


How to Quickly Set up a Benchmark for Deep Learning Models With Kedro?
Author(s): Anh Khoa NGO HO
Originally published on Towards AI.
As a data scientist, I used to struggle with experiments involving the training and fine-tuning of large deep-learning models. For each experiment, I had to carefully document its hyperparameters (usually embedded in the model’s name, e.g., model_epochs_50_batch_100), the training dataset used, and the model's performance. Managing and reproducing experiments became highly complex during this time. Then, I discovered Kedro, which resolved all my issues. If you are conducting experiments in machine learning, I believe this article will prove immensely beneficial.
What do we need to know about Kedro?
Kedro, an open-source toolbox, provides an efficient template for conducting experiments in machine learning. It facilitates the creation of various data pipelines, including tasks such as data transformation, model training, and the storage of all pipeline outputs. Kedro revolves around three crucial concepts:
- Data catalog: the data catalog acts as a registry for all sources that the project can use to manage loading and saving data. It includes input datasets, processed datasets, and models. These sources are stored as dictionaries, referred to names (strings), in Yaml files. E.g., in the code below, when we call
input_dataset, Kedro returns the csv file infilepath.
input_dataset:
type: pandas.CSVDataSet
filepath: data/01_raw/dataset.csv
processed_dataset:
type: pandas.CSVDataSet
filepath: data/02_intermediate/dataset.csv
- Node: a node serves as a wrapper for a pure Python function that defines the inputs and outputs of that function. It represents a small step in the pipeline. For example, in data processing, nodes can be defined for tasks like concatenating dataframes or creating new features. Inputs and outputs are sourced from the data catalog.
from kedro.pipeline import node
def process_data(df1, df2):
return df1 + df2
node_process_data = node(func=process_data, inputs=[”input_data”, ”input_data”], outputs=“processed_data”
- Pipeline: a pipeline consists of a list of nodes where inputs and outputs are interconnected.
from kedro.pipeline import pipeline
pipeline_process_data = pipeline([node_process_data])
Kedro also boasts several valuable plugins: kedro-viz for visualizing data pipelines, kedro-mlflow for facilitating MLflow integration, and kedro-sagemaker for running a Kedro pipeline with Amazon SageMaker, etc., (read more).
Kedro-viz
This plugin serves as an interactive development tool for visualizing pipelines built with Kedro. It allows the display of dataframes and charts generated through the pipeline, facilitating the comparison of different experiment runs with a single click. In this article, we’ll explore how to track hyperparameters and performance scores of deep learning models using kedro-viz.
Now, let’s delve into creating a benchmark in three steps.
Step 1: set up our experiment
The initial step involves installing the required library, Kedro, along with additional dependencies like PyTorch (build a deep learning model) and kedro-viz, using pip install. For detailed instructions, refer to installing kedro, installing kedro-viz. It's important to note that there are variations between Kedro versions, so we specifically set the version to 0.19.1. Additionally, it is advisable to create a Python environment (consider using conda with the command conda create --name environment_name).
pip install kedro==0.19.1
pip install kedro-viz
pip3 install torch
Creating a project template with necessary files and folders is achieved with the following command (read more):
kedro new
After providing the project name and configuring options, the resulting folder structure includes:
conf: This folder keeps our configuration settings for different stages of our data pipeline (e.g., development, testing, and production stage). By default, Kedro has abaseand alocalenvironment. Read more.
–basecontains the default settings that are used across our pipelines:(a)catalog.yml: this is a default yaml file to describe our data catalog. If we want to create more catalog files, their names must have the formatcatalog_*.yml. (b)parameters.yml: this is a default yaml file to describe our default parameters. A general format for naming these files isparameters_*.yml.
–localis used for configuration that is either user-specific (e.g. IDE configuration) or protected (e.g. security keys). These local settings can override the settings in the folderbase.data: it contains all inputs/outputs of our pipeline (see Data Catalog). Kedro proposes a list of sub-folders to store these inputs/outputs e.g., raw data in01_raw, pre-processed data in02_intermediate, trained models in06_models, predicted data in07_model_output, performance scores and figures in08_reporting.
