



Meta’s Hokkien: AI Translates an Unwritten Language for the First Time
Last Updated on October 22, 2022 by Editorial Team
Author(s): Salvatore Raieli
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Speech-to-speech model for a language that is passed down predominantly orally
So far, most AI-based translation systems are focused on written languages. Most of the 7,000 known languages do not have a standard written form. This has made it difficult to apply the models used so far. Meta recently presented an AI model of translation for a primarily oral language: Hokkien. Why is this important?
All the words that are not written down

40 percent of known languages (about 3500) do not have a standard written form, and many of these languages are widely spoken. Being able to translate languages that do not have a written form remains extremely complicated: the standard technique requires a large amount of written text in order to train the model.
For example, there are more than 2,000 languages in Africa, and most of them do not have a written form (80%). Many of these languages are endangered, and it is thought that they may disappear by the end of the century. In fact, in 1991 it was counted that at least 180 languages had fewer than 10 people (it was estimated that a language dies every 14 days).
Many cultures and languages remain passed down orally. Oral storytelling represents the storehouse of community culture and history. When a language disappears, all that disappears. That is why it is important to preserve them.
Several initiatives have been attempted to preserve them. The collection of both heads (for those languages that have a written form) and the recording in electronic form of those languages that are only oral.
Typically speech-to-speech translation (S2ST) is the process by which one translates from one language to another. Typically, these systems consist of three parts: automatic speech recognition (ASR), machine translation (MT), and text-to-speech synthesis (TTS). In recent years, efforts have been made to reduce the process to a single step to avoid propagation errors and increase efficiency. In addition, the classical approach requires that large corpora of written text exist.
For example, an English-to-French S2ST system would require having a large number of examples in the two languages. This is easily achieved for languages that are well documented and have received the attention of researchers and institutions. Most languages are not so fortunate, and there are few examples of translations. Moreover, the situation is not feasible for languages that do not have a written form.
Meta’s Hokkien
Meta AI on Twitter: "(1/3) Until now, AI translation has focused mainly on written languages. Universal Speech Translator (UST) is the 1st AI-powered speech-to-speech translation system for a primarily oral language, translating Hokkien, one of many primarily spoken languages. https://t.co/onYKQ8uoKN pic.twitter.com/Iy8MRMOypQ / Twitter"
(1/3) Until now, AI translation has focused mainly on written languages. Universal Speech Translator (UST) is the 1st AI-powered speech-to-speech translation system for a primarily oral language, translating Hokkien, one of many primarily spoken languages. https://t.co/onYKQ8uoKN pic.twitter.com/Iy8MRMOypQ
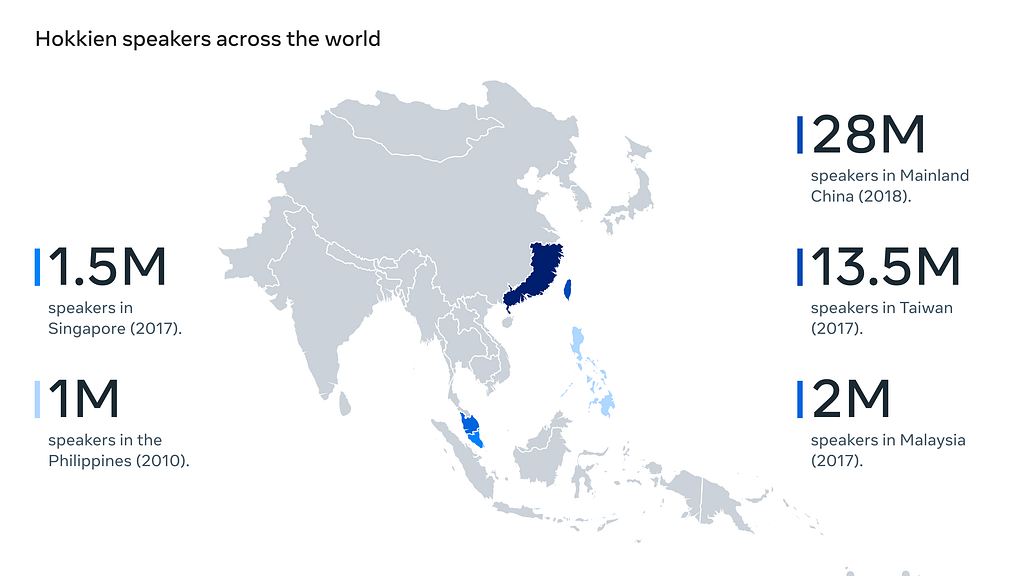
A few days ago, Meta introduced a new model, Hokkien. Hokkien is an S2ST model capable of translating between English and Hokkien. It is a language that is prevalently handed down orally. Hokkien is one of the official languages of Taiwan and is spoken in southeast China and Chinese diaspora countries (Singapore, Indonesia, Malaysia, and the Philippines). Today it is spoken by about 30 million in mainland China and 13 million Taiwanese. The language is passed down orally, although some attempts have been made to transcribe it with Chinese characters (Hanji) or to Romanize it.
