


Machine Learning Interview Questions-2
Last Updated on July 24, 2023 by Editorial Team
Author(s): Gundluru Chadrasekhar
Originally published on Towards AI.
Careers, Machine Learning
Ace your machine learning interviews
1) What is the internal covariate shift and what are the consequences of it?
- Internal covariate shift occurs when the statistical distribution of input data changes drastically with respect to other input data.
- When the input data distribution changes, hidden layers try to learn to adapt to the new distribution. This slows down the training process, thus taking a long time to converge to a global minimum.
2) What is early stopping in deep learning?
- Early stopping is a regularization technique. Overtraining a model on a dataset will cause overfitting.
- Therefore it is required to stop the training when the model starts to overfit. This process of stopping the training early is called early stopping. In early stopping, hyperparameters could be no. of epochs, generalization error, cross-validation, model performance.

3) Why does regularization help reduce overfitting?
- Regularization focuses on restricting the model weight. Due to the weights being restricted whenever there is a slight change in input data, the output doesn’t change drastically.
- Though this procedure results in adding bias terms, the model’s variance is reduced, thus generalizing the overall model.
4) What is the Jaccard Index, and how is it used in object detection?
- The Jaccard Index is used in understanding the similarities between sample sets. It is formally defined as the size of the intersection divided by the size of the sample sets’ union. For detecting objects, the Jaccard index quantifies the similarities between the actual and predicted object.
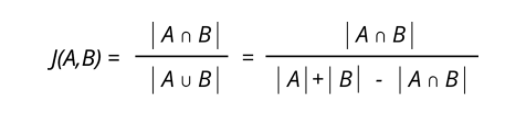
5) Provide instances where precision is more important than recall
- Precision is nothing, but out of all the cases predicted as valid, how many times we were true. If you are predicting but suitable for under 18 people, you can afford to reject a few books but cannot afford to accept bad books. If you are predicting thieves (hand pickers) in a supermarket, we need more precision. Because of False positives, in this case customer trust will decrease.
6) Which is the most interpretable ML/DL model in your opinion, and why?
- decision tree algorithms as the most interpretable in AI. It enjoys the ‘most white box’ status from the majority of data scientists too. Because decision trees are order collection of values (data in this case), it’s visualizable ability is the highest as it performs true or false operations.
- Further, entropy used for splitting represents the disorders in the real world.
7) Why do we use the Local Outlier Factor?
- Local Outlier Factor (LOF) is a density-based algorithm for anomaly detection. LOF is used in an unsupervised setting to find out Local anomalies in the data.
- Typically, global anomalies can be easily found by other techniques. But local anomalies are not detected via other algorithms because they appear in groups.
- This is precisely why the density-based technique is preferred over distance-based techniques.
8) Why is bag-of-words not applied to deep learning?
- Bag-Of-Words (BoW) is a tokenization method that does not preserve the order. It generates a token that is understood as text and not as a sequence. Further, the structure of the sequence also won’t be preserved.
- It gives problems while doing feature engineering. So, BoW is typically used in traditional machine learning and not used in deep learning.
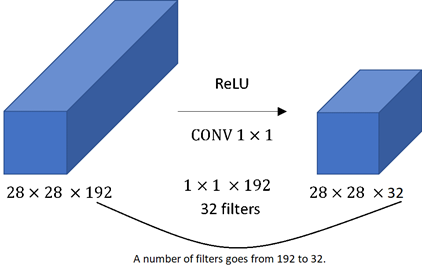
9) What is the need of using 1×1 convolution filters?
- While pooling reduces height and width, there was no efficient technique available to reduce the depth.
- The depth could be reduced by using filters with padding but using 3×3 or 5×5 filters is quite expensive in terms of training and thus in order to reduce the depth efficiently 1×1 convolution was introduced.
10) How to handle low-quality data?
- Data science is driven by data. Low-quality data is a common scenario we can tackle by the following means
1) Data cleaning: missing value imputations, outlier handling, balancing data through sampling
2) Data augmentation: Generating more data from existing and available data.
3) Data risk analysis: we should establish data reliability and risk involved
11) Why does SGD with momentum outperform the traditional SGD optimizer?
- The problem with SGD is that it highly oscillates on its path towards global minima. Thus it might happen it gets stuck on some local minima or might take some time to converge.
- In SGD with momentum, we have added a momentum term so that the overall gradient depends on both the current and previous gradients. Thus causing faster convergence and reduction of oscillation.

12) What is a noise injection?
- Noise injection is a method of regularization. It involves indirectly penalizing the complex models by adding noise to the training data.
- The added noise is selected based on the chosen kernel and acts as an artificial noise, making it difficult for the model to train. Generally, noise added is selected from a Gaussian distribution, and mean and standard deviation acts as a hyperparameter.
13) Why are ResNets not affected by the depth of the network?
- As the depth of the network increases, vanishing/exploding gradients become significant and affect the accuracy of the model.
- To curb this issue, ResNets introduced the concept of the residual network. Here, we use skip connections.
- The advantage of skip connection is that if there is any layer in the network which is hurting our model performance then it will be skipped by regularization. Thus allowing us to increase the depth of the model without worrying about accuracy.

14) What is transpose convolution?
- Transpose convolution is used for upsampling in the neural network when we require to increase the height and width of input.
- This operation is generally required in the variational autoencoders and generative adversarial networks.
- Transposed convolution layers require weights to be learned first before performing convolution operation. Therefore traditional interpolation techniques are faster, but their results are not as efficient.
15) What is BLEU Score?
- BLEU is the acronym for Bilingual Evaluation Understudy. It is used to evaluate the sentence generated using DNN with respect to a reference sentence.
- It ranges from 0 to 1, where 1 signifies a perfect match and 0 signifies a perfect mismatch.
- BLEU score is easy to compute and understand, is language-independent, has a high correlation with human evaluation, and is widely adopted. BLEU score use case extends to language generation, image caption generation, text summarization, and speech recognition.
16) What are the conditions for proper initialization of the weights in deep neural networks?
- Proper weight initialization is essential because it decides the course of training our model takes. A wrong initialization may take a much longer time for convergence or even not converge at all. One of the leading causes of slow convergence is exploding/vanishing gradients. To avoid this, any weight initialization must have the following rules:
- Activations mean should be zero across every layer of the network.
- The variance of the activations should stay constant across every layer of the network.
Further Reading:
16 Interview Questions That Test Your Machine Learning Skills (Part-2)
Ace your machine learning interviews
medium.com
Ace Your Machine learning Interview with How and Why questions.
It’s all about How and Why?
medium.com
16 Interview Questions
Every Machine Learning Enthusiast Should Know
Its all about how and why?
medium.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

