



Langchain x OpenAI x Streamlit — Rap Song Generator🎙️
Last Updated on July 15, 2023 by Editorial Team
Author(s): Karan Kaul | カラン
Originally published on Towards AI.
Langchain x OpenAI x Streamlit — Rap Song GeneratorU+1F399️
Learn how to create a web app that integrates the Langchain framework with Streamlit & OpenAI’s GPT3 model.
Streamlit U+1F525
Streamlit is an open-source Python library that makes it easy to create and share beautiful, custom web apps for machine learning and data science. In just a few minutes, you can build and deploy powerful data apps.
We will be using it to create a basic UI for our app & then we will connect the UI components to serve the LLM response via Langchain & OpenAI client. U+1F64C
Langchain U+1F517
LangChain is a framework for developing applications powered by language models. It enables applications that are:
- Data-aware: connect a language model to other sources of data
- Agentic: allow a language model to interact with its environment
We will make use of the Langchain framework to build chains using individual prompts/tasks. An LLM will process each link in the chain U+1F517sequentially & this will allow us to run more complex queries through the model. The output from one prompt will become input for the next, and so on.
OpenAI U+007C GPT3.5 U+1F916
The OpenAI client from Langchain will allow us to harness the power of their state-of-the-art GPT models. We will make use of the ‘gpt-3.5-turbo’ model but you can use any model you want.
Here is a short description of the model we are going to use from the OpenAI website —
Most capable GPT-3.5 model and optimized for chat at 1/10th the cost of
text-davinci-003. Will be updated with our latest model iteration 2 weeks after it is released.4,096 max tokens
U+1F9D1U+1F4BBLet’s start with the code </>
Firstly, About the app —
We will create a Rap Song Generator. This will be our very own LLM-Powered web app.
Based on a given topic, it will generate an appropriate song title & then it will also generate verses for that title. Here is a demo of the app:
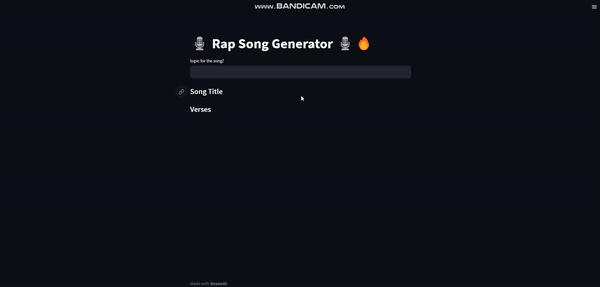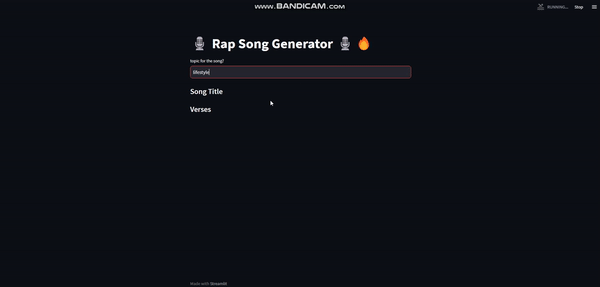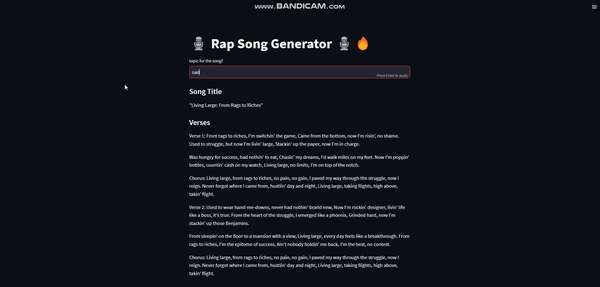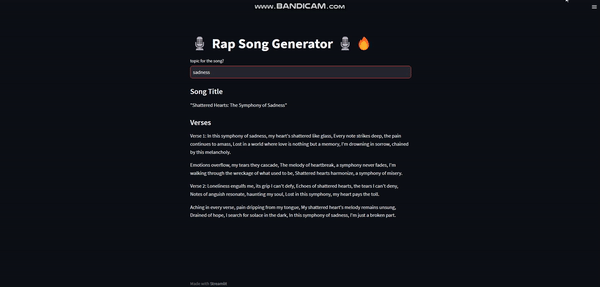
Exciting? Let’s start building!U+1F9D1U+1F3FBU+1F4BBU+1F4AAU+1F3FB
U+1F64BU+1F3FB The import statements & initial setup —
There are 3 main packages we need for this project. Install them & any other packages if needed.
