


 For Time Series?")
How to Design a Pre-training Model (TSFormer) For Time Series?
Last Updated on January 6, 2023 by Editorial Team
Last Updated on July 8, 2022 by Editorial Team
Author(s): Reza Yazdanfar
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
There have been numerous attempts in NLP (Natural Language Processing) tasks recently, and most of them take advantage of using pre-trained models. NLP tasks’ feed is mostly the data created by human beings, full of fertile and excellent information that almost can be considered a data unit. In time-series forecasting, we can feel a lack of such pre-trained models. Why can’t we use this advantage in time series as we do in NLP?! This article is a detailed illustration of proposing such a model. This model is developed by considering two viewpoints and has 4 sections from input to output. Also, the Python code is added for a better understanding.
TSFormer
- It is an unsupervised pre-training model for Time Series based on TransFormer blocks (TSFormer) with the well-implemented Mask AutoEncoder (MAE) strategy.
- This model is able to capture very long dependencies in our data.
NLP and Time Series:
To some extent, NLP information and Time Series data are the same. They both are sequential data and locally sensitive, which means to be in relation to its next/previous data points. BTW, there are some differences which I’m going to say in the following:
There are two facts (in fact, these are differences) we should consider while proposing our pre-trained model as we have done for NLP tasks:
- The density is much lower in Time Series data than in Natural Language
- We need a longer sequence length of Time Series data than NLP data
TSFormer From ZERO
Its process, like all other models, is just like a journey (Nothing new, but a good perspective). As I told you about the strategy of MAE, the main architecture is going through an encoder and then processed into a decoder, finally just to reconstruct the target.
You can see its architecture in Figure 1:
That’s it mate!! There is nothing more than this Figure. 😆 However; if you want to know how it operates, I’ll illustrate this in the following section:
The process: 1. Masking 2. Encoding 3. Decoding 4. Reconstructing Target
1. Masking

This is the first step to providing feed to the next step (Encoder). We can see that the input sequence (Sᶦ) has been distributed into P patches with the length L. Consequently, the length of the sliding window which is used to forecast the next time step is P x L.
The making ratio (r) is 75% (relatively high, isn’t it?); it is just about making a self-supervised task and makes the Encoder more productive.
The main reasons for doing this (I mean patching input sequence) are:
- Segments (i.e. patches) are better than separate points.
- It makes it simpler to utilize downstream models (STGNN takes a unit segment as input)
- By this, we can decrease the size of input for the Encoder.
2. Encoding
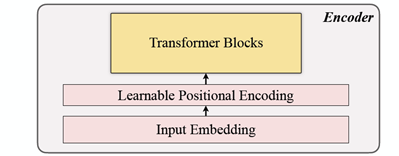
As you can see, it is an order of Input Embedding, Positional Encoding, and Transformer Blocks. The Encoder can perform just on unmasked patches. Wait!! What was that??
Input Embedding

Q) The previous step was about masking and now I said we need unmasked ones??!!
A) Input Embedding.
Q) How?
A) It is actually a linear projection that converts the unmasked to latent space. Its formula can be seen below:
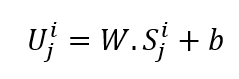
W and b are learnable parameters and U are the model input vectors in d hidden dimension.
Positional Encoding

Simple Positional Encoding layers are used to append new sequential information. The term “Learnable” is added, which helped to show better performance than sinusoidal. Also, learnable positional embedding shows good results for time series.
Transformer Blocks

The researchers used 4 layers of transformers, just lower than the common amount in computer vision and NLP tasks. The illustration of the type of transformer used here is the most used transformer architecture. You can read it thoroughly in “Attention is all you Need” published in 2017. BTW, I’m going to give you a summary of it(This short illustration comes from one of my previous articles, ‘Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting’):
Transformers are new deep learning models which are presented at a rising rate. They adopted the mechanism of self-attention and showed a significant increase in model performance on challenging tasks in NLP and Computer Vision. The Transformer architecture can be envisaged into two parts known as encoder and decoder, as it is illustrated in Figure 4, below:
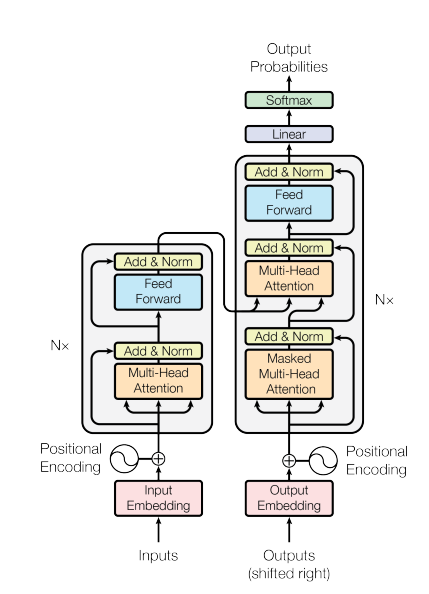
The main point of transformers is their independence from localities. In contrast to other popular models like CNNs, transformers are not limited by localization. Also, we do not propose any CNN architecture in transformers; instead, we use Attention-based structures in transformers, which allows us to accomplish better results.
Attention Architecture can be summarized in Figure 5:
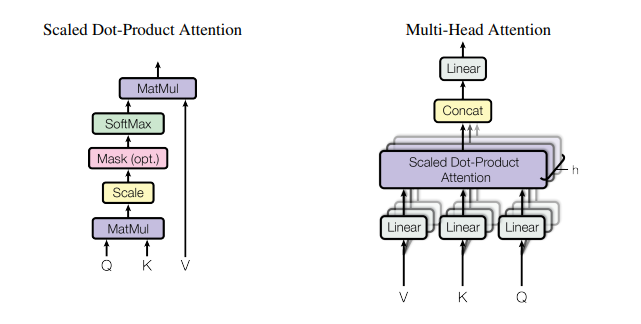
The function of Scaled Dot-Product Attention is Eq. 2
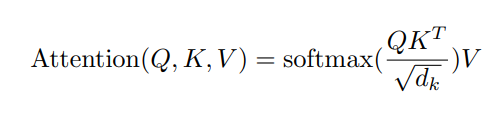
Q (Query), K (Key), and V(Vector) are the inputs of our attention.
For a complete fundamental realization of transformers, look at “Attention is all you need.” It gives you a great understanding of attention and transformers; in fact, for the first time, I completely understood this important model through this paper.
I think this amount of summary is enough for transformers
3. Decoding
The decoder includes a series of Transformer Blocks. It works with all sets of patches (masked tokens, etc.). In contrast, MAEs (Masked AutoEncoders), there are no positional embeddings due to patches has already positional information. The number of layers is just one. After that, simple MLPs (Multi-Layer Perceptions) were used (I’d like to be sure that there is no need to illustrate MLPs😉), which makes the output length equal to each patch.
4. Reconstructing Target

Parallelly, the computation over masked patches is for every data point (i). Also, mae (Mean-Absolute-Error) is chosen as the loss function of the main sequence and reconstruction sequence.

That’s it!! You did it! Not too hard, is it??!😉😉
Now, let’s have a look at the architecture:
The End
The source of the code and architecture is this and this, respectively.
You can contact me on Twitter here or LinkedIn here. Finally, if you have found this article interesting and useful, you can follow me on medium to reach more articles from me.
How to Design a Pre-training Model (TSFormer) For Time Series? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





