



Modern NLP: A Detailed Overview. Part 2: GPTs
Last Updated on July 25, 2023 by Editorial Team
Author(s): Abhijit Roy
Originally published on Towards AI.
In the first part of the series, we talked about how Transformer ended the sequence-to-sequence modeling era of Natural Language Processing and understanding. In this article, we aim to focus on the development of one of the most powerful generative NLP tools, OpenAI’s GPT. And we will also look at certain developments along the path.
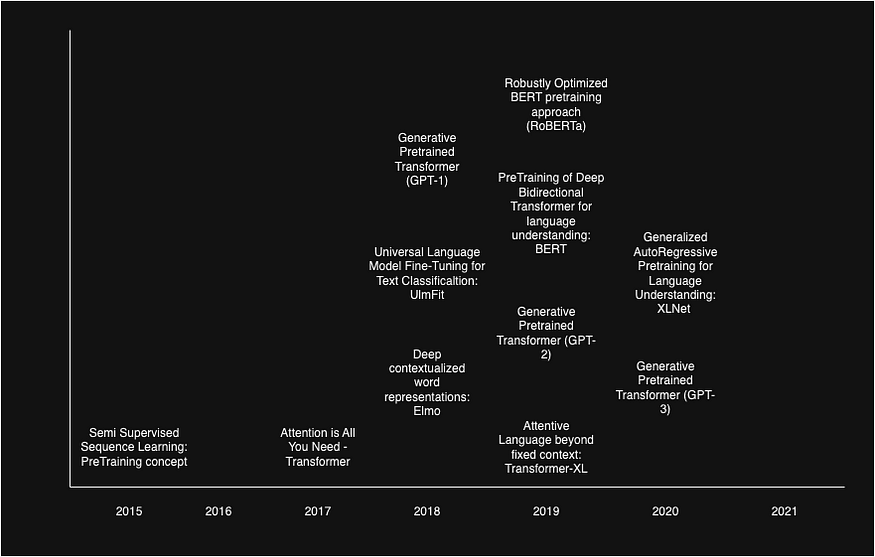
Evolution of NLP domain after Transformers
Before we start, let's take a look at the timeline of the works which brought great advancement in the NLP domain. This will help better understand how the advancement of the previous works impacted the upcoming developments and to better address the interdependencies among them.
Generative Pre-trained Transformer (GPT)
In 2018, OpenAI introduced GPT, which has shown, with the implementation of pre-training, transfer learning, and proper fine-tuning, transformers can achieve state-of-the-art performance. Ever since, OpenAI has been working on increasing the power and parameters of the model, and improving the training data, which has given rise to modern-day tools like ChatGPT, InstructGPT, and AutoGPT.
But, the question is, how did all these concepts come together? Let’s see it step by step.
Semi-Supervised Sequence Learning
As we all know, supervised learning has a drawback, as it requires a huge labeled dataset to train. In the NLP domain, it has been a challenge to procure large amounts of data, to train a model, in order for the model to get proper context and embeddings of words. In 2015, Andrew M. Dai from Google published a paper named Semi-Supervised Sequence Learning, in which the authors proposed an unsupervised approach to pre-train a model on different documents like DBPedia extracts, IMDB, Rotten-tomato reviews and unpublished manuscripts. It was observed that this pre-training allowed the model to have a greater understanding of the words, thus, better embeddings.

Finally, they fine-tuned the model to specific tasks, which was supervised task, to find that the learning was much stabilized and converged quicker. So, on the whole, a semi-supervised process worked wonders.
The authors have used a basic LSTM and trained using the clipping gradient method, which is proven to work better than the normal RNNs for predictions. Next, the authors have used 2 methods for pretraining.
- The model is passed a sequence and trained to predict the next word. This has been termed the LM-LSTM, or language-modeling model, which is the name of this task.
- The model is passed a sequence, and then it creates a single vector which is then used by the model’s decoder to reconstruct the whole sentence. This has been termed the SA-LSTM, or sequence-autoencoder model, accordingly due to the encoding creation task.
Later these pre-trained models were used after adding fine-tuning for tasks like the sentimental analysis and were found to surpass the state-of-the-art performance. Other findings are:
- The pre-training increased the stability of learning and the generalization power of the model.
- The addition of more data further increased the refinements.
- The SA-LSTM is found to be performing better, owing to the fact that they had to look for a longer context of the entire sentence, compared to the LM-LSTMs, which predicted only the next word, so they paid attention to a shorter context.
