



Introduction
Last Updated on July 24, 2023 by Editorial Team
Author(s): Odemakinde Elisha
Originally published on Towards AI.
Data Analytics, Machine Learning
Utilization of Dask ML Framework for Fraud Detection —End-to-end Data Analytics
Fraudulent activities have become a rampant activity that has aroused a lot of curiosity in the financial sector. This has posed a lot of issues in helping the sector efficiently manage their customers. In this tutorial, we will be using the Dask machine learning framework to intuitively detect fraudulent transactions in the financial industry. The outcome of the model is for us to efficiently deploy in any type of bank to reduce fraudulent means by alerting the owners of the account and the bank team. The link to this code is provided on Github.
First and foremost, since this is a machine learning problem, why do we want to use dask since we have notable frameworks like pandas, bumpy, and scikit-learn to get the job done? I would love to state that dask has proven to be a framework in scaling pandas, bumpy, and scikit-learn workflow efficiently with minimal code. With dask, you get to perform all sorts of numpy, pandas, and scikit-learn operations.
Dask has proven to be a framework in scaling pandas, numpy and scikit-learn workflow efficiently with minimal code
In this tutorial, we want to build a model from a set of information provided by Bank A from their customer database; in identifying fraudulent transactions from non-fraudulent transactions. This bank has data of customers whose accounts got involved in fraudulent acts and those whose accounts do not have fraudulent history. We will be leveraging this information in predicting fraudulent accounts based on certain features.
Alright, to get started, I will be using a dataset available on kaggle here. We will be going through the following procedures for solving this problem:
- Understanding our data
- Data analysis/preprocessing with dask pandas and numpy framework.
- Data visualization with seaborn and matplotlib.
- Feature engineering
- Predictive Modelling using the Dask ML framework.
With dask, you get to perform all sorts of numpy, pandas and scikit-learn operations.
Data Analysis
In this section, we will get to understand our data and perform basic data preprocessing and cleaning using dask while we make decisions on which feature is relevant to modeling the problem. First and foremost, let’s import all libraries and load the dataset by doing this:
You can read in data into a dataframe in dask by using the read_csv method and then pass in the csv file. You can go ahead to see the top 5 entries in the data by using the .head attribute of the dataframe. The next for us is to know the features we are working with. In dask, to do this, you can run the dataframe and the column attribute. This is illustrated in the code below.
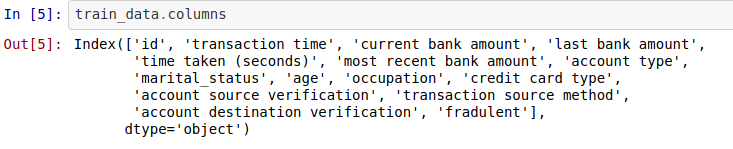
With this, we can say we have an idea of what our data is all about. So our data contains information on transaction time, the current bank amount, last bank amount, time is taken to process a transaction, account type, marital status, and other information provided from each user of the bank. More importantly, we have the feature we are trying to predict or understand with respect to other features which is fraudulent; that is our target feature. We still need to know more about our data so that we can know how to analyze, select the best feature, and transform for perfect modeling. The next thing you may want to do is to have a look at the descriptive analysis of the numerical entries in our data. Dask helps us to do this efficiently by running the code below, and we will have the corresponding output.
The describe() method of a dask dataframe gives us a statistical insight into the numerical features of our data by telling us the number of valid entries in each feature (count), the mean, median, mode, minimum value, maximum value, standard deviation, lower percentile, upper percentile, and others for each corresponding entry. This actually has unveiled some things about our data, but let’s take note, this is only for the numerical info in our data. What about the non-numerical info’s, we still have to transform them into numerics so as to prepare them for the algorithm that will learn from them. First, let’s have a peek into our data by knowing, which of them is numerical and which is not. The code below helps us to do that in dask.
From the code above, we are able to see that we have 3 features that are boolean (account source verification, transaction source method, and account destination verification), 6 numerical data and 6 text data (strings). Now, that we have an idea of the information we are trying to model, let’s now dive into this step by step by having an insightful look into each feature using dask. Let’s begin with marital status. The code below gives us an idea of what the content marital status entails.
Marital Status
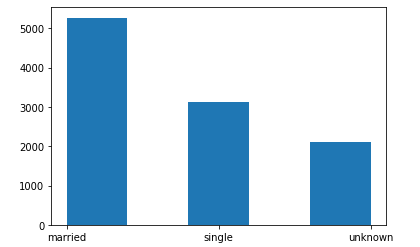
The marital status feature tells us vividly that the customers on this database are mostly married, while some are single and others didn’t disclose their marital status. Could this be a unique feature in determining fraudulent acts? It may, and it may not. Below is a histogram illustrating the frequency of each unique entry present in marital status.
