


")
Leveling Up Your Travel Agent Skills Through NLP (Part II)
Last Updated on May 10, 2021 by Editorial Team
Author(s): Navish
Natural Language Processing
Did you land at this article after looking at Part I? How exciting that you want to continue reading!
If you did not come from Part I of this article, which you can read here, it dealt with why NLP preprocessing is even necessary in the first place, some of the most common ways to preprocess text data, and an intuitive sense for what preprocessing technique to apply based on your natural language processing (NLP) use case. It also introduces my specific use case — a travel preferences-based recommendation system, built using reviews written by folks on Tripadvisor. To contain the scope, I am concentrating on Yosemite National Park.
Moving on to Understanding Topic Modeling!
The basic idea in NLP is to come up with different ways to convert text data to numerical data (while retaining the fundamental meaning of the text data itself) which can then be acted upon by computers for various downstream purposes. The most trivial way to do this is to make a bag of words using a Term Frequency or a TF-IDF vector. The columns in either of these cases are made up of every single n-gram word (aka token) found throughout the corpus. If you have 1000 documents, a unigram vector (each unique word is a column) could easily contain 5000 columns (one word in each column), a bigram vector (one column for each unique pair of words occurring together) could contain 100,000 columns!! This is far too many to be of any practical use in most cases.
Topic modeling takes the huge number of columns and reduces it down to a few columns (aka dimensions), typically 5 to 30 columns. It does this by using dimensionality reduction techniques that capture “a repeating pattern of co-occurring terms” in the collection of documents. The aim is to be able to use a few small topics that can be used to represent the documents and token columns with minimal loss of information.

Let’s say if we get 30 topics. The topic modeling process gives a score of how much each of the 30 topics relates to every document (reviews in my case). Each topic itself will be represented by the collection of original words (tokens) accompanied by a score of how much each of those words relates to the topic. In technical terms, these are known as the document-topic matrix and word-topic matrix respectively.

Topic modeling is a highly involved topic (pun intended), and if you’d like to dive deeper into its technical aspects, I would recommend starting with a deeper dive into dimensionality reduction first from this article and then following it up with this article on Topic modeling.
Q: So, are there any specific algorithms we can use for Topic Modeling?
NMF and LDA are 2 of the more famous unsupervised topic modeling algorithms. With these two, the number of resulting topics is the most influential parameter that you can control. But beyond that, they are quite “unsupervised” towards their results. There is no answer to whether the topics they generate are right or wrong — only if they are making sense in the context of what your goal is.
Typically, NMF has shown to yield better results when data is less (small document size, fewer documents) and LDA starts yielding more sensible topics when there is more data to go by.
We can use the top-scoring documents & words in each topic to ascertain if the topics are making any sense.
If all the top 5 (can check top 10 too — no hard number) scoring documents under a given topic has a consistent theme and are clustering around something you care about, then the topics are making sense. The same logic extends to checking for top-scoring words too.
Based on domain intuition, in my case, I expected reviews in a national park to recurrently mention if a place is easy or hard to hike, whether you can get good photographs from that attraction, etc.