Paper link: https://arxiv.org/pdf/1511.01432.pdf
Important Conclusion: Pre-training boosts performance.
Generating Wikipedia By Summarizing Long Sequences
This work was published by Peter J Liu at Google in 2019. The authors proposed that, by using only the decoder part of the original transformer architecture, instead of using the entire thing, state-of-the-art performance can be achieved for generative tasks like summarizations. The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. Basically, it predicts a word with the context of the previous word.
The authors have used multiple Wikipedia documents as the source document for the task and used strong RNN and Transformer encoder-decoder baseline and models to validate the proposed architecture’s performance.
Having used multiple source documents, there have been duplicates and resulted in a huge set, which is impossible to train a model on, due to lack of processing power. So, the authors have used a two-stage process, following what we do as humans.
Step 1: We highlight the points from different articles to make a set of useful information. To perform this, extractive summarization methods like tf-idf, and text-rank algorithms have been used. The authors have 5 extractive methods and used the best performer
Step 2: The final step is to actually summarize the points picked in step 1 by the extractive methods using an abstractive summarization method or deep-learning method, in this case, the decoder of the transformer.
The architecture is the same as what we saw in the real transformer, with a Masked Attention block followed by a self-attention block and finally a fully connected layer, only the encoder block is dropped. The sentences and their results are concatenated in a single vector and passed into the model to train. The decoder layers create a hidden vector, which is passed into a softmax layer, for the word prediction.
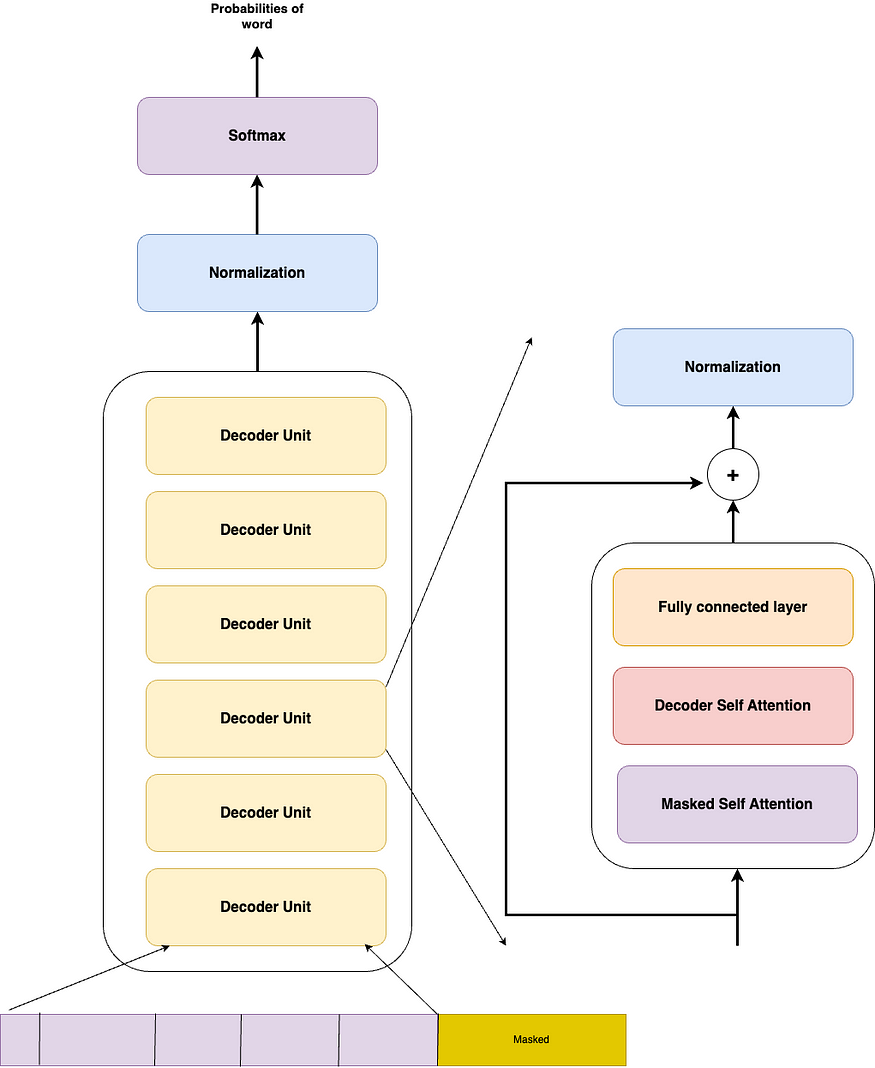
Paper link: https://arxiv.org/pdf/1801.10198.pdf
Important Conclusion: Decoder is Enough for generative tasks.