–01_raw
–02_intermediate
–03_primary
–04_feature
–05_model_input
–06_models
–07_model_output
–08_reportingdocs: this is for documentation. You can use Sphinx to quickly build documentation.logs: we use this folder to keep all logs.notebooks: we put our jupyter notebooks here.src: houses code, including functions, nodes, and pipelines.
To initiate an empty pipeline, utilize the command kedro pipeline create pipeline_name. Subsequently, a folder named pipeline_name is generated, and all created pipeline folders are stored in the directory src/project_name/pipelines. Within a pipeline folder pipeline_name, two essential files are present:
nodes.py: contains node functions contributing to data processing.pipeline.py: used for constructing the pipeline.
Furthermore, a configuration settings file, parameters_<pipeline_name>.yml, is established in conf/base/ to store parameters specific to the created pipeline. In the subsequent step, we will customize these files to define our pipeline.
Step 2: define our data pipeline
Utilizing a small dataset (sklearn.datasets.load_digits), we define a simple pipeline that involves getting data and storing it locally.
- In
nodes.py, we define a function to get the dataset.
import pandas as pd
from sklearn.datasets import load_digits
def get_dataset() -> pd.DataFrame:
data = load_digits()
df_data = pd.DataFrame(data['data'], columns=data['feature_names'])
df_data['target'] = data['target']
return df_data
- In the file
src/project_name/pipelines/pipeline_name/pipeline.py, we generate a list of nodes namedpipeline_example. Each node comprisesfunc(the function's name, e.g.,get_dataset),inputs, andoutputs. The nature ofinputsandoutputscan be a string, a list of strings, orNone, depending on the inputs/outputs of the corresponding function. It's important to note that a string denotes a data name that we can later utilize in the subsequent node of our pipeline.
from kedro.pipeline import Pipeline, pipeline, node
from .nodes import get_dataset
def create_pipeline(**kwargs) -> Pipeline:
pipeline_example = [node(
func=get_dataset,
inputs=None,
outputs="raw_data"
)
]
return pipeline(pipeline_example)
- We define data names in
conf/base/catalog.ymland specify their storage details (filepath). There are many options for storing data: local file systems, network file systems, cloud object stores, and Hadoop. Read more.
raw_data:
type: pandas.CSVDataset
filepath: data/01_raw/raw_data.csv
Step 3: define our model
Now, we create our neural network model with PyTorch. We build a simple neural network with 2 feed-forward layers. Recall that the dataset Digits has 64 features and 10 classes. Therefore, the input dimension of our first layer is 64, and the output dimension of our last layer is 10. We add a softmax layer for returning probabilities.
import torch
import torch.nn as nn
import torch.nn.functional as F
class NeuralNetwork(nn.Module):
def __init__(self, dimension):
super(NeuralNetwork, self).__init__()
self.linear_1 = nn.Linear(64, dimension)
self.linear_2 = nn.Linear(32, dimension)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = F.relu(self.linear_1(x))
x = F.relu(self.linear_2(x))
x_prob = self.softmax(x)
return x_prob
The associated functions for the pipeline (e.g., splitting dataset, fitting model, predicting data and evaluating model) are defined in nodes.py.
