



Introduction
Last Updated on July 25, 2023 by Editorial Team
Author(s): Manish Nayak
Originally published on Towards AI.
Machine Learning
An Intuitive Introduction of Word2Vec by Building a Word2Vec From Scratch
Understanding Word2Vec, and it’s advantages
In this article, I will try to explain Word2Vec vector representation, an unsupervised model that learns word embedding from raw text and I will also try to provide a comparison between the classical approach One-hot encoding and Word2Vec.
One-Hot-Encoded Vector Representation
The classical approach of solving text-related problems is one-hot encode the word. This approach has multiple drawbacks.
- If the dataset has ten thousands of unique words(vocabulary) then one-hot-encoded vector representation will have ten thousands of dimensions.
- In a one-hot-encoded vector representation, the size of the vector will be the size of the vocabulary. most of the words in the vocabulary will not be present in each document. So one-hot-encoded vector representation is a vector with mostly empty (zeros).
- It is inefficient in computation.
- Similar words will not have similar vectors in a one-hot-encoded vector representation.
Let’s consider the following two sentences.
I like watching a movie.
I enjoy watching a movie.
In one-hot encode vector representation of the words looks as follows
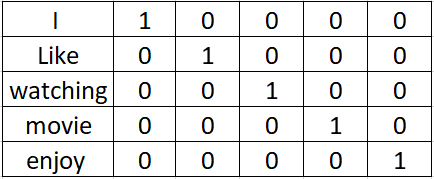
Intuitively we know that enjoy and like are kind of similar words. The Euclidean distance between movie and enjoy is the same as the Euclidean distance between enjoy and like. This is a major drawback.
Word2vec Vector Representation
Word2Vec is an approach that helps us to achieve similar vectors for similar words. Words that are related to each other are mapped to points that are closer to each other in a high dimensional space. Word2Vec approach has the following advantage.
- Word2Vec builds on the fact that words that share similar contexts also share semantic meanings.
- Word2vec model predicts a word by using its neighbors, by learning dense vectors called embedding.
- Word2vec is also computationally efficient.
- Word2vec is an unsupervised model that learns word embedding from raw text.
- Word2vec is available in two flavors: the CBOW model and the skip-gram model.
- Skip-gram: When surrounding words(also known as context words) are predicted using the input(target) word.
- CBOW(Continuous Bag Of Words): When the target word is predicted using the surrounding words(context words).
Word2vec is a three-layer neural network, In which the first is the input layer and the last layers are the output layer. The middle layer builds a latent representation so the input words transformed into the output vector representation.
In the Word2vec vector representation of words, we can find interesting mathematical relationships between word vectors.
king — man = queen — woman
In our previous example of two sentences.
If we follow the CBOW approach and take the surrounding(context) words as input and try to predict the target word then the output will be as follow.

A vectored form of the input and output looks like below.

In the neural network for our current example, there will be three neurons in the hidden layer and output will have five neurons with softmax function so that it will give the probability of words.

Accompanied jupyter notebook for this post can be found on Github.
Conclusion
The drawback of the classical approach is, it does not consider the order in which the words occur in the sentence and context is lost. it assumes that words in the document are independent of one another. Vector representation in this classical approach leads to data sparsity. This drawback can be overcome by Word2vec vector representation.
I hope this article helped you to get an understanding of Word2vec and why we prefer Word2vec over one-hot-encoding. It will at least provides a good explanation and a high-level comparison between one-hot-encoding and Word2vec vector representation.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