Universal Language Model Fine-tuning for Text Classification: UlmFit
This work was published in 2018 by Jeremy Howard of Fast AI, which became a prime development in this world, which is empowering all the NLP models we see today. The authors introduced the idea of transfer learning in the natural language processing, understanding, and inference world.
People who are familiar with the world of computer vision will have an idea of the concept called transfer learning, so we need to shift a bit to the computer vision world to understand the importance and urge to find something equivalent.
As supervised learning required huge datasets for image processing to train super-deep models, the scarcity of data became an issue. At this point, datasets like ImageNet and MS-COCO came with huge data, enough to train these models. Once the models were trained, it was found that the models had a good general idea of object boundary detection, color, and gradient detection. So, though these models were trained on a different source task, we can use these trained models and change the final classification layer, and fine-tune them for other tasks easily. These generalized models helped to achieve great results for tasks where data was less.
Now, coming back to the NLP world, the models were trained mostly very task-specific, so, if there was less data, there was no way out. A generalization requirement emerged. It was not like, the concept of transfer learning was never tried before, but they never succeeded, then came the savior. The authors found a solution for so-called Downstream Tasks, which are the ones that have less data availability and need a pre-trained model to be fine-tuned accordingly.
The authors mentioned the reason for the failure, as the lack of knowledge of how to fine-tune the model while acknowledging the good impact of initializing the model with pre-trained weights found using objectives like language modeling. The authors have mentioned that previous works have required too much-labeled data to fine-tune, which has affected usability severely. When the researchers have tried to train using smaller datasets, due to lack of data, it has caused overfitting on the dataset, and as a consequence, a forgetting character in the model or loss of generalization has been introduced, finally diverging.
The authors have proposed a three-step method to train and fine-tune a pre-trained model to perform best. In order to prove the claim, the authors have used a normal 3-layered LSTM model, and fine-tuning has been done using a short dataset of 100 labeled IMDB reviews to prove its sample efficiency.

Let’s look at the step:
- LM pre-training: Pre-training of the language model has been done on Wikitext-103 (Merity et al., 2017b), consisting of 28,595 preprocessed Wikipedia articles and 103 million words. The authors suggest that this is a comparable dataset to ImageNet on a size basis, and will be enough to create a good pre-trained model.
- LM fine-tuning: The authors mention that, though pre-training is a good way to find good initializing weights and generalized word sense, to deal with a domain-specific task, the model first needs to be fine-tuned on the vocabulary of the domain, as the distribution of words might be different in the general domain and the target task specific domain. Now, keep in mind, we are not fine-tuning the model with the required classifier layer at this stage, we are merely doing the same language modelling task, just the dataset that is domain-specific, just to shift the distribution of words properly. But here is the catch, we can’t simply fine-tune the model, as there is a risk of overfitting.
a. Discriminative Fine-Tuning: It has been seen different layers of the model capture different levels of data. It can be found, for fine-tuning, if we try to train all layers of the model throughout at the same learning rate, it can cause overfitting. Instead, the author proposes, to train different layers of the model at different rates. For normal backpropagation with SGD, the equation is
θt = θ(t−1) − η · ∇θJ(θ)
where θ represents the model weights, η is the learning rate, and t is the time step. The authors divide the layers of the models into levels 0 to L and define model parameters θl and ηl as the learning rate for training the l-th layer. The new equation becomes
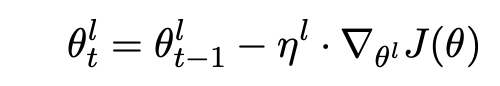
Usually, the learning rate of the (l-1) layer is the learning rate of l-th layer divided by 2.6.
b. Slanted triangular learning rates: Constant learning rates for the layer were observed to affect the learning convergence. To sort this issue, the authors proposed a slanted triangular learning rate. This proposes that a particular layer of the model should not be trained at a constant learning rate, throughout all training epochs. Instead, the rate should be increased a bit steeply, reach the highest value, then gradually be decreased.
