



Let’s Talk Auto-Encoders
Last Updated on June 10, 2024 by Editorial Team
Author(s): Aminul Huq
Originally published on Towards AI.
In the field of deep learning, auto-encoders play a vital role. They have been used for various tasks, such as image reconstruction, noise removal, encoding, etc. Some people also use them in innovative ways to perform classification tasks.
In this blog, we will discuss the auto-encoder and how it can be used to achieve better performance for various tasks.
An auto-encoder model has two major networks which are encoder and decoder network. The encoder network takes the input and compresses it to a latent representation and the decoder network performs the opposite and reconstructs the input. Each network is basically the mirror opposite of each other. The latent representation is the finer feature of the input and has smaller dimensions than the input.
Generally, when we say auto-encoders it represents the network where it is entirely build using fully connected layers. Later this architecture was improved and convolutional auto-encoders were introduced where instead of fully connected layers convolutional layers were used entirely.
Do you know you can use convolutional layer as the last layer instead of fully connected layers for classification purposes ?
Researchers sometimes use both convolutional and fully connected layers in their auto-encoders, depending on the task and requirements. Also, keep in mind that auto-encoders can not generate new samples. They only can reconstruct the input data. A sample code for the auto-encoders is given below. It consists of both convolutional layers and fully connected layers.
class ConvAutoencoder(nn.Module):
def __init__(self):
super(ConvAutoencoder, self).__init__()
# Encoder
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1), # [batch, 16, 14, 14]
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1), # [batch, 32, 7, 7]
nn.ReLU()
)
# Flattening layer
self.flatten = nn.Flatten()
# Fully connected layer
self.fc = nn.Sequential(
nn.Linear(32 * 7 * 7, 128),
nn.ReLU(),
nn.Linear(128, 32 * 7 * 7),
nn.ReLU()
)
# Unflattening layer
self.unflatten = nn.Unflatten(1, (32, 7, 7))
# Decoder
self.decoder = nn.Sequential(
nn.ConvTranspose2d(32, 16, kernel_size=3, stride=2, padding=1, output_padding=1), # [batch, 16, 14, 14]
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=1, output_padding=1), # [batch, 1, 28, 28]
nn.Sigmoid()
)
def forward(self, x):
# Encoding
x = self.encoder(x)
x = self.flatten(x)
x = self.fc(x)
x = self.unflatten(x)
# Decoding
x = self.decoder(x)
return x
To train the model you simply need to use any distance mapping loss function which compares the input and the reconstruction and tries to reduce the gap among them. Popular distance metrics include L1 loss, MSE loss, RMSE loss etc. Using this approach you can perform reconstruction tasks quite easily.
People also use auto-encoders to perform feature extractions as well. Simply train your auto-encoder model for reconstruction task and then remove the decoder network. Now you have an encoder network which can take the input data and provide meaningful and fine features which can be used for various applications.
Another application of this model is to perform noise removal. Noise removal is really important as it can improve the model performance, remove unwanted artifacts from the data, etc. In order to train an auto-encoder model for this task, we need to make some modifications to the training operation. In the previous reconstruction task, we just used our input data and compared the output to the input for the loss function. For this case, we need to introduce some noise to the input data, let’s call it noisy data, which we pass to the auto-encoder model and get the output. For the loss function, we use the original input and the output data.
So compared to the reconstruction tasks, now we need to have access to both noisy and noise-free data which supervises the model to train to remove the noises. By doing so the model will learn remove the noises and provide noise-free output.
Performance Improvement Tricks/Tips:
Now let’s move on to discussing how we can improve the performance of auto-encoders.
1. Comparison in Latent Space: To train the model, we are comparing only the input and the reconstruction but we can pass the reconstructed input to the same encoder and extract a latent representation of the reconstructed input. Theoretically, if the reconstructed input and the original input are the same, then they should have the same latent representation using the same encoder model. We can add this as an extra constraint to train the model and guide it for achieving better outputs which can be similar to the input.
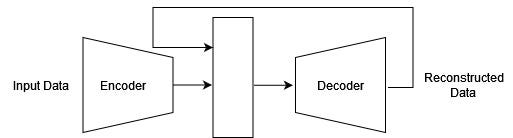
The loss function would now contain two different terms in which the first would be reducing the game between the input and the output and the second would be reducing the gap between the input latent representation and output latent representation.
2. Build Strong Encoder Network: If your encoder model can’t extract good features it is quite natural that your decoder can’t reconstruct the input properly. So, it is always a good idea to build a strong encoder model. Any traditional off the self deep neural network classification model(ResNet, DenseNet, EffiicientNet etc.) can be used for this purpose. You would only need to remove the final classification layer.
3. Batch Normalization: It has been shown that batch normalization layers can stabilize the model training and help attain better performance.
4. More Data: Finally, having more data always helps to achieve better performance for deep learning tasks.
I hope this helps to have a better understanding of the auto-encoder model, it’s applications and how to improve the performances.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