Below are some of the challenges you can encounter during the topic modeling process itself to arrive at something “sensible”:
- The algorithm is picking up on certain recurring words that deplete it of the context that you need in your use case. In this case, you need to continue preprocessing your data till it does make sense towards the aimed objective. This could mean adding more custom stop words because the topics are centering around certain words that lead to unhelpful topics, or splitting words into bigram/trigram tokens, or POS-based filtering. In my case, names of attractions were prominently used in the original text data and the topics kept centering around that. They had to be removed cyclically in the preprocessing steps to get the desired output.
- The parameters used to initialize the topic modeling process itself may need to be tweaked. Either the model should be allowed to discover more (or fewer topics), or requires a higher number of iterations to abstract more sensible patterns.
- The algorithm of choice is not the most apt one for the provided context and a different one has to be used.
Most importantly, remember topic modeling is an iterative process and can be frustrating at times. Your topics might make no sense; especially at first.
But you have to iterate through the preprocessing steps AND the topic modeling steps to see what works for you to arrive at your ultimate collection of “sensible” topics.
Q: What algorithm did you use? Did You Arrive at any “sensible” topics?
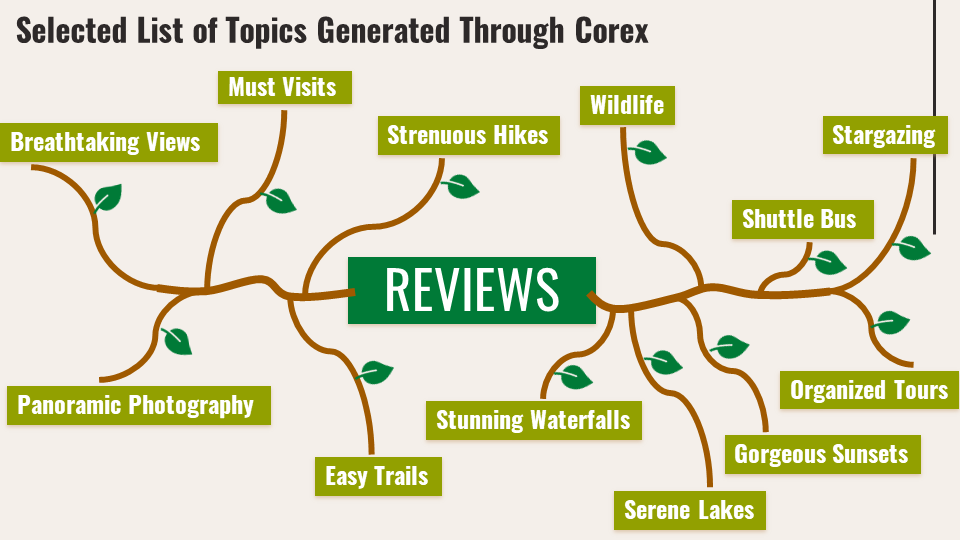
I used the Corex algorithm finally, as I loved its semi-supervised approach. What that means is that you can specify “anchor words” to help the algorithm create topics centered around these words particularly. Each desired topic can have multiple anchor words specified under it. It focuses on finding those and other closely occurring words to discover the final set of topics, along with the documents that relate to these topics closely.
You can even specify anchor words to explicitly separate out topics that are getting merged together.
Specifying anchor words is also an iterative process until you arrive at results that are sensible (yes, more iteration!).
I finally arrived at 12 sets of anchor words (some of which can be seen below), and 18 topics. Its recommended to keep a few extra topics compared to the number of anchor word lists, so that the algorithm can capture any other recurrent patterns that have not been explicitly specified through the anchor words themselves.
As a rule of thumb, you want to ensure each of your topics has ~5% or higher % of total documents under them (One document will typically be under multiple topics). When a topic has very few documents, you can potentially do away with the topic, by either removing the anchor words explicitly corresponding to them or reducing the overall number of topics.
Corex also has a score known as TC (Total Correlation) measured at an aggregate & individual topic level. You can read more about this and other aspects of Corex here.
Q: Which attractions do you recommend?
Depends on what you like!
For the final part of this project, I first gave labels to capture each topic’s meaning by looking at the anchor words, top-scoring words/reviews from the corpus for each topic.
Of these, I focused on using just 12 topics to create the recommendation system.
To create the recommendation system, I averaged the topic scores across all reviews at the attraction name level, such that each attraction name has a corresponding score on “Breathtaking views”, “easy hikes”, etc. So I had a vector of 12 dimensions for each attraction.
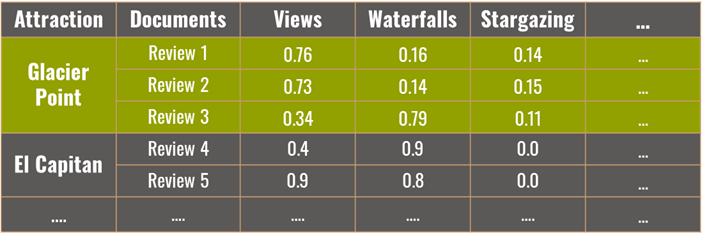
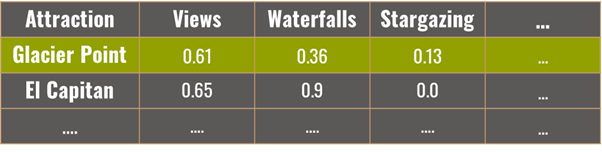
From here, I built a recommendation system where users can enter their top 3 preferences for the trip. These preferences are given a value of 1 while the other 9 preferences are given a value of 0, to create a “user input” vector of 12 dimensions.
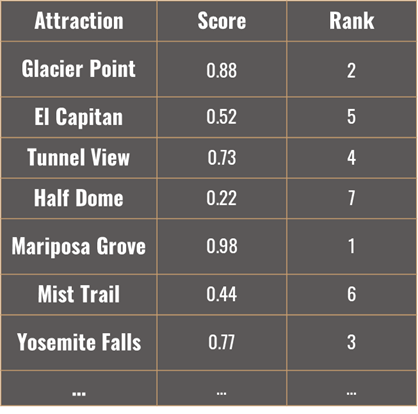
Using cosine similarity, the user input vector is compared against the averaged topic score vector of each attraction to find the highest scoring similarities. The top 3 scoring results (attraction names) are returned, ranked in descending order by their cosine scores.
After everything was said and done, I was left with a profound admiration for NLP. I was never too captivated by the idea of it when I began my foray into Data Science, but I now understood why many are enamored by it. Especially considering that state-of-the-art advances in NLP are simply groundbreaking in their awesomeness. An amazing example of this can be seen by looking at one of my other projects, titled ‘Creating “Unbiased News” Using Data Science’.
Waiiit! Can I get some recommendations?
Yes, of course! I deployed the recommendation system online using streamlit and you can click here to use it.
Comment below on how your trip goes! And if you would like to get in touch for any questions or discussions, I can be reached on Linkedin. The project code can be found on my Github repo.
Leveling Up Your Travel Agent Skills Through NLP (Part II) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")