



Deep Learning Demystified: Unraveling the Secrets of CNN Architecture with CIFAR-10 Dataset
Last Updated on August 1, 2023 by Editorial Team
Author(s): Anshumaan Tiwari
Originally published on Towards AI.
In the ever-evolving world of artificial intelligence, Convolutional Neural Networks (CNNs) have emerged as a revolutionary technology, reshaping the fields of computer vision and image recognition. With their ability to automatically learn and identify patterns in images, CNNs have unlocked new possibilities in numerous applications, from self-driving cars to medical diagnostics. In this article, we will delve into the workings of CNN architecture and explore its prowess using the popular CIFAR-10 dataset as our testing ground.
Here I have a goal of applying the idea theory+practical, so after completing the theory part then, a code in TensorFlow will be shown so you all can practically apply the theory.
What is Convolution, actually?
Step 1: Understanding the Image and the Filter:
Let’s begin with a grayscale image, which can be represented as a 2D grid of pixels, where each pixel’s intensity corresponds to its grayscale value. For simplicity, let’s take a small 3×3 grayscale image:
Image:
[ 1 2 3 ]
[ 4 5 6 ]
[ 7 8 9 ]
Now, we’ll use a 2×2 filter:
Filter:
[ 1 0 ]
[ 0 1 ]
Step 2: Applying Convolution: We’ll perform the convolution operation by placing the 2×2 filter over the top-left corner of the image.
The convolution operation is as follows:
(1*1) + (2*0) +
(4*0) + (5*1) = 1 + 0 + 0 + 5 = 6
So, the value of the top-left pixel in the output feature map is 6.
Step 3: Sliding the Filter: Next, we slide the 2×2 filter over the entire image, performing the convolution operation for each position of the filter.
Output Feature Map:
[ 6 8 ]
[ 3 5 ]
Modes of Convolution?
In the context of image processing and signal processing, convolution can be performed in different modes, which determine how the convolution operation is handled at the boundaries of the input data. The most common modes of convolution are:
1. Same Mode
In the “Same” mode, the output of the convolution has the same spatial dimensions as the input. To achieve this, the input data is usually padded with zeros at the borders before applying the convolution operation
2. Valid Mode
In the “Valid” mode, the convolution is performed only at locations where the filter fully overlaps with the input data. This means that the filter is not centered at the border pixels of the input, and as a result, the output feature map will have reduced spatial dimensions compared to the input.
3. Full Mode
In the “Full” mode, the filter is allowed to extend beyond the borders of the input, and the convolution operation is performed at every possible location where the filter and input data overlap. As a result, the output feature map will have larger spatial dimensions than the input.
What is the Essence of the filter in Convolution?
We have understood that Convolution is nothing but a simple Matrix Operation between input data and Filter. But what is the essence of filter in CNN:-
The essence of filters in Convolutional Neural Networks (CNNs) lies in their ability to detect and learn meaningful features from input data, particularly in the context of image processing and computer vision tasks. Filters, also known as kernels.
Filters act as pattern detectors, helping the network identify specific patterns, textures, and structures in the input data. By learning appropriate filters during the training process, CNNs can extract relevant and distinctive features from the raw input, which are crucial for solving complex tasks like image recognition, object detection, and segmentation.
So you can assume Filter as the weights which are adjusted during the training process of the Model.
From 2D to 3D: Cracking the Code of Dimensionality in Convolutional Layers
The problem with Convolutional Neural Network is that Convolution between the Image and Kernal(Filter) is that the output is 2D, due to which incompatibility issue arises as this data need to be passed to other layers which accept 3d Input.
So how is this problem solved?
To solve this problem, Convolution between multiple filters occurs, and the result is stacked up by which this new 3d input can be fed to the next layer.
