



How To Make AI Fair And Less Biased
Last Updated on July 25, 2023 by Editorial Team
Author(s): Padmaja Kulkarni
Originally published on Towards AI.
A practical framework to mitigate biases and risks in AI
In the wake of Elon Musk firing the whole ‘Ethical AI’ team at Twitter [1], I believe it is more important than ever to understand the impact and, thus, the need for ethical, fair, and unbiased AI in society.
We want to use AI for its unparalleled accuracy and ability to outperform humans. We hope that a data-backed decision-making AI framework will be fair and remove human biases. More often than not, however, these algorithms (AI) can be biased and even amplify human biases. For example, Twitter published a report [2] on how its AI promoted right-leaning news sources more than left-leaning ones. Such an AI holds power to shape the political opinions of millions of people — unless we take stpes to prevent it.
Another interesting example of unintentionally biased AI is Gild. Gild created a candidate selection system for developers based on their publicly available code and social activity. Although this software was developed to reduce bias in hiring, it was realized that this platform preferred candidates who tend to comment on Japanese Manga websites. Women are less likely to visit this website, given the website’s often sexist content. The software thus propagated bias against women when similar profiles were considered for selection. A similar story is exists for Amazon’s AI recruting platform. Another well-known example of AI biases is IBM and Microsoft’s face recognition algorithm, which were consistently found to perform with the poorest accuracy in female, Black, 18–30 years old subjects [3].
I explore why biases arise with examples and provide a practical framework that could help mitigate these biases.
Exploring biases in AI
Although most biases can be ultimately pinned on the humans who design the AI system, we can further categorize them as follows:
1. Data biases
These biases arise due to biases in the training data. One of the reasons for the data bias is under Representation of a few data points. I found an example of such biases in the state-of-the-art image-generating AI — Stable Diffusion [4]. I asked Stable Diffusion to produce an image of a doctor; all the images it generated were of male doctors. This would be the result of biased data, where the algorithm learns that doctors are males by default.
These biases arise when the training data sample can not be generalized for the whole population or the data is not representative. For example, in the case of the face recognition software above, the data failed to represent a significant population group.
2. Popularity biases
These biases appear when algorithms are designed to have the frequency of occurrence as a feature. A few years ago, photos of Trump started popping up when people searched for the word idiot. He is still present in search results today. This was the outcome of people in the UK manipulating Google’s algorithm by repeatedly linking the two words together after his visit to the country.
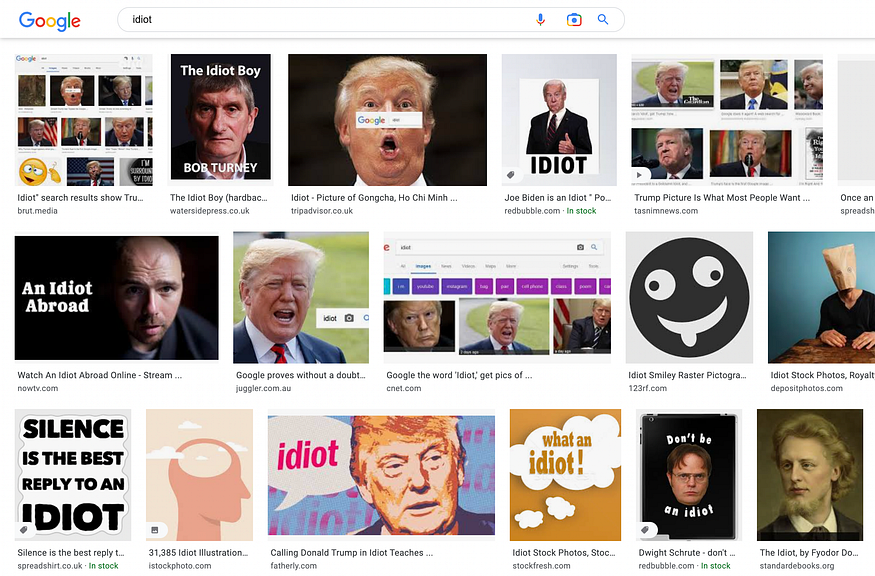
3. Evaluation method bias
This means that algorithms become biased due to how we evaluate their success. For example, a highly accurate algorithm for a biased dataset will produce biased results if precision and/or recall are poor.
The real-world datasets tend to be unbalanced. For example, choosing accuracy as a matrix to classify data of patients, where over 95% of patients are healthy, would be a mistake. The reason is the AI can achieve 95% accuracy just by classifying all patients healthy. Additionally, traditional algorithms optimize for accuracy, precision, and recall. Why couldn’t the bias be one of the criteria?
4. Bias due to the model drift
This happens when the current data diverges from the training data — the model predictions are no longer valid. For example, spam emails today have changed entirely and become more sophisticated compared to a few years ago. Failing to take into account these trends would result in incorrect predictions.
5. Attribution bias
Such biases occur when an AI system learns false extrapolations. For example, based on the current characteristics of a company, an AI system can learn to give more weight to people who graduated from certain schools and show prejudice against those who didn’t, despite the same profiles.
6. Definition bias
In the dynamic world, not having updated definitions of goals would lead to a problem of definition bias.
Due to strikes, Schipol airport ended up having long queues for extended periods. The airport has a great app that informs you of longer waiting times if any. As the app dynamically adapted to current waiting times, it said ‘normal waiting time,’ even when people had to wait for ~3-4 hours in line (as opposed to ~30 minutes pre-COVID and pre-strikes).
