



DAE Talking: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Last Updated on July 15, 2023 by Editorial Team
Author(s): Jack Saunders
Originally published on Towards AI.
Diffusion Models + Lots of Data = Practically Perfect Talking Head Generation
Today we will discuss a new paper and possibly the highest-quality audio-driven deepfake model I have come across. Coming from Microsoft Research, DAE-talker is a person-specific, full-head model that builds on the Diffusion Auto-Encoder (DAE). While the model is only shown on a single dataset, the results are very impressive.
https://www.youtube.com/embed/-p0IwiarEsg
The key to the success of this paper is twofold. First, they remove dependence on handcrafted features such as landmarks or 3DMM coefficients. Despite the fact that 3DMM’s, in particular, are very useful for person-specific models, they are still restrictive and are not as expressive as they could be. The authors are still able to benefit from the separation of a pose from other attributes, however, by using pose modeling. The second reason for the success of this model is the use of diffusion models. Diffusion models are the driving force behind models like Stable Diffusion, which have brought “Generative AI” into the mainstream.
The Diffusion Auto-Encoder
Diffusion models are well known for their ability to produce ultra-high-quality images with excellent diversity. These models use a latent vector of noise the same shape as the image and denoise them across multiple steps. However, one of the well-known limitations of diffusion models is that the latent vectors lack semantic meaning. In GANs or VAEs (the usual competitors to diffusion models) it is possible to perform edits in the latent space that leads to predictable changes in the output images. Diffusion models, on the other hand, do not possess this quality. Diffusion auto-encoders overcome this problem by instead using two latent vectors, a semantic code, and a standard, image-sized latent.
DAE is an autoencoding model, meaning that it consists of an encoder and decoder and is trained auto-regressively. The encoder of the DAE encodes an image into a semantic representation of that image. The decoder then takes the semantic latent vector and a noise image and runs the diffusion process to reconstruct the image.
The upshot is that this allows diffusion-level quality image generation with semantic control
In the case of DAE-Talker, a DAE model is trained on approximately 10 minutes of data of the target actor.
Controlling the Latent Space
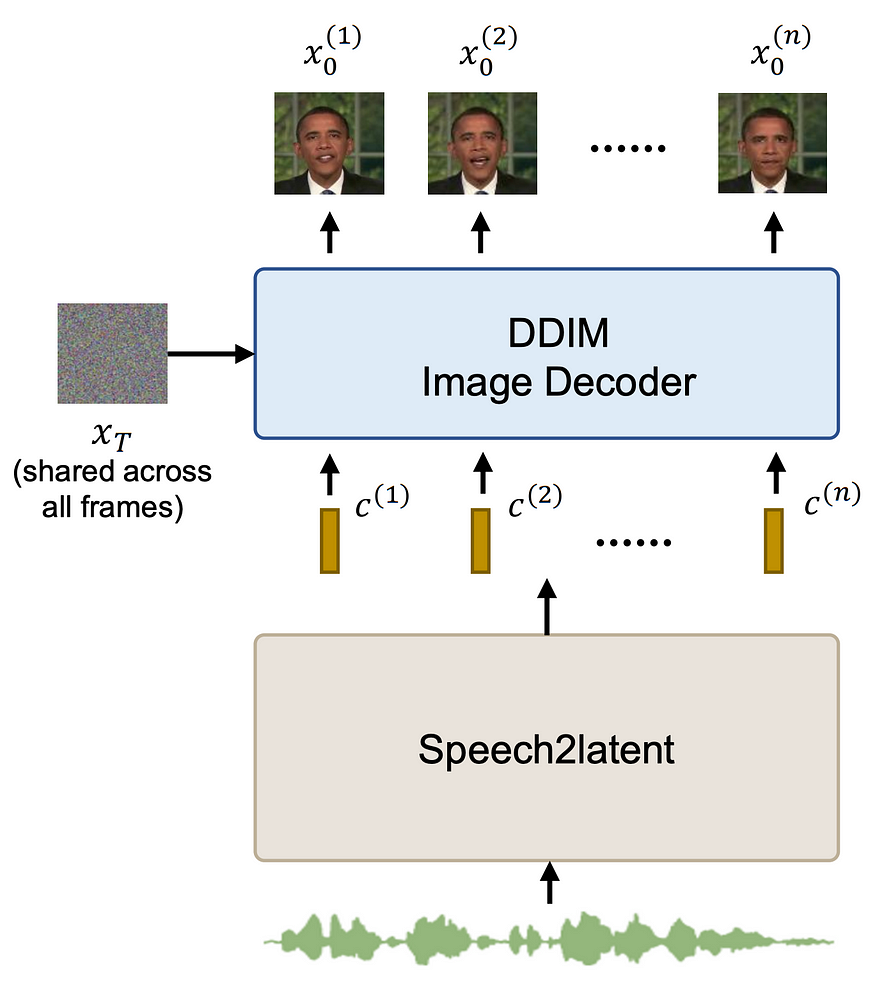
With the trained DAE permitting control over generated images through the use of semantic latent vectors, it becomes possible to generate video by manipulating the latent vectors only. This is the aim of the speech2latent component of this paper. Given audio as input, it outputs a sequence of latent vectors that are later decoded by the DAE.
An important point to note here is that the random noise image is fixed for every frame in the generated video. This cuts down on random noise that would create temporal inconsistencies in the final video.

The speech2latent component consists of several layers. The first of these is a frozen feature extractor from the Wav2Vec2 model. Wav2Vec2 is a transformer-based model that is used for speech recognition. Taking the feature extractor allows for the extraction of rich latent features of speech; this is done by several papers that look to generate signals from speech, for example, FaceFormer or Imitator. This set of features is processed further using convolution and conformer blocks (a mix of CNN and transformer layers). After this, a pose adaption layer is applied (we cover this in a second), before a final set of conformer layers and a linear projection onto the DAE latent space.
Pose Adaptor
The problem of speech-driven animation is a one-to-many problem. This is particularly true in the case of head pose, where the same audio can easily correspond to many different poses. To alleviate this issue, the authors propose the addition of a specific component in the speech2latent network that models pose. A pose predictor predicts pose from speech, while a pose projector adds the pose back into the intermediate features of the network. By adding a pose loss at this stage, the pose is better modeled. As the pose is projected into the features, either predicted poses or ground truth poses can be used.
Discussion
While this is not the first method in talking face generation to make use of diffusion models, it seems to have found a very successful way of doing so. The results are, in my opinion, the best quality of any existing model. Additionally, the ability to control or generate the pose makes the model particularly flexible.
With that being said, however, the model is not perfect. This method takes person-specificity to the extreme. The model is trained on 12 minutes of data from a single speaker, with no variation in background, lighting or camera. This is an order of magnitude more data than is used by most other methods. Perhaps for this reason, the experiments are restricted to one dataset only. Without seeing experiments on anyone except Obama, it is hard to verify that the model will work for most people. Furthermore, this is not an easy model to train. The DAE component alone trained for three full days on 8 V100 GPUS, with the speech2latent taking more time still. According to current GCP prices, this could cost upwards of $1500 per training! Inference will likely take a long time, too, as 100 denoising steps are required per frame.
Conclusion
Overall this is an extremely promising method showing the best results currently available, if you don’t mind the massive costs involved with training. If someone can work out how to develop a person-generic version of this model (and can afford to do so) I think we may be getting close to solving the problem of talking face generation entirely.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