Unveiling the Intricacies of Convolutional Neural Networks: Structure and Operation
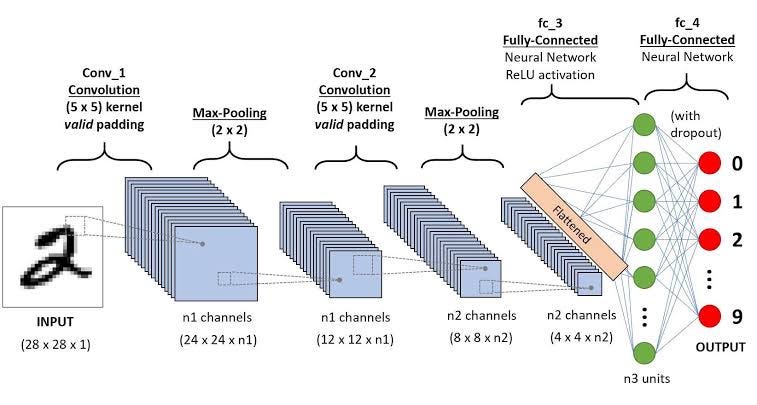
Architecture:
CNNs are composed of distinct layers, each tailored for specific tasks in the visual recognition process. The essential layers of a CNN are as follows:
a) Input Layer:
The foremost layer of the CNN is the input layer, which is responsible for accepting the raw input image. It transforms the image into a matrix of pixel values, where each pixel holds color information (e.g., red, green, blue).
b) Convolutional Layer:
In the subsequent convolutional layer, small filters, known as kernels, are convolved over the input image. These filters identify local patterns, such as edges or textures, producing feature maps. The depth of the feature maps corresponds to the number of applied filters.
c) Activation Layer:
Upon completing the convolution step, the activation function (e.g., ReLU) introduces non-linearity, enhancing CNN’s capability to learn intricate relationships between features and extract abstract representations effectively.
d) Pooling Layer:
Pooling layers contribute to spatial dimension reduction in the feature maps. Techniques like max-pooling and average-pooling select maximum and average values, respectively, from neighboring pixels. This downsampling reduces computational complexity while preserving vital features.
e) Fully Connected Layer:
The final stage of CNN’s feature extraction process involves the fully connected layers. These layers interpret the learned features, functioning akin to traditional neural network layers. They play a pivotal role in making classification decisions based on the extracted features.
Working of Convolutional Neural Networks:
The functioning of a CNN can be comprehended through the following steps:
Step 1: Input Image Reception:
The CNN commences by receiving an input image, represented as a matrix of pixel values, with each pixel encoding color channels (e.g., red, green, blue).
Step 2: Feature Extraction:
Moving to the convolutional layer, filters sweep over the input image, creating feature maps that highlight significant patterns and features within the image.
Step 3: Introducing Non-linearity:
The activation layer introduces non-linearity to the feature maps, enabling the CNN to learn complex relationships between features.
Step 4: Reducing Spatial Dimensions:
Pooling layers diminish the spatial dimensions of the feature maps, minimizing computational load while preserving critical information.
Step 5: Classification:
In the final stage, the fully connected layers process the learned features and make predictions accordingly. The CNN’s output represents its classification decision.
PROBLEM WITH FULLY CONNECTED LAYER
The fully connected layer receives 1D input, but the output, as we discussed, is 3d as we discussed earlier by stacking up the feature maps so to convert it to 1D, we will use the TensorFlow flatten() function.
Code:-
Google Colaboratory
colab.research.google.com
As the article is already too long I have included the code in the above link
DATASET USED CIFAR-10
CIFAR-10 – Object Recognition in Images
Identify the subject of 60,000 labeled images
www.kaggle.com
Also, we have done Batch Normalization and data Augmentation to improve our results. I will complete this in short lines as simply as possible
Batch Normalization
In a simple explanation, it is the conversion of values into a particular range 0 to 1 for example, if there are 2 values A=2 B=2000 then the Ml model will not accept it both values should be near this is the main concept behind Normalization and batch Normalization is just applying Normalization to batches after Convolution.
Data Augmentation
Data Augmentation is the process of artificially expanding the size of a training dataset by applying various transformations to the existing data. These transformations include rotation, scaling, flipping, cropping, and other image manipulations. By augmenting the data, the model becomes more robust and better generalizes to unseen examples, leading to improved performance and reduced overfitting.
Conclusion
Convolutional Neural Networks have transformed computer vision and image recognition, unlocking immense potential for real-world applications. A clear understanding of their architecture and functioning is essential for harnessing their capabilities in creating precise and efficient visual recognition systems. Embracing the power of CNNs allows us to embark on a groundbreaking journey of unraveling the mysteries hidden within visual data.

THANK YOU FOR GIVING ME YOUR PRECIOUS TIME TO READ MY ARTICLE
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


