


How To Use ChatGPT API for Direct Interaction From Colab or Databricks
Last Updated on April 11, 2023 by Editorial Team
Author(s): Jonas Dieckmann
Originally published on Towards AI.
Have you wondered how you can use OpenAI’s API to interact directly with GPT algorithms? It’s easy, free, and also more powerful than the “classic” web interface at www.openai.com. In the following tutorial, I will guide you through some simple steps that will allow you to use GPT for text generation, image creation, or debugging your code!
As the use of ChatGPT and other natural language processing (NLP) solutions increases, so does the number of tools and platforms that allow users to interact with these cutting-edge features. One of the most popular options is the OpenAI web interface, which has received widespread acclaim for its ability to handle complex NLP tasks.
Today, however, we will explore an alternative: the ChatGPT API. This article is divided into three main sections:
#1 Set up your OpenAI account & create an API key
#2 Establish the general connection from Google Colab
#3 Try different requests: text generation, image creation & bug fixing
Please note: Although this tutorial was done in Google Colab (free), you may want to try other environments. For example, all the code was also applied in Databricks.
#1 Set up your OpenAI account & create an API key
To interact with the GPT algorithms, you need to sign up for an OpenAI account (free of charge): https://platform.openai.com/signup/
Once you have registered and signed up, you will need to create an API key that will allow you to send requests to OpenAI from third-party services such as Google Colab or Databricks. Navigate to the “View API Key” section via the user menu, or use the following link: https://platform.openai.com/account/api-keys
In this section, simply click on “Create new secret key” and save the created key somewhere on your computer (you will need it soon!).
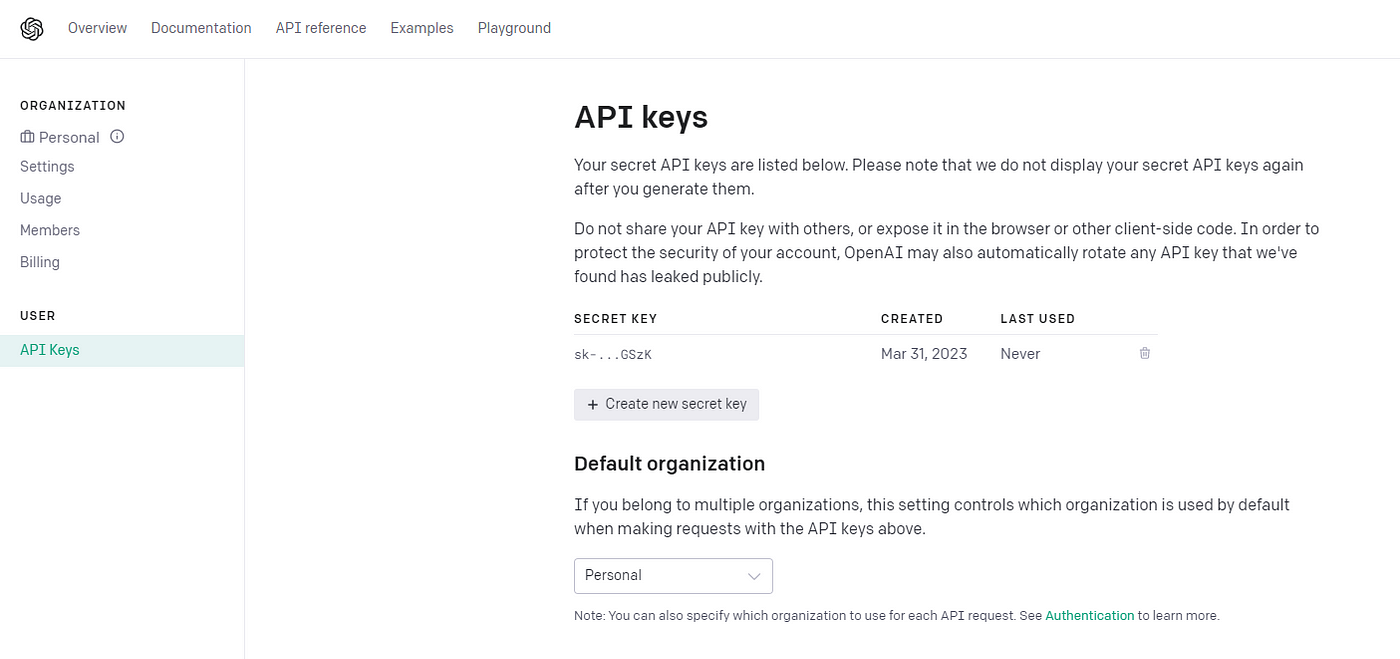
Please note that ChatGPT API is offering free trial usage (as of today) with limited requests and tokens per minute. See the rate limits below [1]:
- Free trial users: 20 RPM 40000 TPM
- Pay-as-you-go users (first 48 hours): 60 RPM 60000 TPM
- Pay-as-you-go users (after 48 hours): 3500 RPM 90000 TPM
(RPM = requests per minute; TPM = tokens per minute)
#2 Establish the general connection from Colab
The easiest and most straightforward way to test the API is to use Google Colaboratory (“Colab”), which is something like “a free Jupyter notebook environment that requires no setup and runs entirely in the cloud.” Although there are many more professional environments you may want to explore (e.g. Databricks), I think Colab is not a bad service to take your first steps with the ChatGPT API.
