



Modern NLP: A Detailed Overview. Part 4: The Latest Developments
Last Updated on August 2, 2023 by Editorial Team
Author(s): Abhijit Roy
Originally published on Towards AI.
In the current world, anyone with a connection to the web has heard of a tool called ChatGPT, which created havoc all around, and some have even tried to use it for different tasks in their daily life. Many know it as the revolution that can answer any question or doubt. But, have you wondered how did we reach here? How has AI become capable of answering most of the questions and queries you have?
Let’s try to shed some light on it. Before we start, the concepts we will discuss throughout the article need concepts from previous works like Transformers and GPT 2. If you are not known of these works, I have already talked about these topics; please go through them briefly.
So, let’s dive in.
In this article, we will be talking about GPT 3, 3.5, and chatGPT. Before we start talking about GPT3, let me familiarize you with another work from OpenAI, which was important for the evolution of GPT3.
Generating Long Sequences with Sparse Transformers
In 2019, transformers started to get immensely popular and started to be used for numerous works. One issue emerged as the input context length grew in length. As transformers, use attention on the entire length of the input, the required time and memory requirements increase quadratically with the increase of the length of the input. The time complexity becomes O(N²) as for each token or word, the model attends to all the other words, so O(N) for each word, for all the words, it becomes N x O(N) = O(N²). This causes the learning to soon be intractable. OpenAI released this paper in 2019, to deal with this exploding time issue.
The idea was to introduce a modeling change that will reduce the time complexity to N^(1+ 1/p) where p is the factorization element with a value >1, usually p=2, without compromising performance. So, finally, it becomes O(N*sqrt(N)).
Observations: It was seen that, though the attention mechanism attends to all the pixels or words for a particular token, it is not always required as seen in the figure below.

It was found that as layers were already learning the row and column-based sparse attention and data-dependent patterns were getting established. So, the authors concluded, sparse weighted kernels can be introduced for building an attention matrix without affecting the performance of the model too much.
Idea: The authors broke down the full self-attention into 2 steps, with 2 different kernels based on observations of how attention is distributed. The authors found for attention to images, generally, attention is given to a certain pattern, but for non-image data like audio and text, there is no such fixed pattern for the kernel. The decided kernels are as shown in the image below.
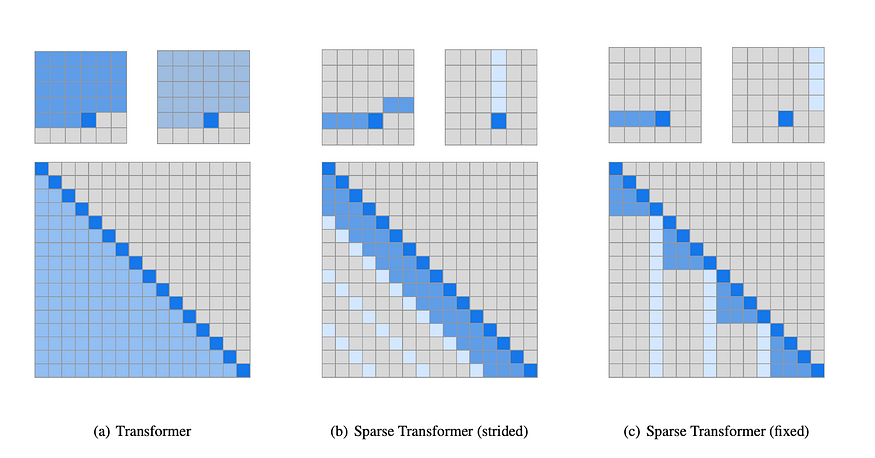
The first image (a) shows the actual transformer self-attention, where, to produce one output token, the model attends to all the steps or tokens occurring before the output position. The authors factorized the actual self-attention into two different attention-based kernels, as in (b) and (c ).
(B) Strided Kernel: In this case, the model attends to the row and column of the output position. This kind was useful for image-based cases.
(C ) Fixed Kernel: In this case, the model attends to a fixed column, and the elements after the latest column element. This kind was useful for text and audio.
These factorized attention layers provided near-equal results but successfully reduced the operation time and memory consumption.