def split_dataset(df: pd.DataFrame, test_size: float) -> Tuple[pd.DataFrame]:
y = df.pop('target')
X = df
df_X_train, df_X_test, df_y_train, df_y_test = train_test_split(X, y, test_size=test_size)
return df_X_train, df_X_test, df_y_train, df_y_test
def fit_model(df_X: pd.DataFrame, df_y: pd.DataFrame, epochs: int, batch_size: int, dimension: int) -> Tuple[nn.Module, dict]:
model = NeuralNetwork(dimension=dimension)
optimizer = torch.optim.SGD(model.parameters(), lr=0.002)
tensor_X = torch.from_numpy(df_X.to_numpy()).float()
tensor_y = torch.from_numpy(df_y.to_numpy().squeeze())
dataloader = DataLoader(
TensorDataset(tensor_X, tensor_y),
batch_size=batch_size,
shuffle=True
)
for epoch in range(epochs):
for x, y in dataloader:
optimizer.zero_grad()
y_prob = model.forward(x)
loss = nn.NLLLoss()(torch.log(y_prob), y)
loss.backward()
optimizer.step()
hyperparams = {
'epochs': epochs,
'batch_size': batch_size,
'dimension': dimension
}
return model, hyperparams
def predict_data(model: nn.Module, df_X: pd.DataFrame, batch_size: int) -> pd.DataFrame:
model = NeuralNetwork()
tensor_X = torch.from_numpy(df_X.to_numpy()).float()
dataloader = DataLoader(
tensor_X,
batch_size=batch_size,
)
y_predict = []
for x in dataloader:
y_prob = model.forward(x)
y_predict += list(torch.argmax(y_prob, dim=1).detach().numpy())
df_y_predict = pd.DataFrame(y_predict, index=df_X.index, columns=['predict'])
return df_y_predict
def evaluate_model(df_y_test: pd.DataFrame, df_y_predict: pd.DataFrame) -> dict:
f1_score = metrics.f1_score(df_y_test, df_y_predict, average="macro")
precision_score = metrics.precision_score(df_y_test, df_y_predict, average="macro")
recall_score = metrics.recall_score(df_y_test, df_y_predict, average="macro")
scores = {
"f1_score": f1_score,
"precision_score": precision_score,
"recall_score": recall_score,
}
return scores
Our pipeline.py becomes:
from kedro.pipeline import Pipeline, pipeline, node
from .nodes import get_dataset, split_dataset, fit_model, predict_data, evaluate_model
def create_pipeline(**kwargs) -> Pipeline:
pipeline_example = [node(
func=get_dataset,
inputs=None,
outputs="raw_data"),
node(
func=split_dataset,
inputs=["raw_data", "params:test_size"],
outputs=["X_train", "X_test", "y_train", "y_test"]
),
node(
func=fit_model,
inputs=["X_train", "y_train", "params:epochs", "params:batch_size", "params:dimension"],
outputs=["model", "hyperparams"]
),
node(
func=predict_data,
inputs=["model", "X_test", "params:batch_size"],
outputs="y_predict"
),
node(
func=evaluate_model,
inputs=["y_test", "y_predict"],
outputs="scores"
)]
return pipeline(pipeline_example)
The nodes split_dataset, predict_data, and evaluate_model yield the following dataframes: X_train, X_test, y_train, y_test, y_predict, and scores. These are specified in conf/base/catalog.yml with a structure analogous to that of raw_data. Additionally, parameters such as test_size, epochs, batch_size, and dimension (the dimension of the hidden layer) are stored in conf/base/parameters.yml.
test_size: 0.2
epochs: 5
batch_size: 10
dimension: 32
The fit_model function produces the trained model, represented as a PyTorch module, which is not a standard component in the Kedro data catalog. Consequently, an AbstractDataset must be defined in this case. Within the src/project_name/pipelines/pipeline_name/ directory, we create a subfolder named extras. Inside this subfolder, a Python file, for instance, torch_model.py, is added. It's essential to include an empty file named __init__.py to enable Kedro's access to torch_model.py. Below is an example of an AbstractDataSet with three crucial functions: _exists, _save, and _load. For the latter two functions, we follow the PyTorch tutorial on saving and loading models under pickle format. While the kedro-mlflow plugin for Kedro can be used to store trained models, this work opts not to employ any additional plugins.
from os.path import isfile
from typing import Any, Dict
import torch
from kedro.io import AbstractDataset
class TorchModel(AbstractDataset):
def _describe(self) -> Dict[str, Any]:
return dict(filepath=self._filepath)
def __init__(
self,
filepath: str,
) -> None:
self._filepath = filepath
def _exists(self) -> bool:
return isfile(self._filepath)
def _save(self, model) -> None:
torch.save(model, self._filepath)
def _load(self):
model = torch.load(self._filepath)
return model
The corresponding catalog entry in conf/base/catalog.yml is:
model:
type: project_name.pipelines.pipeline_name.extras.torch_model.TorchModel
filepath: data/06_models/NeuralNetwork.pickle
Tracking hyperparameters and scores is achieved by storing them as JSON files with tracking dataset type. This is for our benchmark.
hyperparams:
type: tracking.JSONDataset
filepath: data/08_reporting/hyperparams.json
scores:
type: tracking.MetricsDataset
filepath: data/08_reporting/scores.json
Now, simply enter kedro run in our terminal, and Kedro will execute all discovered pipelines. For larger projects, it is advisable to create distinct pipelines for each task, such as pre-processing data, fitting models, evaluating models, reporting benchmarks, etc. However, in this example, we have chosen to create a single pipeline with all these tasks.