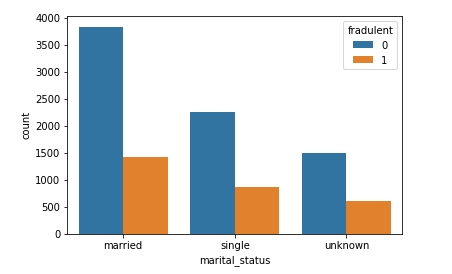
From the above illustration, a lot of married customers don’t have fraudulent histories in their account, this also corresponds to the same ratio for the single and the unknown. From the visual above, the ratio of the fraudulent accounts to the non-fraudulent account is almost the same for each (married, single, and unknown). We can say, there is a directly proportional relationship between marital status and our target, fraudulent. We will keep this because it’s a valid entry to our model.
Let’s move on to the next set of features which are:
- Id
- current bank amount
- last bank amount, and
- most recent bank amount.
We are dropping them because we want to assume that they can’t be a unique determinant in determining fraudulent transactions. The code below (in dask), helps us to execute this.
Now we are left with less information yet to be processed. We can do the same thing done between marital status and fraudulent for other features with respect to fraudulent and we can have the following visuals.
Let’s take some other features, analyze, and transform. To begin, let’s look into the transaction time. Since this has to do with time, we will need to use the time, date library in python to process this. The code below helps us to do this efficiently:
What was done above was for us to apply basic string operation in splitting the time into the year, month, day, hour, minute, and seconds for every entry present in that feature (transaction time). Having done this, we transformed them into new features for our dataframe and then dropped the original transaction time column. The next is for us to separate the data into X and y, such that X contains all features we want to work with and y is the target feature. To do this we have:
Feature Engineering
Now that we have some ideas regarding the data, let’s go-ahead to do some feature engineering. There are two main ways of generating more features in your data:
- Label Encoder — Here, feature parameters or entries are encoded in the order of priorities.
- One-hot Encoder — Here, feature parameters or entries are encoded by giving all entry equal priorities. More so, this sort of encoder tends to increase the dimension of the data by the number of valid entries in a particular feature.
- Polynomials — A polymeric means of data expansion for input features present in the data.
But for the sake of this tutorial, we will focus on label encoding and one-hot. Dask does have support for label encoding and one-hot encoding. To get started, here are some of the features we have looked into and we want to encode them from being an object into numerics. This is because our algorithm works with numbers, not strings, so they need to be encoded, if relevant to the data. We are encoding the following features using label encoding:
- Account source verification.
- Account Destination verification.
- Transaction source method.
To encode them using dask here is how to do it, using the code below:
Some features are less important in determining fraudulent transactions, like time taken for a transaction to get processed, age, and Id. So to drop them from our data we do the following:
Now we are left with just 6 features in building a model that will efficiently determine if a transaction is fraudulent or not. To confirm this, you can use the .head attribute of the dataframe to view. Doing this below we have:
Since all our features are now numeric, we can go ahead to standardize and reduce the variance of each feature using any of the following technique:
- Standard Scaler — A means of rescaling your data based on standard deviation.
- Normalizer — A means of normalizing all input to a particular feature to 1
- Min-max scaler — A means of reducing the variance in various features by rescaling all corresponding entries for each column by the corresponding maximum number.
These techniques are scaling techniques used for data science and ML tasks before modeling. Dask does have support for this, to import them do the following:
Having done the scaling and data standardization we can go ahead to model. Dask does have support in helping us model our data, the above code shows us how to import necessary libraries needed for efficient modeling of our data. This includes the train_test_split, to split our data into train and test data for modeling and testing the model performance. More so, you can import the logistic regression algorithm as shown above using dask (this will be the algorithm to model our data). Finally, we can go ahead to import the metrics using dask, that is, accuracy score and log_loss which are available metrics for classification in desk. First, let’s proceed to split our train data into two parts, one for modeling and the other for testing, to do this, we have the following:
Dask does have support in helping us model our data,
Since we have been able to split into the modeling data and the testing data, we can go ahead to feed the modeling data into our algorithm to learn using dask and finally to evaluate the model while training. The following code below shows us how to do that:
While training, the model was approximately 72% accurate, this shows that this model learned. Let’s go-ahead to make predictions on the test data and evaluate its performance on the data it hasn’t seen before. The code below helps us to do this:
- How to perform data preprocessing and cleaning with dask.
Dask gives us an end-to-end flexibility of analyzing and modelling our data.
How to perform data preprocessing and cleaning with dask.
- Data modeling and prediction with dask.
I hope you have learned a lot, if you do love this tutorial, do share it with friends. Thanks.
Links and References
- https://github.com/elishatofunmi/Medium-Intelligence/tree/master/Introduction%20to%20dask (notebook to this work).
- https://dask.org
- https://colab.research.google.com/drive/1uvRpOp9L1Hge2GNniJ5fJ0H7VL0LQmbZ?usp=sharing (colaboratory notebook).
- https://docs.dask.org/en/latest/ (dask documentation).
- https://github.com/dask/dask-tutorial (dask tutorial).
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

