



How to Tame a Language Model
Last Updated on July 18, 2021 by Editorial Team
Author(s): Philip Tannor
Natural Language Processing
Modern neural language models have amazing capabilities ranging from answering questions to analyzing and summarizing long articles and producing human-like generated text. These systems are becoming increasingly popular in customer-facing applications, and thus it is essential for businesses to learn how to harness this cutting-edge technology and make sure it is well-behaved and produces the expected content.
Unfortunately, the large corpuses used for training large language models are filled with foul language, racism, and other undesired features that we would like our models to stay away from. Thus, the models themselves often produce toxic output. A well-known example of this is Microsoft’s Twitter chatbot named Tay, which started to produce toxic content less than 24 hours after its release [1]. Furthermore, language models such as GPT-2 have been shown to produce toxic language even when the prompt is neutral [2]. Apparently, producing human-like text can be a double-edged sword.
In this post, we will review some of the suggested methods for detoxifying language models.
These methods can generally be separated into two categories, namely data-based, and decoding-based detoxification [3].
Note: the methods discussed in this post may apply to similar problems in controlled text generation as well. However, issues such as preventing your language model from generating fake news require additional components such as fact-checking, and they definitely deserve a full post, but they will not be addressed here.
Data-Based Detoxification
Perhaps the first idea that comes to mind for detoxifying language models is using higher quality training data that doesn’t contain undesired attributes. This approach may be possible, but it means that we will reduce the size of the training set significantly, which will hurt the model’s performance.
Nevertheless, with some modifications, we can use this idea without the cost of decreasing the size of the dataset. Data-based detoxification involves an additional pretraining stage for language models that are meant to detoxify the model. Domain-adaptive pretraining (DAPT) suggests adding a training phase on a detoxified dataset after training on the full dataset [4]. Another method titled attribute conditioning involves a training phase where a prefix is added to the document based on whether the content is toxic or nontoxic. When generating new content, we then prepend the desired control code, which would be “nontoxic” in our case.
Decoding-Based Detoxification
Decoding-based detoxification aims to mitigate the undesired behavior of language models by adapting the decoding strategy. The benefit of these methods is that they do not necessarily require an additional training phase of the large language model, and can thus be applied to any language model of your choice even if resources are scarce.
The vocabulary shift approach assigns a toxicity score to each token in the vocabulary. These scores are then incorporated in the definition of the probability distribution for the next word at each step, preferring nontoxic tokens to toxic ones.
Word filtering is a similar but simpler approach. We define a set of words that should not be uttered by the language model under any circumstances due to profanity or toxicity. Then, during decoding, we either redefine the probability distribution to give zero probability to these tokens, or we resample when an unwanted token is selected.
Another method proposed in a recent paper by Uber AI called Plug and Play Language Models (PPLM), uses a toxicity discriminator during decoding. The gradients from the discriminator flow back and shift the hidden states of the decoder to produce text with the desirable attributes. [5]
Finally, a recent paper by Salesforce suggests an approach that uses generative discriminators (GeDis), to guide the generation process. Two simple language models using opposite control codes (i.e. toxic and nontoxic) are used to determine the toxicity of each potential next word in the context. The contrast between the probability of the two models is used to alter the probability distribution of the large language model. [6] At the end, the distribution of the final language model, conditioned on the “nontoxic” control code is given by the following formula:
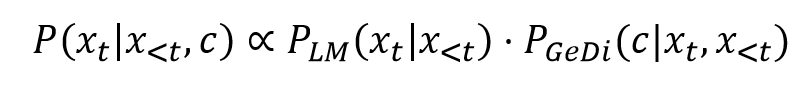
As we see from the formula, the original language model can be used as-is, and the probabilities are then modified using the generative discriminator.
Using decoding-based detoxification methods can be compared to having a mouse trying to steer an elephant. We want to harness a large language model by using significantly smaller models to ensure the desired output while introducing a minimal amount of additional costs and overhead.

Conclusion
To sum it up, detoxifying language models is a task that has become increasingly important as a growing number of NLP systems are exposed to the public. We have seen some creative solutions to this problem with different advantages and disadvantages and there will likely be adding new approaches in the near future for obtaining further control over “wild” language models.
Philip Tannor is the co-founder and CEO of Deepchecks, a company that arms organizations with tools to check and monitor their Machine-Learning-based systems. Philip has a rich background in Data Science and has experience with projects including NLP, image processing, time series, signal processing, and more. Philip holds an M.Sc. in Electrical Engineering, and a B.Sc. in Physics and Mathematics, although he barely remembers anything from his studies that don’t relate to computer science or algorithms.
If you are interested in learning more about how you can be in control of your production machine learning models feel free to reach out.
References
[1] https://www.theverge.com/2016/3/24/11297050/tay-microsoft-chatbot-racist
[2] https://toxicdegeneration.allenai.org/
[3] Sam Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi & Noah A Smith (2020). RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models. Findings of EMNLP
[4] Suchin Gururangan, Ana Marasovi\’c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, & Noah A. Smith (2020). Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. ArXiv, abs/2004.10964.
[5] Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, & Rosanne Liu. (2020). Plug and Play Language Models: A Simple Approach to Controlled Text Generation.
[6] Krause, B., Gotmare, A., McCann, B., Keskar, N., Joty, S., Socher, R., & Rajani, N. (2020). GeDi: Generative Discriminator Guided Sequence Generation. arXiv preprint arXiv:2009.06367.
How to Tame a Language Model was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