The architecture of the sparse transformer:
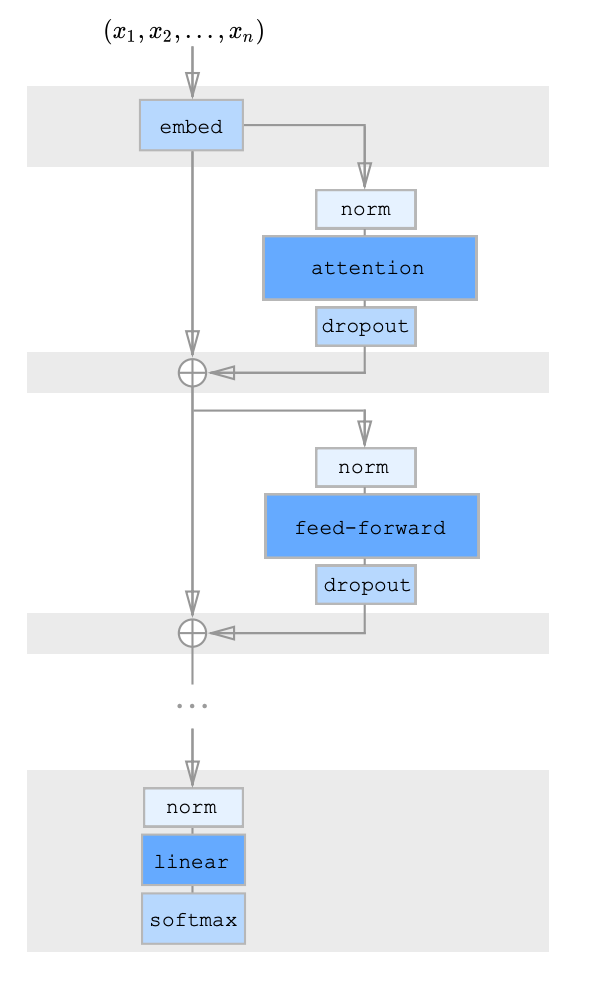
The authors introduced a residual architecture to combine factorized attention, against the original architecture of the transformer model. They proposed 3 approaches:
(1) Each residual block will have 1 kind of factorized attention kernel, and we will arrange them in an interleaved manner
(2) There will be 1 attention head, which will jointly attend the positions given by both the kernels and will function as a merged head.
(3) There will be multiple attention heads as in the original architecture, multiple attention mechanisms will be done parallelly, and the results will be concatenated to get the final result.
This architectural idea is also used in GPT 3.
Paper link: https://arxiv.org/pdf/1904.10509.pdf
Important Conclusion: By using factorized attention and interleaved residual structure, we can drastically reduce computation and time while maintaining efficiency.
Language Models are Few-Shot Learners
The mentioned work was published by OpenAI in 2020. The model proposed stands as one of the largest models in the NLP world. The work done opened a lot of doors in the future for NLP, whose innovations we enjoy today. The authors realized 3 problems with the standing approach of the models.
(1) There is a huge need for data to train the models, which are task-specific. But, it is sometimes not possible to find these supreme amounts of data.
(2) The models are pre-trained on a large distribution of data as a generalized model, but after specific task fine-tuning, they are projected on a very a narrow-distribution, which makes the model skewed, and if the data is less, there is a chance of overfitting and bad performance.
(3) As humans, we don’t require too much data, to learn something, generally, we need a few demonstrations or even a prompt at times to learn, which is very different for machines. If we need models to behave similarly to humans, the data problem had to be solved.
To solve these issues, the authors understood that a very generalized model needs to be trained. The only way was a concept called Meta-Learning.
Meta-Learning
Meta-Learning is a developing field in machine learning, which teaches the models how to learn, so it is also called Learning to learn. It is understood that humans learn new things very quickly as we possess prior knowledge about most things from our regular experiences, which helps us to have an idea about how to learn, but when a model starts learning, it has no idea about the data or the target, which plays as the difference. This is often termed Conditioning, which is a property of any living being to learn from past experiences and stimuli. It is said that there are 3 main types of prior knowledge,
- Prior Knowledge of similarity
- Prior Knowledge of data
- Prior Knowledge of learning
Meta-learning plans to teach the model in such a way that it is possible to achieve what humans can do. It is often also used to perfect algorithms. There are certain possibilities seen with meta-learning:
(A) Few-shot learning: Also called N-Way-K-Shot learning, where there are N classes and K samples from each class. The model is trained on the samples, from these data, which is called a support set, but the learning is validated on a separate set called the query set. Just note in this case, back-propagation happens on a very short support set.