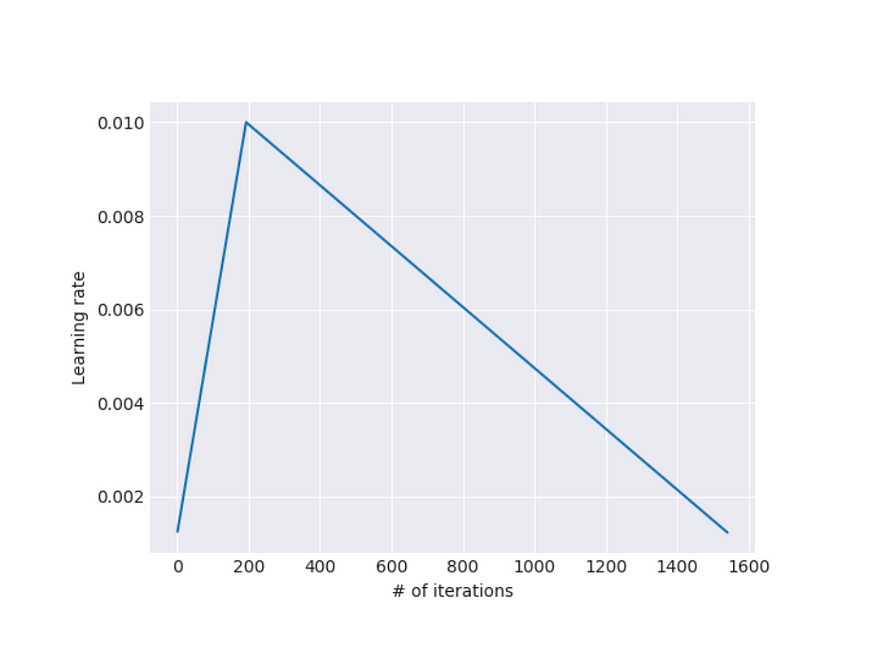
In this case, the learning rate is a function of the number of iterations.
3. Classifier Fine-tuning: This is the final step, where we take the augmented model and add a classifier to train according to our target task. The authors have taken a page from the CV playbook and added a layer of batch normalization and softmax. The authors have used two methods to achieve greater performance:
a. Concat Pooling: It has been observed that for classification tasks, we mostly use a few words that have maximum impact; for example, in a sentiment analysis, the words like best and good almost confirms it conveys a positive sentiment. Now, these words can be anywhere in the document, and hence anywhere in the hidden state representations. To focus on the impactful words, the authors have added both max-pooling and mean-pooling. The final hidden layer output is the concatenation of the hidden layer output, its max pooled and mean pooled version. The layer output representation prevents information loss, while the pooled versions focus on impactful words.
b. Gradual Unfreezing: The authors have observed that, if all the layers are unfrozen from the beginning and trained together, it introduces catastrophic forgetting behavior, as maybe the last layers are best to have a more generalized understanding. To handle this, gradual unfreezing is introduced. The last layer is unfrozen and trained first, and then after a fixed number of epochs, we unfreeze the layers before and so on, until we fine-tune all the layers.
Paper link: https://arxiv.org/pdf/1801.06146.pdf
Important Conclusion: Models can be fine-tuned for a target task if even trained on a different training task.
AND FINALLY,
Improving Language Understanding by Generative Pre-Training
GPT, or Generative Pre-trained Transformer, was published by Alec Radford from OpenAI in 2018. This work very cleverly and optimally used all the findings of the previous development and merged them with a massive parameterized model and well-curated training data, to achieve huge performance increases.
The aim of GPT is to learn a universal representation that transfers with little adaptation to a wide range of tasks. It is another transformer decoder-based, auto-regressive model, that was trained using a two-step method. The first step is an unsupervised pre-training phase, followed by task-specific fine-tuning. The authors have used the methods suggested by ULMFit to fine-tune the models to achieve better performances.
- Pre-training:
The authors have broken down the pre-training document sequence, into long single vector sequences, and pre-trained using language modeling objectives. The length of the sequences is maximized as far as processing power supports under the claims that using longer sequences trains the model to handle long-term dependencies. Also, the authors have added some auxiliary goals, like POS tagging, chunking, and named entity recognition, during pre-training, which have helped by (a) improving the generalization of the supervised model, and (b) accelerating convergence.
