



META’s PEER: A Collaborative Language Model
Last Updated on November 17, 2022 by Editorial Team
Author(s): Salvatore Raieli
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
PEER (Plan, Edit, Explain, Repeat): collaborate with the AI to write a text
In recent years, language models have shown incredible capabilities (text summarization, classification, and generation). We have been accustomed to GPT-3 and the various apps that allow writing using a short text prompt. On the other hand, these models generate the final text but cannot be able to edit it (modification, editing, and so on). In the real world, the workflow requires multiple users to be able to edit the text to a final, high-quality version.
Recently, a new model published by META (in collaboration with Carnegie Mellon University and INRIA) produces text in a manner similar to what humans do: composing a draft, conducting edits, adding suggestions, and even able to explain its actions.
Meta AI on Twitter: "(1/4) Writing is often a collaborative process: We start with a draft, ask for suggestions & repeatedly make changes. Today we're introducing PEER, a model trained to mimic this process, enabling it to incrementally write texts and to collaborate with humans in more natural ways. pic.twitter.com/J92hIq8oRe / Twitter"
(1/4) Writing is often a collaborative process: We start with a draft, ask for suggestions & repeatedly make changes. Today we're introducing PEER, a model trained to mimic this process, enabling it to incrementally write texts and to collaborate with humans in more natural ways. pic.twitter.com/J92hIq8oRe
As the authors state, language models normally produce output in a single pass from left to right (they predict one word after another). This is not the way humans produce text. Typically, the approach is more collaborative, where the same author or other authors make changes or refine the text. This is also important because not all text produced by models is quality text (we talk about hallucination when the model generates content that does not make sense in the discourse). In addition, language models do not explain why they produce output.
The model proposed by META acts according to the pattern defined in the figure: the model proposes a plan (ex., propose editing), this plan is then realized with an action (editing), and this action is then explained (through a textual explanation or link to a reference), and the process is repeated until the text is satisfactory.
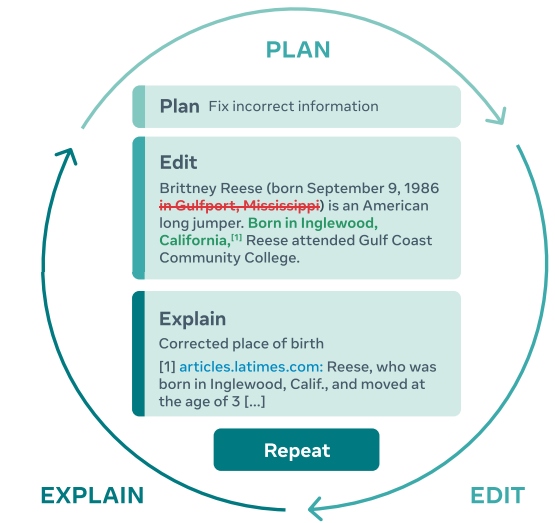
This iterative approach does not only enable the model to decompose the complex task of writing a consistent, factual text into multiple easier subtasks, it also allows humans to intervene at any time and steer the model in the right direction, either by providing it with their own plans and comments or by making edits themselves. — original article (source)
The authors summarize the results:
- the introduction of a collaborative model.
- The creation of a model to infill parts of the writing process and leveraging self-training techniques. This makes it applicable to any domain.
- The model represents state-of-the-art and outperformed several baselines.
- The authors release several PEER models, the data, and the code to train them.
Of course, the first challenge in being able to train such a model is to find the right dataset. Indeed, as the authors state:
This is mainly because edit histories are difficult to obtain from web crawls, the most important data source for current language models (Brown et al., 2020; Rae et al., 2021). But even in cases where edit histories can be obtained (e.g., by collecting crawls of identical pages at different times) or synthetically generated, edits are typically not annotated with plans, documents, or explanations.
The authors, to solve the problems, filtered out poor quality entries (low quality, made by bot and vandalism) and other preprocessing. They also supplemented the dataset with synthetic data generation.