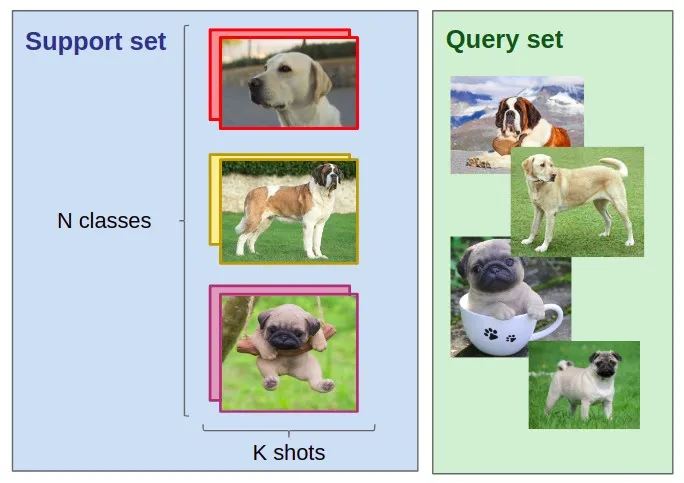
(B) One-Shot Learning: Only one sample from each N class are present in the support set, the model has to perform on the query set. Back-propagation is there.
(C ) Zero-Shot Learning: No samples are present, the model directly performs on the query set.
So, basically, a pre-trained data model can directly perform with less or no data for specific tasks. The pre-training phase is called the Meta-Learning phase and the specific learning phase is called the adaptation phase in the universe of meta-learning. To train a meta-learner, generally a plethora of different datasets and models are taken to make a generalized setting rather than a task-specific setting.
There is a whole learning and algorithm stream of Meta-learning, which I am not going to go into, or else, it will be too long. I have just touched on the parts necessary to understand GPT3.
To implement meta-learning in language models, authors used a method called in-context learning, which we will see in a minute. The idea was taken from the GPT-2 work, which proved that, if pre-trained on a huge corpus of different data, the model learns the skill of capturing several dependencies, and pattern recognitions which helps it to very quickly adapt to the new specific tasks with a very few demonstrations.
Paper links: https://arxiv.org/pdf/2004.05439.pdf
https://aclanthology.org/2022.acl-long.53.pdf
Now, what is in-context learning?
In-Context Learning
In-context learning means learning from an analogy. It is very similar to how we as humans learn. Usually, there are 3 cases with human learning:
- We are given a prompt, like, “Write a paragraph about a tree.”
- We are given a prompt with a demonstration
“Find the sum:
1+2=3
4+5= <prediction>” - We are given a prompt with multiple demonstrations.
“Find the sum:
1+2=3
4+5= 9
6+7= <prediction>”
In-context learning works in the same way. We input a prompt or a prompt with a demonstration in the context vector of the model, and the model outputs a prediction result. Now, in this case, there is no backpropagation or learning. The whole input with the prompt and the demonstration is input as a string, in the input vector of the model. It can be said its kind of prediction based on conditioning.