2. Fine-Tuning:
For fine-tuning, the authors have used a traversal model, which means they have attached the input and output on a single vector; for the tasks which require generations and for the tasks like similarity comparison, pairs of sentences are concatenated separated by a unique separator character.

Textual entailment: For entailment tasks, we concatenate the premise p and hypothesis h token sequences, with a delimiter token ($) in between.
Similarity: For similarity tasks, there is no inherent ordering of the two sentences being compared. To reflect this, we modify the input sequence to contain both possible sentence orderings (with a delimiter in between) and process each independently to produce two sequence representations h m l which are added element-wise before being fed into the linear output layer.
Question Answering and Commonsense Reasoning: For these tasks, we are given a context document z, a question q, and a set of possible answers {ak}. We concatenate the document context and question with each possible answer, adding a delimiter token in between to get [z; q; $; ak]. Each of these sequences are processed independently with our model and then normalized via a softmax layer to produce an output distribution over possible answers.
These are the ways the fine-tuning is arranged.
Model Specifications and Data: To pre-train the model using language modeling, the authors have used the BooksCorpus dataset for training the language model. It contains over 7,000 unique unpublished books from a variety of genres, including Adventure, Fantasy, and Romance.
We trained a 12-layer decoder-only transformer with masked self-attention heads (768 dimensional states and 12 attention heads). For the position-wise feed-forward networks, we used 3072 dimensional inner states. We used the Adam optimization scheme [27] with a max learning rate of 2.5e-4.
This section describes the model architecture. I am directly quoting from the paper to avoid discrepancies and it is pretty simple to understand with the knowledge of the real transformer architecture.
The Improvements Over The Years
Till now we have discussed the working of the first GPT model. Since then, OpenAI has been working to improve the performance, performing numerous tweaks and using the improvements in the big data world.
Language Models are Unsupervised Multitask Learners
This paper was released by OpenAI in 2019, which unveiled GPT-2 as a successor model of GPT, the basic version. OpenAI released a paper and a smaller model compared to the actual model, which they didn’t release as they expected people to misuse the model’s capabilities.
OpenAI said that the sole aim of this model is its generative capability improvement, that is, it can predict the next words optimally. The authors observed all the state-of-art models followed a semi-supervised learning approach but were very brittle and sensitive to the target task, that is, they will diverge if trained to do a different target task. To mitigate this, the authors wanted something more generalized. The authors basically wanted to set up a Zero-shot learning setting for downstream tasks, which means no extra dataset should be required for fine-tuning, and it will be completely unsupervised.
Multitask learning or meta-learning supposedly emerged as a stable framework to achieve such a goal. The works on the topic have achieved decent performance on 17 tasks using an amalgamation of 10 datasets. The authors realized that the difference between specific task learning and multi-task learning is basically the probability the model has to predict, which is P(output/input) for a specific task learning but P(output/input, task) for multitask learning as it might vary. From different task-conditioning works (that is, when a single objective task is represented as a chain of different target tasks, and the model is tested to perform on them), it was observed that the model performed best if the global minima of the unsupervised pre-training task that is Language modeling, coincides with the global minima of the supervised task of fine-tuning, so the ultimate target was to optimize the unsupervised task and find the best global minima. It was established from ablations that this can be achieved given a sufficiently large dataset.
Dataset: The authors leveraged the knowledge from a web scraper named Common Crawler used for similar work and devised their own crawler to create a dataset named WebText, containing the text subset of these 45 million links, 8 million text documents resulting in 40GB of data. The authors also used BPE or Byte-Pair Encoding, which draws a line between word-level and character-level encoding to enable the model to train on any type of data.
Model Modifications: The authors slightly modified the transformer decoder block to add a normalization layer before the block as a kind of pre-activation and another normalization and residual connection after the final self-attention layer. The model overall contained 1.5 billion parameters and was ten times more than the GPT-1 model.
Finding: Pre–Training this huge model on a huge amount of generic data like Wikipedia extracts, the researchers have observed the generative model works fairly well without any sort of fine-tuning. These gave rise to the concept called Zero-Shot Learning, as the models do not require any amount of labeled dataset to train on and can still deliver performance.
Paper link: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Conclusion
In recent years, OpenAI has developed GPT3 and much more using several concepts like multitask learning which is another story to tell, as this is already too long. In this article, we have seen the evolution of the NLP world till GPT-2. The further developments we will see in the next articles of the series.
[Update] The next part of this series talks about BERT. Please visit this page, if interested.
Happy Reading!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