7. Human bias
This could happen as humans can unknowingly use or omit input features that may bias the algorithm predictions. Additionally, as humans design AI systems, failing to account for any of the biases above can be attributed indirectly to humans.
Framework against AI biases
Minimizing biases is essential to ensure the trust of humans in AI. To this end, I hope the framework below helps put that into practice.
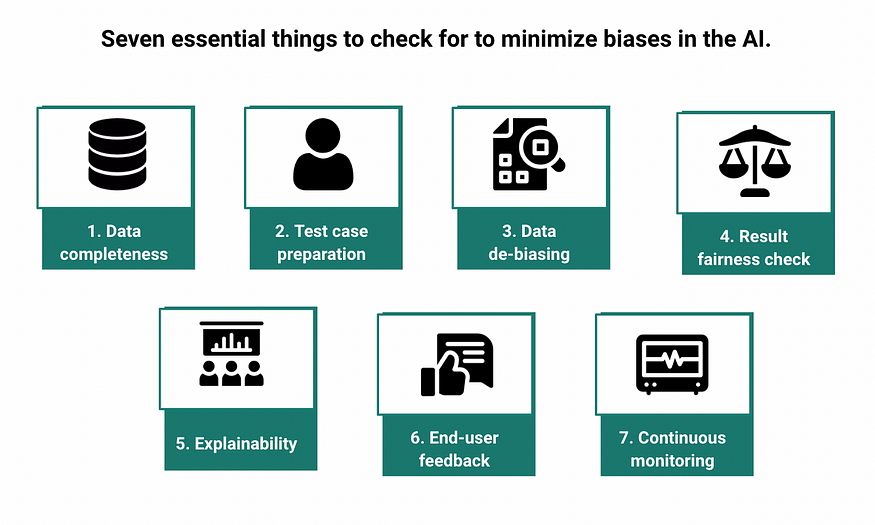
1. Use of complete and fully-representative data is possible
We can always train a model with the available data with acceptable accuracy. Making sure that the data is complete and represents the above-mentioned edge cases would already help in building a fair model. Data scientists could go to an extra length and set up additional experiments to ensure the representativeness of the data.
2. Prepare test cases beforehand
Brainstorming edge-case scenarios should be done even before one trains the algorithm. An example is to think if the algorithm can be biased on race, age, gender, and/or ethnicity. Along with helping in designing the features better, this will reduce underlying data and human biases, if any.
3. De-bias the data
All the standard de-biasing methods, such as over or undersampling, feature engineering, and reweighing, can mitigate the data bias and allow for a better representation of the minority groups (data points) in the algorithm. However, it is essential to analyze whether these changes affect edge-case groups and if the trade-off between accuracy and fairness is justified. The formula in the next point can help decide how to evaluate this trade-off objectively.
4. Check for fairness of the algorithm results based on the test cases
A naive way to check if your results are biased is to plot correlations between the features and results. If you find a strong correlation between algorithmic results and the features such as race, age, gender, and/or ethnicity, it is likely that the model is biased. Based on the fairness index and accuracy, such a trade-off can be decided.
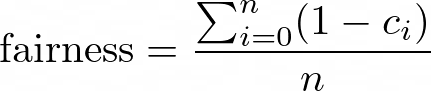
5. Check for the explainability of algorithms
It is always a good first step to see if simple algorithmic results will do before diving into complex algorithms for your use cases. If you are using regression, you can check what features have more weight. This will already tell you if the algorithm is biased.
While using more complex algorithms, techniques like LIME [5] or SHAP [6] values can be immensely helpful. Using these techniques should not be an optional exercise but a must if you want to have an insight into how your algorithm is making decisions.
6. Ask for feedback for the end users
Performing targeted testing, and aggregating feedback from real users can help evaluate the trained model.
7. Continuous monitoring and check for data drift
Despite taking all precautions, the models are bound to drift and produce biased results in this dynamic world. Redefining the goal and resulting definitions based on the latest data and automating data-drift monitoring and evaluation would avoid the trap. Standard methods such as DDM (drift detection method), EDDM (early DDM), or Frameworks like Mercury can be used for data drift analysis.
Along with these concrete measures, in the longer term, Holistic organization-wide changes are needed to combat AI biases, including having diversity in the data team itself. This could also mean involving social scientists or humanists in some critical projects. This brings in different perspectives and can shape the projects better. Making sure the data team is encouraged and well-equipped to take an extra step to ensure their algorithms are fair and unbiased is the bare minimum that an organization can do for AI to perform its intended purpose.
References:
[1] Elon Musk Has Fired Twitter’s ‘Ethical AI’ Team, wired.com, Nov 2022.
[2] Algorithmic Amplification of Politics on Twitter, Huszár et al. Arxiv, Oct 2021.
[3] Face Recognition Performance: Role of Demographic Information, Klare et al., IEEE transactions on information forensics and security, vol. 7, no. 6, Dec 2012.
[4] High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach et al., CVPR 2022 Oral.
[5] “Why Should I Trust You?” Explaining the Predictions of Any Classifier, Ribeiro et al., ArXiv Aug 2016.
[6] A Unified Approach to Interpreting Model Predictions, Lundberg et al., ArXiv Nov 2017.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

