


Machine Learning at Scale: Model v/s Data Parallelism
Last Updated on August 29, 2023 by Editorial Team
Author(s): Shubham Saboo
Originally published on Towards AI.
Decoding the secrets of large-scale Machine Learning
Introduction
As models grow increasingly complex and datasets become gigantic, the need for efficient ways to distribute computational workloads is more important than ever. Old-school, one-computer setups can’t keep up with today’s ML computing needs.
Big Question: How can we distribute these complex machine learning jobs (model training and inference) across multiple computing resources effectively?
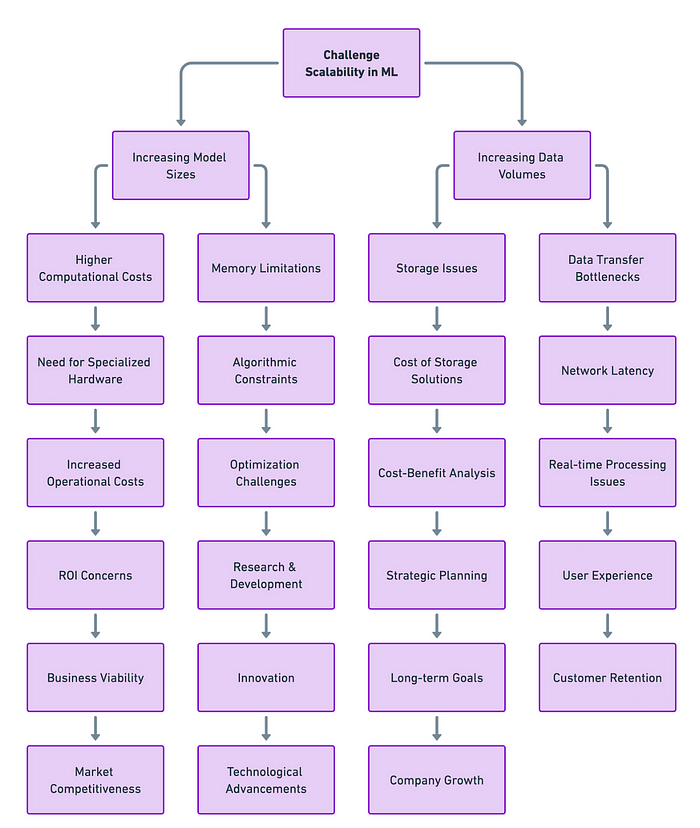
The answer lies in two key techniques of distributed ML computing: Model Parallelism and Data Parallelism. Each has its strengths, weaknesses, and ideal use-cases. In this article, we’ll dive deep into these techniques, exploring their nuances and comparing them head-to-head.
What Are Model Parallelism and Data Parallelism?
Model Parallelism
This method involves distributing different parts of the machine learning model across multiple computing resources, such as GPUs. It’s the perfect antidote for those oversized models that can’t fit into a single machine’s memory.
Data Parallelism
On the other hand, data parallelism keeps the model on each machine but distributes the dataset into smaller chunks or batches across multiple resources. This technique comes in handy when you have large datasets but models that easily fit into the memory.
Model Parallelism: A Closer Look
When to Use It?
Ever tried to load a big neural network on your GPU and gotten a dreaded “out-of-memory” error? That’s like trying to fit a square peg in a round hole. That just won’t work. But don’t worry, model parallelism is here to help you out.
How Does It Work?
Imagine your neural network is like a multi-story building, with each floor being a layer of the network. Now, what if you could put each floor of that building on a different piece of land (or in our case, a different GPU)? That way, you’re not trying to stack the whole skyscraper on a tiny plot. In tech-speak, this means breaking up your model and putting different parts on different GPUs.