To set up a basic environment for ChatGPT within Colab you can follow the next few steps:
- Open https://colab.research.google.com/ and register for a free account
- Create a new notebook within Colab
- Install & use the openai package:
pip install openai
To execute a simple chat request to the API using the GPT 3.5 turbo model (see other available models in their documentation linked at the end of this article), similar to what you know from the OpenAI web interface, you can simply execute the following lines of code in your notebook:
import os
import openai
openai.api_key = "please-paste-your-API-key-here"
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hello ChatGPT, does this work?"}
]
)
As soon as you execute the command in Colab, you receive a JSON object as a response that contains the expected answer! (That was easy, wasn’t it?)
Hello! As an AI language model, I don’t have the context of what \”this\” refers to. Could you please specify what you are referring to so I can assist you better?
<OpenAIObject chat.completion id=chatcmpl-70ErnAfGGwU7GhMXzCcLGyUvr4hA2 at 0x7f097f0a5f40> JSON: {
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "Hello! As an AI language model, I don't have the context of what \"this\" refers to. Could you please specify what you are referring to so I can assist you better?",
"role": "assistant"
}
}
],
"created": 1680291503,
"id": "chatcmpl-70ErnAfGGwU7GhMXzCcLGyUvr4hA2",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 38,
"prompt_tokens": 17,
"total_tokens": 55
}
}
In addition, the JSON object provides information about the number of tokens used and the reason for the end of the request. If you only want to print the text response, you can access this element by slightly modifying your code:
import os
import openai
openai.api_key = "please-paste-your-API-key-here"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hello ChatGPT, does this work?"}
]
)
print(response.choices[0].message.content)
#3 Try different requests: text generation, image creation & bug fixing
If you’re as excited as I was when I found this out, you could start sending lots of different requests to the API. A useful way to modularise your code is to create some helpful functions that you want to call for different purposes. Let me give you some ideas.
Function to chat with ChatGPT
The following code simply summarises the work done so far in a callable function that allows you to make any request to GPT and get only the text response as the result.
import os
import openai
openai.api_key = "please-paste-your-API-key-here"
def chatWithGPT(prompt):
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
]
)
return print(completion.choices[0].message.content)
Do you think it makes sense to learn python? Let’s ask GPT!
chatWithGPT("is it a good idea to start learning python?")
As an AI language model, I cannot provide personal opinions, but I can say that Python is a popular and widely used programming language that is highly favored by beginners and experienced developers alike. It has a vast community support, a large number of libraries, and a simple syntax that makes it easy to grasp for those new to programming. It is useful for various applications, like data analysis, web development, machine learning, and more. Therefore, it could be a good idea to start learning Python if you want to pursue a career in programming or want to add another skill to your resume.
