> SCREEN_SIZE
13MP Rear Camera ->>>> BACK_CAMERA
8MP Front Camera ->>>> FRONT_CAMERA
4000 mAh Battery ->>>> BATTERY_CAPACITY
Quad-Core Processor ->>>> PROCESSOR_CORE
Github Link: https://github.com/vaibhawkhemka/ML-Umbrella/tree/main/NLP/Product-Categorization
Thanks for reading the blog.
If you have any questions, hit me up on my LinkedIn: https://www.linkedin.com/in/vaibhaw-khemka-a92156176/
References for modeling:
https://explosion.ai/blog/deep-learning-formula-nlp => Embed, Encode, Attend and Predict => Position is imp in sequence in text.
https://support.prodi.gy/t/spacy-ner-models-architecture-details/4336
https://github.com/explosion/spaCy/blob/master/spacy/ml/models/tok2vec.py
https://spacy.io/usage/layers-architectures
https://spacy.io/api/architectures#CharacterEmbed
Understanding span:
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