After that, we will import the API KEY & set it as an environment variable. Also, since there are multiple GPT models we can pick for our app, I have defined the one I want in a variable. You can change it as per your needs.
#pip3 install streamlit
#pip3 install langchain
#pip3 install openai
import os
import streamlit as st
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SimpleSequentialChain, SequentialChain
from langchain.chat_models import ChatOpenAI
#import API key from config file
from config import OPEN_API
# environment variable & the model to use
model_id = 'gpt-3.5-turbo'
os.environ["OPENAI_API_KEY"] = OPEN_API
U+2712️ UI Elements (streamlit) –
Streamlit has a very user-friendly API that allows us to easily create a frontend for our ML/Data Science apps.
In the below code, we first created a title for our app & just below it we have an input box for the user where he/she will enter a topic for the song.
After that we have 2 more headings, one for what the title is going to be & the other for the verses. Each of these headings has its own output boxes, where the outputs will be attached once they are generated.
# main title & the input box
st.title("U+1F399️ Rap Song Generator U+1F399️U+1F525")
prompt = st.text_input("topic for the song?")
# second heading & the output area for song title
st.markdown("#### Song Title")
title_box = st.empty()
# third heading & the output area for verses
st.markdown("#### Verses")
verse_box = st.empty()
When input is provided, it will be stored in the ‘prompt’ variable. This variable will later be used to generate output.
U+1F4A5 Prompt Templates, Chains & LLM (langchain, OpenAI) –
Now we need to create templates for both title generation & verse- generation.
- In the first prompt, the input is the ‘topic’ that the user entered from the UI. This ‘topic’ will be used to format the template string. This template will be used to output the ‘title’ for the song.
- The second prompt will use the ‘title’ generated above as it’s input & will use that to format the second template string, which will generate verses based on this input ‘title’. The output of this template(chain) will be the ‘verses’.
Once we have 2 templates, we will create 2 chains for each of them. The first chain will be the title chain & it will make use of the title template.
Similarly, the second chain will be the verses chain & it will make use of the verse template.
The output we will get is going to be in a dictionary format, so for each chain, we can specify what to use as the key. This can be done by setting “output_key = something” on both chains.
# prompt template for generating title
title_template = PromptTemplate(
input_variables = ["topic"],
template = "generate a rap song title on the topic: {topic}"
)
# prompt template for generating verses
verse_template = PromptTemplate(
input_variables = ["title"],
template = "generate 2 rhyming verses for a rap song titled : {title}"
)
# building chains
title_chain = LLMChain(llm=llm, prompt=title_template, verbose=True, output_key="title")
verse_chain = LLMChain(llm=llm, prompt=verse_template, verbose=True, output_key="verse")
# combining chains
sequential_chain = SequentialChain(
chains=[title_chain, verse_chain],
input_variables=["topic"],
output_variables=["title", "verse"],
verbose=True,
)
At the end, we combine both chains & they will run sequentially when we start execution. The input variables in this combined chain will be [“topic”] & the output variables will be [“title”, “verse”] as defined when combining the chains.
U+1F4FA Outputting to the screen —
Once we have input from the user, we will run the combined chain that we just created. We will pass the prompt as the “topic” since that is the name we defined for our “input_variables” parameter.
The response will be a dictionary & we can extract the required text from that using keys that we also defined previously in the ‘output_variables’ & ‘output_keys’ variables.
# run chains if prompt is provided
if prompt:
response = sequential_chain({
"topic" : prompt
})
title = response["title"]
body = response["verse"]
# display each output in it's own output box
title_box.markdown(title)
verse_box.markdown(body)
To run the app, use the command —
streamlit run filename.py
That is all for this article. I hope it was worth your time & do follow me for more future updates!
U+1F5A4 Thanks for reading, check out these related posts —
The Early Adoption of Generative AI: Embracing Opportunities and Mitigating Risks
Let’s explore why companies are incorporating GAI into their businesses despite its imperfections, and how they are…
krnk97.medium.com
How to Create a YouTube Clone — YouTube API
How To Develop A YouTube Video Search WebApp Using HTML, CSS & JavaScript (jQuery) & the YouTube API.
enlear.academy
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