Function to fix bugs in your code
Another use case for ChatGPT is to get ideas for fixing your code. Imagine your Python command returns an error and you want to get advice on what to do without using Google or StackOverflow:
import os
import openai
openai.api_key = "please-paste-your-API-key-here"
def fixMyCode(code):
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "find error in my python script below and fix it: " + code}
]
)
return print(completion.choices[0].message.content)
See my python code has thrown an error, and I don’t know why…
fixMyCode("""
def some_function():
print("I'm going to sleep")
time.sleep(10)
print("I'm awake again")
some_function()
""")
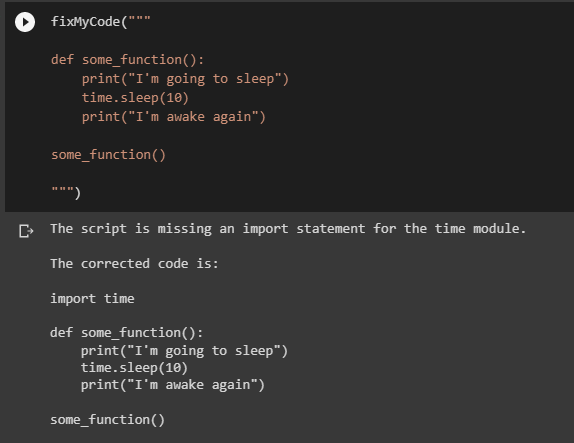
No surprise, but ChatGPT immediately found out that I had forgotten to import the module before I used it. This can be very helpful in everyday life, especially when you can call for help directly from the programming environment.
Function to create images
The last use case I would like to present here is the creation of images. The request itself returns a hyperlink containing the picture. Using the IPhython library, you can display the picture directly in your notebook.
import IPython
import os
import openai
openai.api_key = "please-paste-your-API-key-here"
def createImageWithGPT(prompt):
completion = openai.Image.create(
prompt=prompt,
n=1,
size="512x512"
)
return IPython.display.HTML("<img src =" + completion.data[0].url + ">")
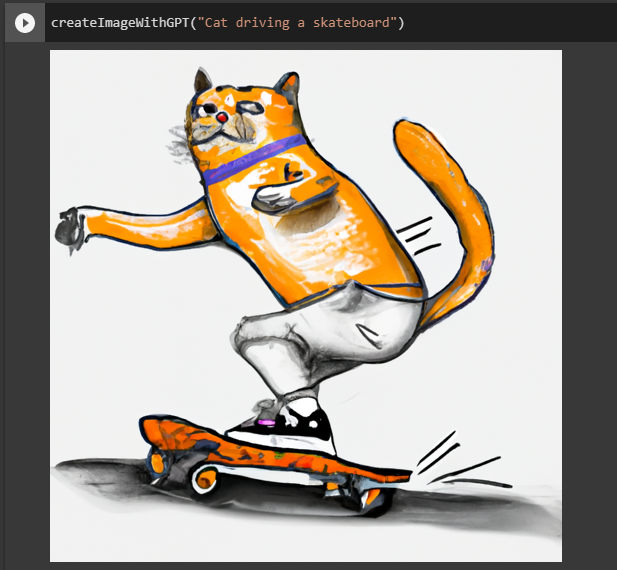
Let’s be creative and ask for a cat driving a skateboard!
createImageWithGPT("Cat driving a skateboard")
Summary
With ChatGPT API, businesses and individuals can easily and affordably incorporate chatbots into their workflow without the technical knowledge or extensive resources typically required. The API can also be used to create virtual assistants, personal tutors, and more. I recommend the documentation made available by OpenAI for their API: https://platform.openai.com/docs/api-reference.
In summary, it is easy to use the API in your programming environment. Not only might this be helpful for direct debugging of your code, but it has also shown more stable response rates compared to OpenAI’s (sometimes unavailable) web interface. With the ability to understand natural language and get smarter over time, ChatGPT has the potential to revolutionize the way businesses interact with their customers and streamline their workflows. Try it yourself and experience the future of chatbots!
Jonas Dieckmann – Medium
Read writing from Jonas Dieckmann on Medium. analytics manager & product owner @ philips | passionate and writing about…
medium.com
I hope you find it useful. Let me know your thoughts! And feel free to connect on LinkedIn https://www.linkedin.com/in/jonas-dieckmann/ and/or to follow me here on medium.
See also some of my other articles:
How to get started with TensorFlow using Keras API and Google Colab
Step-by-step tutorial to analyze human activity with neuronal networks
towardsdatascience.com
Introduction to ICA: Independent Component Analysis
Have you ever found yourself in a situation where you were trying to analyze a complex and highly correlated data set…
towardsdatascience.com
References
[1]: https://help.openai.com/en/articles/7039783-chatgpt-api-faq
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

