



How to Make a Model with Textual Input Benefit From User’s Age
Last Updated on July 21, 2023 by Editorial Team
Author(s): Sebastian Poliak
Originally published on Towards AI.
Deep Learning
How to Make a Model with Textual Input Benefit From User’s Age
Enriching Sequential LSTM Model with Non-Sequential Features
Sequence data can be found in various fields and use cases of Machine Learning, such as Time Series Forecasting, Bioinformatics, Speech Recognition, or Natural Language Processing. With the trend of Deep Learning, the sequences are usually modeled using variants of Recurrent Neural Networks, which take the input sequentially at each time step.
However, sometimes we might have available additional features that are non-sequential but still related to the task we are trying to solve. These could be for example the geolocation of a company whose stock we are trying to predict, a gender of the speaker whose voice we are trying to recognize, or the age of a person that is writing the product review.
These features will probably not make or break your model, but can often help to gain a bit of performance on top. In this article, I will show you how to combine these non-sequential features with LSTM and train a single end-to-end model.
Dataset
Since my background is mostly in Natural Language Processing, I decided to demonstrate the principle with a related use case. For this purpose, I chose the dataset called Women’s E-Commerce Clothing Reviews.
The dataset contains customer reviews written in free text, which correspond to our sequence data (sequences of tokens — words). Additionally, it contains features such as customer’s age, product ID, product department, product rating by the customer, and whether the customer would recommend the product to others. In our experiment, the product recommendation to others will not actually be used as a feature, but as the target value we will try to predict.
Baseline
Let’s first create a sequence model that takes solely the text of the review on the input, and can serve us as a baseline.
The model that has been used here is relatively simple. The text of the reviews is firstly represented with word embeddings using Glove: Global Vectors for Word Representation. After that, the model consists of a single bidirectional LSTM layer, followed by a fully-connected layer. The output layer uses a sigmoid function, since our output is just 0 or 1, corresponding to whether the customer would recommend the product or not.
In Keras, the model could look something like this:
The described model has been trained and evaluated on the mentioned dataset (split in 90:10 ratio). This resulted in an accuracy of 89%.
Adding non-sequential features
Let’s now add the non-sequential features to the same model that we have just defined. There are several approaches that I have seen this to be done.
One of them is to add the features as special tokens in the beginnings of the sequences. This way, the first N tokens of any sequence would always correspond to these features. I do not find this solution particularly clean, mostly because the features need to be somehow encoded and pretend to be the word embeddings (or other sequence representations). This can be a bit problematic and exhausting, mainly if the features are of different data types.
The solution that I prefer and find much cleaner is to build the model with 2 separate inputs. This way, the first input can be used purely for the sequential features, and the second for the non-sequential ones. The sequential input is normally passed through the embedding and LSTM layer, after which it is concatenated with the non-sequential input. The resulting combined vector is then passed through a fully-connected layer and finally the output layer. This architecture is demonstrated in the following picture.
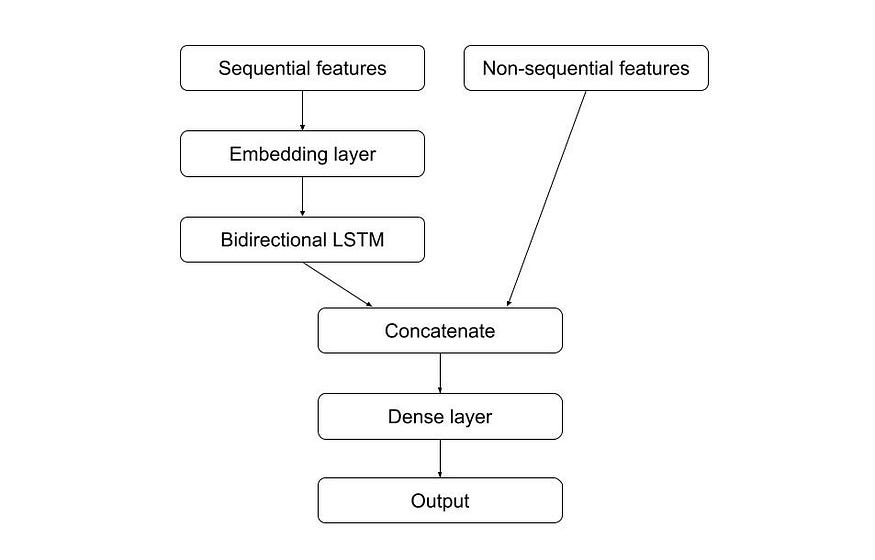
The corresponding code in Keras looks like this:
The non-sequential features that I used for this model were customer’s age and the provided product rating. I found out that the customer’s age is only slightly correlated with whether the customer would recommend the product (0.0342), and therefore, I decided to also use the product rating, which is obviously strongly correlated (0.7928). This was done in order to demonstrate the effect of adding the non-sequential features, however, in reality we wouldn’t probably have such a strong a feature.
To train the model, you provide the separate inputs as following:
The resulting model reached an accuracy of 94%, which in our case is 5% increase compared to the baseline. Of course, the improvement is totally dependent on the quality of features that are provided to the model, but generally, any non-sequential feature that is at least a little bit correlated with your target value should help.
Conclusion
In this article, we have demonstrated how 2 different types of input can be combined into a single end-to-end model. In practice, we do not need to restrict ourselves to any given number of inputs, but add as many as we would like. You can imagine another input being for example an image, which is passed through a few convolutional layers, before being concatenated with the rest of the inputs.
I hope that this approach will help you in your future projects.
All the code that I used is available in this kaggle notebook.
Thank you for reading!
1 to 5 Star Ratings — Classification or Regression?
Finding out with an experiment.
towardsdatascience.com
Systematically Tuning Your Model by Looking at Bias and Variance
Ever wondered if there is a more systematic way of tuning your model, than blindly guessing the hyperparameters or…
towardsdatascience.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