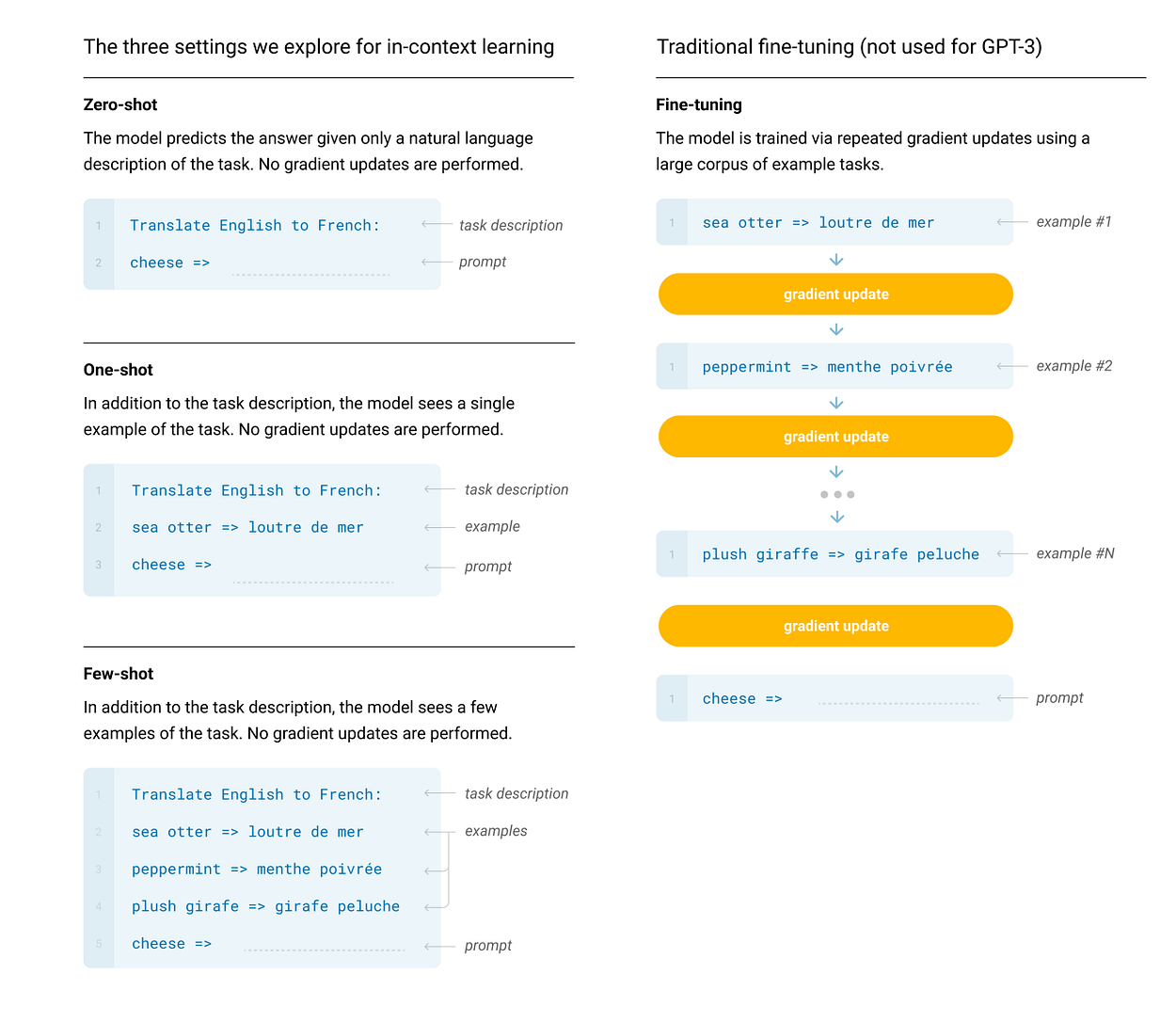
Now, the authors have defined 4 cases to evaluate the model’s performance:
- Fine-tuning as done in the previous cases, after pre-training, the model is trained on task-specific data.
- Few-Shot learning: In this case, on a pre-trained model, a prompt with multiple demonstrations was fed. The number of demonstrations ranges from 10 to 100 depending on how many can be fit in the context length of the input vector. The model predicts based on the demos. No back-propagation is there.
- One-Shot Learning: In this case, the prompt with only one demonstration is fed to the model. No back-propagation happens
- Zero-Shot Learning: In this case, only a prompt is provided with no demonstration.
The intuition of training the GPT model was taken from a very common algorithm called Model-agnostic Meta-learning.