Tracking with Kedro-viz
To activate tracking with Kedro-viz, the following lines of code must be added to setting.py:
from kedro_viz.integrations.kedro.sqlite_store import SQLiteStore
from pathlib import Path
SESSION_STORE_CLASS = SQLiteStore
SESSION_STORE_ARGS = {"path": str(Path(__file__).parents[2] / "data")}
Subsequently, executing kedro viz run in the terminal initializes Kedro-viz. The pipeline is visually represented as a tree structure in Figure 1. This visualization proves beneficial when dealing with large and intricate pipelines, aiding in easily verifying the logic of the pipeline and serving as a valuable tool for explanations.
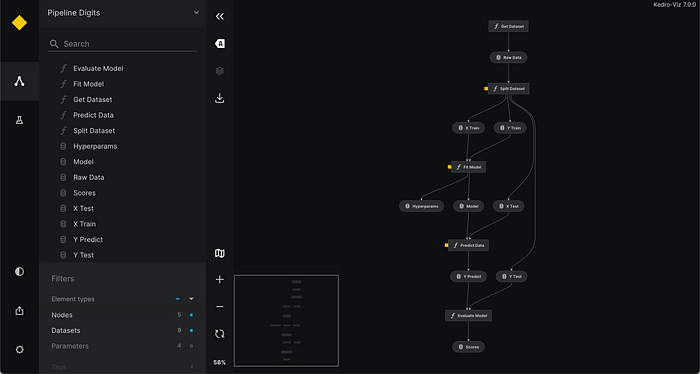
Kedro also offers the ability to display generated dataframes within the pipeline by incorporating specific properties into the data catalog. When dealing with substantial dataframes, it is essential to adjust the number of rows displayed in the preview tab (learn more).
raw_data:
type: pandas.CSVDataset
filepath: data/01_raw/raw_data.csv
metadata:
kedro-viz:
layer: raw
preview_args:
nrows: 5
For experiment tracking, accessing the “chemistry bottle” icon reveals all experiment runs. The “Compare runs (max. 3)” option, situated at the top left of the screen, facilitates quick comparisons between 2 or 3 runs. Additionally, simple metric charts are visible in the “Metrics” tab. In Figure 2, we can see how performance scores of the model change if its dimension changes (from 16 to 32).
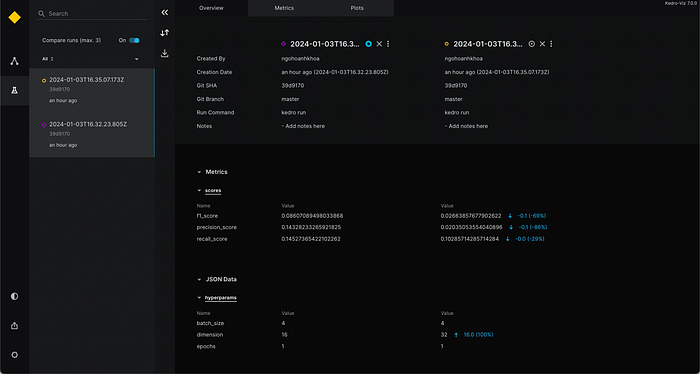
It is noteworthy that hyperparams and scores are stored as JSON files (refer to Figure 3). These files can be directly accessed to create more intricate charts for benchmarking. Each run is uniquely identified by a specific name, denoting the date and time of the run.

Conclusion
Kedro offers a robust solution for managing and reproducing experiments in machine learning. The integrated kedro-viz plugin provides visualizations of data pipelines, aiding in the tracking of experiment runs and facilitating comparisons between them. The three-step process outlined in this article demonstrates how to quickly set up a benchmark for deep learning models using Kedro. Experiment tracking with Kedro-viz further enhances the visibility and understanding of the entire pipeline. The code of this project is found in this repo of github.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")