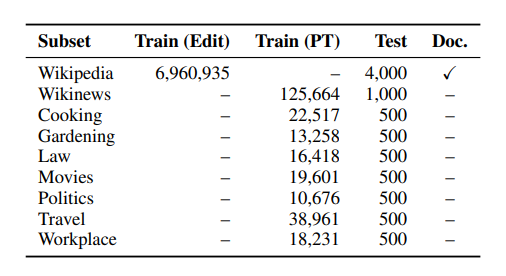
For this reason, the authors used Wikipedia. In fact, not only does the site provide quality text on multiple topics but it also has a full edit history (comments, citations). Of course, using a single source also has its drawbacks: the model is specific to one terminology and will produce texts similar to the training set. In addition, the authors noted that many of the comments on Wikipedia are noisy, and not all documents contain adequate information.
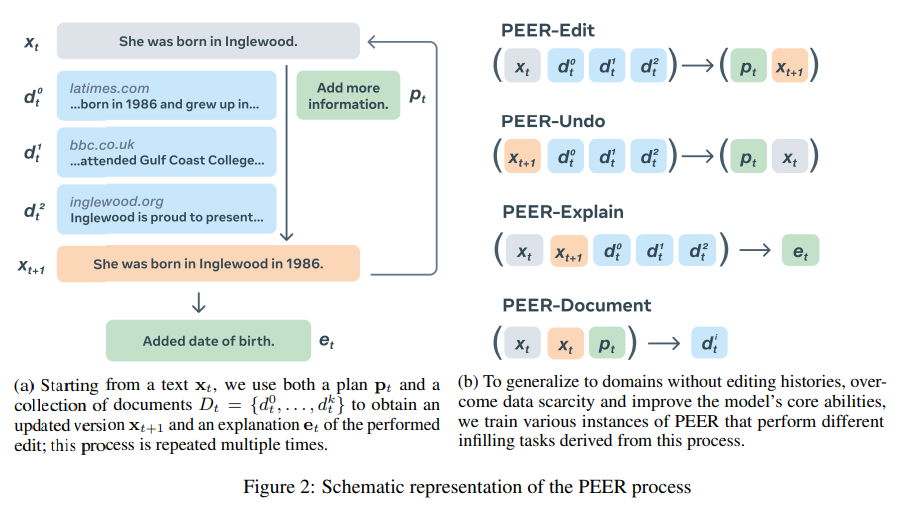
Moreover, to solve this problem, the authors decided to train several models that each learn a part of the editing process:
- PEER-Edit: the model learns to plan and realize edits. it learns how to edit by itself, but the user can also provide edits
- PEER-Undo: it is trained to guess and undo the latest edit
- PEER-Explain: it is trained to generate explanations
- PEER-Document: it is trained to generate a document that provides useful background information for the edit
To train PEER as a general-purpose model, which can then be suitable for different fields and different collaborative tasks, the authors did several experiments:
- Can PEER propose plans and edits in domains where there are no examples available? Is self-training enough?
- Can PEER follow human modification propositions?
- Can PEER suggest the right citations? and are the documents useful?
- Is PEER superior to single-pass models?
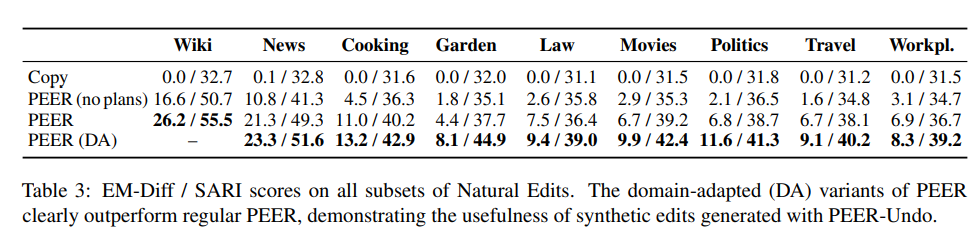
For the first question, the authors collected other encyclopedic pages from Wikipedia, posts from Wikinews, and posts from the Cooking, Gardening, Law, Movies, Politics, Travel, and Workplace subforums of StackExchange. PEER, as the results show, is able to apply what it has learned from the Wikipedia story to other fields. In addition, The model without plans and documents had a drop in performance.
The authors also checked whether PEER could be capable of other downstream tasks using different specific datasets (grammatical error correction, text simplification, editing, mitigating or removing biased words in the text, finding updates for Wikipedia pages, inserting a sentence in a Wikipedia). PEER also was compared with Tk-instruct, T0, and T0++(variants of T5), GPT3, and OPT (an open-source replica of GPT3). PEER outperformed these models despite the fact that both GPT3 and OPT are larger.