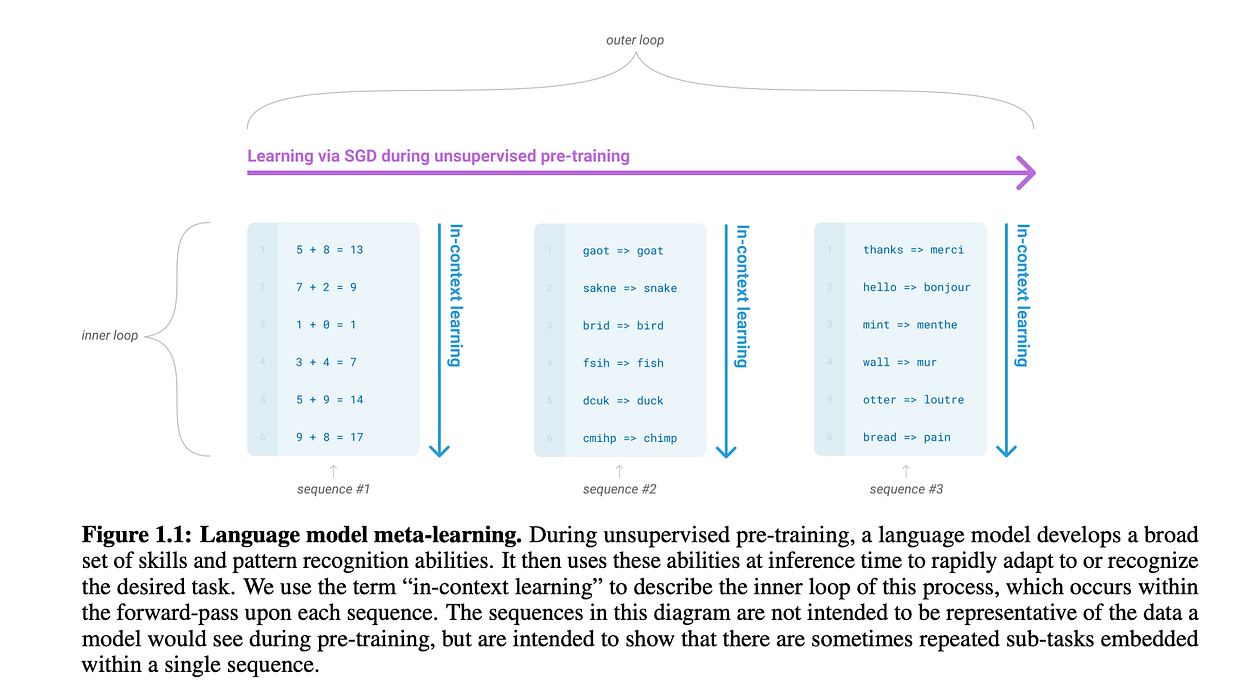
In MAML, we generally have task-specific models and a general meta-learner, and we try to decrease the loss between the task-specific prediction and the meta-learner’s predictions. The learning of the task-specific model is referred to as the inner loop, and the meta-learner’s weight update, which learns from multiple task-specific models, is called the outer loop.
In this case, the authors have called the inner loop, as In-Context learning. It's been projected like this because, in pretraining, the model is trained using a lot of different datasets, from different domains (referred to as sub-tasks). For the domains, the learning is in the inner loop, but the model learns generalization in the outer loop.
Architecture: The authors have used the same model as used in GPT-2, with a modification of using alternate dense and sparse attentions as discussed for sparse transformers. There were 8 models proposed with parameters ranging from 125 million parameters to 175 Billion parameters to judge the impact of size on performance. The model with a 175 Billion parameter is called GPT3.
Training Data:
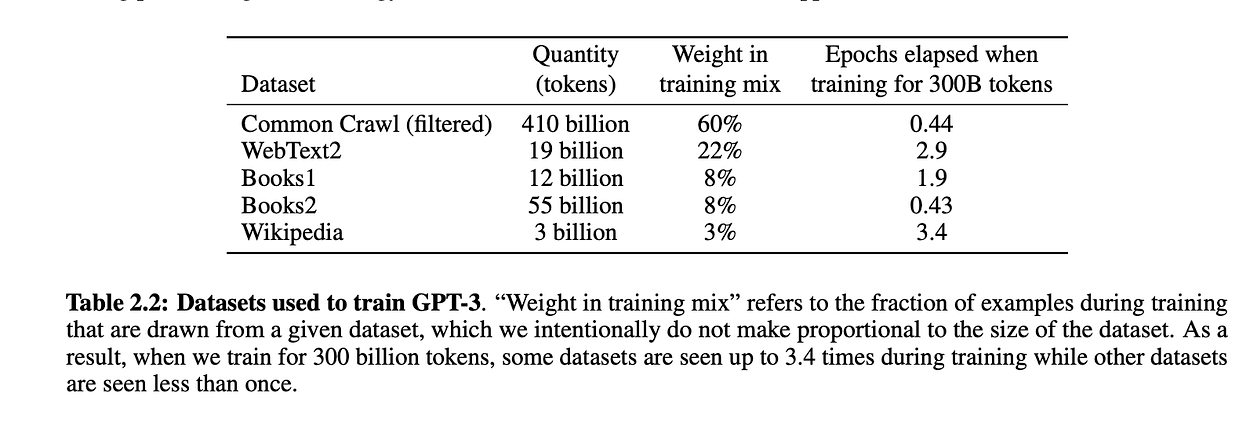
The above image describes the datasets used to train the models. The authors have filtered the dataset to remove the lower quality data, duplicity, and redundancy.