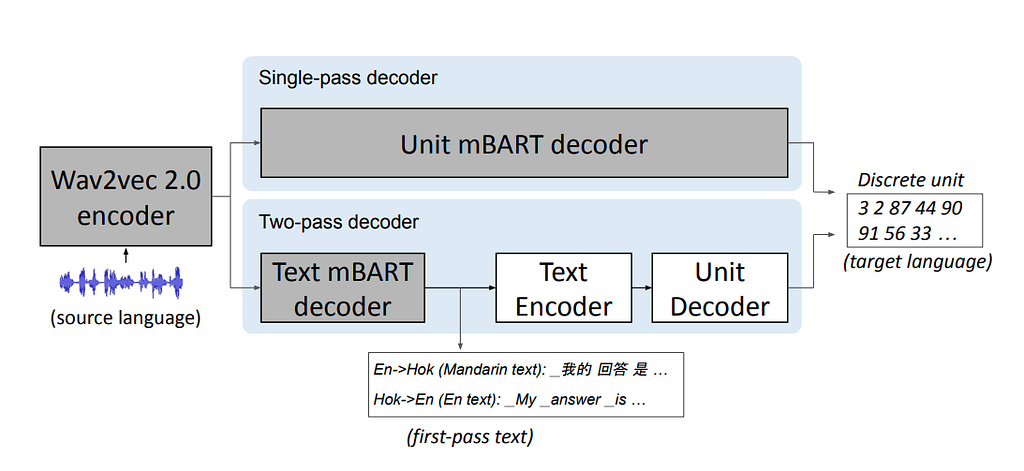
“Our team first translated English or Hokkien speech to Mandarin text, and then translated it to Hokkien or English — both with human annotators and automatically,” said Meta researcher Juan Pino. “They then added the paired sentences to the data used to train the AI model.” — source
As mentioned by the Meta researchers, they took advantage of the fact that there were Hokkien annotations in Mandarin Chinese. Also, being Chinese close as a language helped the model better understand patterns.
we focused on speech-to-speech translation. To do this, we developed a variety of methods, such as using speech-to-unit translation to translate input speech to a sequence of acoustic sounds, and generated waveforms from them or rely on text from a related language, in this case Mandarin. — Meta AI blog post (source:here)
The model is composed of several parts. The first part is an encoder that takes speech as input directly. After that, there are two components, a decoder that directly transitions into the target language (single-pass decoder) and a model that takes advantage of the annotated text (two-pass decoder). The two-pass-decoder uses a model that translates to a target text (if the language as input is Hokkien, it translates to Mandarin). This second model allows for extra supervision and makes the model more accurate.
The researchers also used Mandarin because there are not many people who are bilingual in English and Hokkien. Using Mandarin allowed them to have a pivot language while creating supervised human-annotated data. They used different sources (such as Hokkien dramas, Hokkien transcripts, and so on) as datasets. They also recruited a small group of people who could translate between English and Hokkien to have still examples of Hokkien speech translated into written English.
Moreover, evaluating oral translations for an unwritten language like Hokkien is not an easy challenge. In order to be able to evaluate the result, the authors developed a system that transcribes speech content into a standardized alphabet. On these transcriptions, they then calculated the BLEU score (considering syllables).
Parting thoughts
Meta’s new model represents a step forward because it reduces what typically required several models into a single step. In addition, the model succeeds in translating from a language such as Hokkien that has no written form. the approach used, such as the use of an intermediate language (Mandarin) to improve the translation, is also interesting.
These are not easy challenges. For the most widely used languages, there are large datasets that have been finely curated, whereas, for most languages, these resources do not exist. On the other hand, speech-to-speech is even more complex and generally requires text translations, which for many languages, are lacking.
The elimination of language barriers is another step toward inclusion. Translation into languages that are underrepresented allows people to be able to take advantage of the information in their native language. This allows better access to ideas and information.
Meta has invested several resources in recent years in expanding simultaneous translation to as many languages as possible. Recently they presented No Language Left Behind, which can translate into more than a hundred languages (and learn using a few examples).
In fact, many of the models are bilingual, but scaling to more languages is quite difficult.
Of course, given how much Meta is investing in its Metaverse, it is safe to expect several more models in this direction. In fact, as stated:
“It can be a barrier to confidence, fluency, and authenticity,” Brown said. “We know at Meta that there are tons of people all over the world who have their interface set to English, who use English on our platforms — even though they are much more confident in other languages and writing systems. As soon as we give them the ability to do audio in their own language, their comfort and confidence in the digital space shoot way up.” (source)
For the time being, the metaverse does not seem to be a success at all (and there are also many doubts about its success). Whether the metaverse is a flop or not, Meta has made its models available in open source, and they can be used by the community.
if you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Or feel free to check out some of my other articles on Medium:
- Reimagining The Little Prince with AI
- Nobel prize Cyberpunk
- How artificial intelligence could save the Amazon rainforest
- Speaking the Language of Life: How AlphaFold2 and Co. Are Changing Biology
Meta’s Hokkien: AI Translates an Unwritten Language for the First Time was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