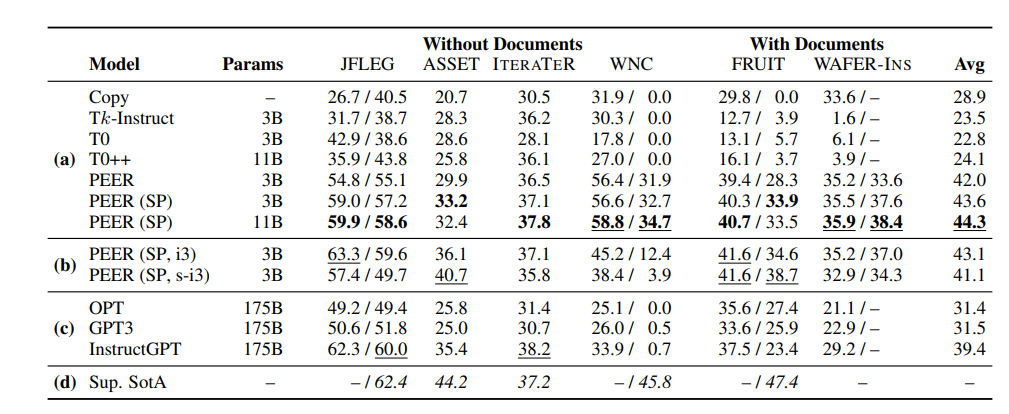
In addition, PEER is capable of presenting citations and quotes from reference papers, allowing better explainability and verifiability. The authors also introduced two new datasets (NE-Cite and NE-Quote) to see if the model was capable of quoting specific passages instead of the entire document. The model succeeds in suggesting the appropriate citation for the text.
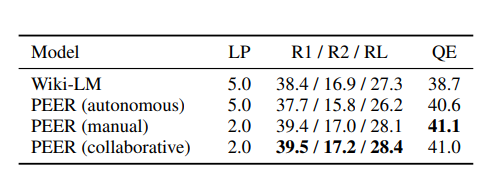
Furthermore, the authors tested the model’s ability to generate text from scratch(text generation) by selecting three possible scenarios: model alone, with human plan suggestions, and collaborative model. The results show that the collaborative system is the best.
The authors also showed an example of a collaborative session with PEER:
As can be seen in Figure 4 (left), PEER is capable of extracting and composing information from various documents to follow the provided plans. It makes some plausible assumptions, such as the model being developed by Meta AI, despite this not being explicitly stated in any of the documents, and is able to point to the author list (document 0) as a reference for this claim. The model’s response to the fifth plan (“Add info on the scandal”) illustrates a fundamental issue with many pretrained language models: It accepts the premise of this plan and follows it by hallucinating a scandal about internet censorship. However, unlike traditional left-to-right models, PEER is able to correct the misinformation it has produced in the next step

The authors discussed several limitations:
- Approach. One limitation is the fact that assumptions were made that are not always possible in the real world (papers available for each edit). Also, citations can be misleading, as when the model hallucinates, the citations give the impression that the model is more authoritative and confusing to the user. Also, the representation of inputs and outputs makes it inefficient to handle entire documents.
- Evaluation. The first limitation is that all evaluations were done in English. The authors also state that they have explored the collaborative potential in a very limited way (this, however, would require a retrieval engine on the fly that would allow documents to be found on the Internet).
In conclusion, the model presents a very interesting approach, where leveraging a language model as an assistant can suggest modifications (“from syntactic and stylistic edits to changing the meaning of a text by removing, updating or adding the information”) in different domains. Although the model has several limitations, it is the first step for an AI writing assistant that collaborates with humans. Although the authors have announced that it will be available at the moment, there is no open-source repository. What are your thoughts on it? Curious to try it out? Let me know in the comments.
If you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Or feel free to check out some of my other articles on Medium:
- How artificial intelligence could save the Amazon rainforest
- Meta’s ESMfold: the rival of AlpahFold2
- DreamFusion: 3D models from text
https://medium.com/mlearning-ai/generate-a-piano-cover-with-ai-f4178bc9cb30
META’s PEER: A Collaborative Language Model was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