Why does In-Context learning work? I am very sure this is the question in everyone’s mind. How can a model produce output just with a demonstration?
There have been too many studies, but yet the reasons are still being looked into by several researchers all around. I will talk about the findings of the two most impactful research findings from Standford and Meta AI.
Paper links:
- Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?: https://aclanthology.org/2022.emnlp-main.759.pdf
- An Explanation of In-context Learning as Implicit Bayesian Inference: https://arxiv.org/pdf/2111.02080.pdf
The second paper proposes how it works, and the first one does a comprehensive study of the factors on which the performance of the model depends. Both of them use multiple models of massive parameter sizes. It is proven that as the size of the model increase, the learning capacity and the performance of the model also increase.
“An Explanation of In-context Learning as Implicit Bayesian Inference” makes a hypothesis that as large language models pre-train on a large set of different data from sources like Common Crawler, the model comes across numerous numbers of topics and mentions, which are fed as long data sequences to predict the next word, the model learns to use attention and understand the internal inferences of the sequences, which causes the model to remember these topics in its parameter-embedding spaces. During a task-specific inference, the model gets the data, studies with attention, and “locates” the concept in its embedding space, to find the answer. The demonstrations and prompts help the attention mechanism to perform better, providing better results.
In “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”, the authors studied 6 models, including GPT3, on 12 different datasets. They observed the following:
- Changing the labels in the demonstration, like providing random labels, also hardly affected the performance of the model.
- The researchers experimented with a variable number (k) of input-label demonstrations. They found the performance of the model improved a lot where demonstrations are there over 0 demonstrations, even if k is small (k=4), but the performance boost stops becomes very slow as we go above k≥8.
- The template of the input format improved performance.
From the experiments, 4 things were concluded that tell us how and why in-context learning works:
- The input-label mapping
- The input distribution
- The label set distribution
- The format of the input
GPT3 trained with the in-context-based meta-learning managed to perform closer to human behavior based on prompts and demonstrations under few-shot learning and match the SOTA performances for tasks like translation, question-answering, and completion but somehow failed to provide consistent gains in common sense reasoning.
Paper link: https://arxiv.org/pdf/2005.14165.pdf
Next, we are going to talk about the upgrade of GPT 3, which finally gave rise to ChatGPT.
Training language models to follow instructions with human feedback: InstructGPT
After releasing GPT3, researchers at OpenAI realized that though large language models can perform great, it does not necessarily mean they are operating according to user intent, on the contrary, the results generated by GPT3 can be untrue, toxic and not aligned enough to help people. To remedy the situation, the authors cut down GPT3 with 175B parameters, 100x to create a model with 1.3B parameters named GPT3.5 or InstructGPT. The model was fine-tuned with the help of human feedback to better align with human intent. The authors wanted the model to provide honest, helpful, and harmless answers.
In order to make the model more human interaction friendly, the authors introduced a method from a previous work, which uses Reinforcement Learning with human feedback. The Proximal policy optimization or PPO reinforcement learning technique was used.
In order to train the InstructGPT model, the authors have used 4 steps, the first step is plain old language modeling for pre-training followed by 3 steps. The authors started with a pre-trained GPT3 model after this step.