Challenges
But it’s not all smooth sailing. When you break up the building, or the neural network, you still need stairs and elevators (or data pathways) to move between the floors (layers). And sometimes, these can get jammed. In other words, the main challenge is getting the different parts to talk to each other quickly and smoothly. If this communication is slow, it can slow down the whole process of learning or ‘training’ the model.
Data Parallelism: A Closer Look
When to Use It?
Imagine you have a really big pile of data, but your machine-learning model isn’t too complex. In this case, Data Parallelism is like your go-to kitchen blender; it can easily handle all the ingredients you throw in without getting overwhelmed.
How Does It Work?
Think of each computer or GPU as a separate kitchen with its own blender (the model). You take your big pile of data and divide it into smaller portions. Each “kitchen” gets a small portion of data and its own blender to work on that data. This way, multiple kitchens are making smoothies (calculating gradients) at the same time.
After each kitchen finishes blending, you bring all the smoothies back to one place. You then mix them together to make one giant, perfectly-blended smoothie (updating the model based on all the individual calculations).
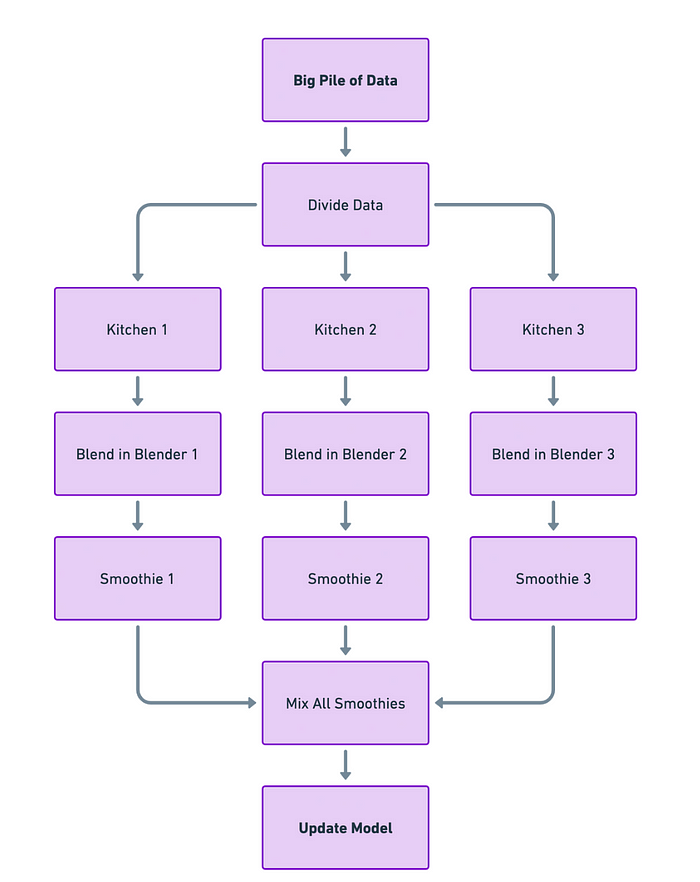
Challenges
The tricky part is the last step — mixing all those smoothies efficiently. If you’re slow or messy in combining them, you’ll not only waste time but could also end up with a not-so-great final smoothie (inefficient model training). So, the challenge is to bring everything back together as efficiently and quickly as possible.
In technical terms, this means you’ve got to find a fast way to collect all the calculated gradients from each GPU and update the model. If you don’t do this well, your model could take longer to train or even perform poorly when you start using it for real tasks.
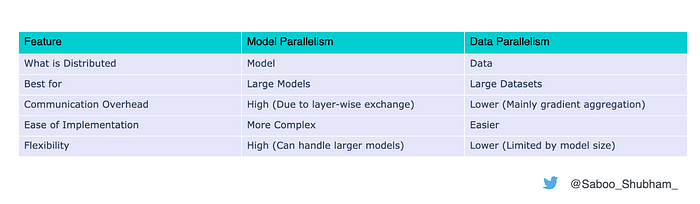
Summary of Differences
Why Not Both?
In the ever-complex landscape of machine learning, one size rarely fits all. A synergistic combination of both model and data parallelism is often employed for optimal results. For instance, you might break down a large model across multiple GPUs (model parallelism) and then distribute data to each of these parallel setups (data parallelism).

A mix of model and data parallelism is often the key to perfecting your ‘recipe’ for machine learning.
The Range Cooker Analogy for Machine Learning
In this analogy, the range cooker is like a single GPU or computer. It has both an oven and a stovetop, which you can use at the same time for different cooking tasks.
Oven = Model Parallelism
If you have a turkey that’s too big to fit into the oven, you might cut it into smaller pieces to cook separately — say, the breast in one section of the oven and the legs in another. This is similar to model parallelism, where a large model is divided across multiple GPUs. In this case, the oven compartments of a single range cooker represent parts of one GPU or one computing resource.
Stovetop = Data Parallelism
Now, let’s say you have different side dishes that you’re cooking on the stovetop burners. You can prepare the mashed potatoes on one burner while the green beans are sautéing on another. Here, each burner represents a data parallelism approach, where different portions of the data are processed independently but within the same GPU or computing environment.
Combining the Two for a Feast
Finally, to complete your feast, you’d be using both the oven and the stovetop at the same time. The turkey parts are in the oven (model parallelism), and the side dishes are on the stovetop (data parallelism). Once cooking is complete, you combine all the turkey pieces and sides to serve a full meal. Similarly, in machine learning, combining model parallelism and data parallelism allows you to efficiently process large models and big datasets, ultimately delivering a successfully trained model.
By leveraging both the ‘oven’ and the ‘stovetop’ in your machine-learning ‘kitchen,’ you can more efficiently cook up your data and models, making the best use of all the resources you have at hand.
Conclusion
As the field of machine learning continues to evolve, the importance of techniques like model and data parallelism will only grow and become increasingly relevant in day-to-day ML workloads. Understanding the nuances of both is critical for anyone looking to develop and deploy large-scale machine learning models like LLMs, Stable Diffusion, etc.
By choosing the right technique or a blend of both, you can overcome the challenges of modern machine learning and unlock scalability and efficiency for your ML workloads.
Interested in staying up-to-date with the latest in machine learning? Follow my journey to stay updated with fresh, cutting-edge AI developments U+1F447
Connect with me: LinkedIn U+007C Twitter U+007C Github

If you liked this post or found it helpful, please take a minute to press the clap button, it increases the post visibility for other medium users.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