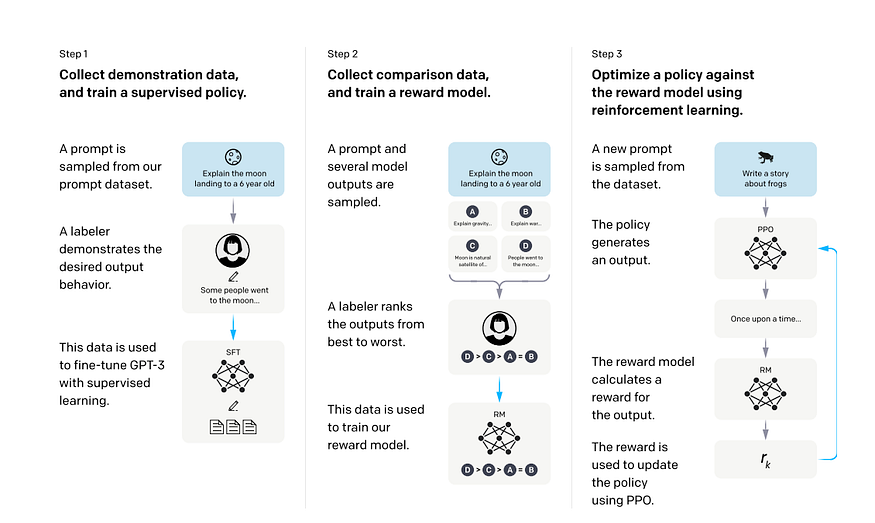
- The first step contained a short supervised fine-tuning step. The authors posted a pre-GPT3.5 portal, where users posted their prompts and demonstrations. Also, OpenAI hired 40 contractors after screening and made them write up some prompts and demonstrations. They made sure the tasks had enough diversity, including generation, question answering, dialog, summarization, extractions, and other natural language tasks, to avoid skewness in the fine-tuning step. They also eliminated the task prompts which were unclear in their motive. The pre-trained GPT3 model was fine-tuned on this data with a drop-out of 0.2 for 16 epochs.
- In step 2, we train a reward model for reinforcement learning, which will interact with the main model in the final PPO training phase. Now, in the case of a generative model, it might generate multiple outputs by feeding the same inputs. In this step, the fine-tuned model from the first step was fed the inputs, it gave multiple outputs and the contractors or labelers marked the preferred output. Thus, a dataset is created. The fine-tuned GPT3 model’s final layer was removed and it was built to take in a prompt and an answer and it had to produce a scalar reward value. The dataset made by the labelers was used to train the reward model. To train the reward model, the size of the GPT3 model was reduced from 175B parameters to 6B parameters, as it was seen training such a big model was supremely time-consuming and also unstable at times. The scalar reward is formulated as the difference of log odds with the probability of the answer produced by the model to the preferred answer by the labeler. So, that is the human feedback mechanism is introduced.
- In the last and final step, the authors take the fine-tuned model from step 1 and reduce its dimension to 1.3B parameters, which is then fine-tuned again using a PPO reinforcement algorithm in a bandit environment. This basically means the model is given an arbitrary prompt from the user, and an answer is produced by the model. The reward model takes in the answer and provides a scalar reward. The trainee model tries to find an optimal policy to maximize the reward against the reward model.
Findings: These were observed when InstructGPT was evaluated based on the target of human-requirement-aligned behavior and performance:
- Labelers significantly prefer InstructGPT outputs over outputs from GPT-3.
- InstructGPT models show improvements in truthfulness over GPT-3
- InstructGPT shows small improvements in toxicity over GPT-3, but no bias
- The InstructGPT does not reflect on the language models on which it is trained when predicting public datasets.
- The model performs the generalization of the principles well when tested on data outside the fine-tuning domain.
- InstructGPT still makes simple mistakes. For example, InstructGPT can still fail to follow instructions, makeup facts, give long hedging answers to simple questions or fail to detect instructions with false premises.
Paper link: https://arxiv.org/pdf/2203.02155.pdf
ChatGPT
After the instant success of the InstructGPT model, OpenAI decided to fine-tune the InstructGPT model on more general conversational texts, to induce chatbot-based features in the model. This gave birth to chatGPT, which is more human-like and possesses better conversational skills. So, chatGPT is built for a specific task and is a much smaller version of the original GPT3 model.
Conclusion
ChatGPT made a major impact on the world of technology as a tool that can revolutionize things. After the success, now OpenAI, with the backing of Microsoft, has released GPT-4 also, which extends the power of GPT to images also. The specs of the model have not been released due to security reasons. Google on the other hand also launched its venture in the world of chatbots with BARD, which is powered by the underlying LAMDA or Language Models for Dialog Applications models. The target of LAMDA is also very similar to chatGPT, building a chatbot that can be human-requirement aligned and can produce truthful, and nontoxic responses.
Paper links:
GPT4: https://arxiv.org/pdf/2303.08774.pdf
LAMDA: https://arxiv.org/pdf/2201.08239.pdf
Other than this also, there have been several improvements like XLNet and Ernie. Tech Giants are looking for constant improvements in the field with the hopes of a technically stronger tomorrow.
Hope this helps. Happy Reading!!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


