



How to Build a Simple Generative AI Application with Gradio
Last Updated on February 2, 2024 by Editorial Team
Author(s): Saqib Jan
Originally published on Towards AI.
Gradio is simply a great choice for creating a customizable user interface for machine learning models to test your proof of concept.
When you have a specific idea in mind, say summarizing an article, a small specialist model that is designed for that specific task can perform just as well as a general-purpose Large Language model. And interestingly, a smaller specialist model can also be cheaper and faster to run.
You can, if you want, create an application that aggregates news articles from various sources and provides summarized versions of the articles for quick browsing. Or, you could develop a plugin that integrates with email services and automatically summarizes long emails, allowing users to quickly grasp the main points without reading the entire message.
But how would you do that? I’ll show it in this brisk tutorial so that you can also give it a try. And the best part? It will not take hours but minutes.
Import libraries
import gradio as gr
from transformers import pipeline
Gradio is an open-source Python library, and you can accomplish a lot with it in minutes, like allowing users to input data, make predictions, and visualize results with just a few lines of code.
And we’re also importing the pipeline function from the Hugging Face Transformers library, which is very good for working with pre-trained transformer models in NLP.
Initialize a Summarization Pipeline
get_completion = pipeline("summarization", model="sshleifer/distilbart-cnn-12-6")
First off, we’re going to use sshleifer/distilbart-cnn-12–6 model for text summarization because it is one of the state-of-the-art models known for its exceptional performance and accuracy in generating concise summaries. Another factor is if we use the Transformers Pipeline function for text summarization without specifying the model explicitly, it will still default to Distilbart CNN 12–6.
Most interestingly, the effective way to improve cost and speed is to create a smaller version of the model that has a very similar performance. This process, called distillation, is quite common. Distillation involves using the predictions of a large model to train a smaller one. The model we’re using (Distilbart CNN 12–6) is actually a distilled version of the larger model trained by Facebook, known as the BART Large CNN model.
And since this model is built specifically for summarization, let’s write some functions for any text that you feed into the model so that it will output a summary of it.
Create a Summarization Function
def summarize(input_text):
# Generate the summary for the input text
output = get_completion(input_text)
# Extract and return the summary text
return output[0]['summary_text']
Now, we define a function summarize that takes input text as a parameter, generates a summary using the initialized summarization pipeline, and returns the summary text. This function simplifies usage and maintenance within the application.
Create Gradio Interface
gr.close_all()
demo = gr.Interface(
fn=summarize,
inputs=[gr.Textbox(label="Text to summarize", lines=6)],
outputs=[gr.Textbox(label="Result", lines=3)],
title="Text Summarization with DistilBART-CNN",
description="Summarize text using the `sshleifer/distilbart-cnn-12-6` model!"
)
Here, we set up the Gradio interface with input and output components, specify the summarization function, and provide a title and description to inform users about the interface’s functionality.
Now, let’s launch the interface so we can input text and receive summarized output using the DistilBART-CNN model.
demo.launch(share=True)
It will launch an interface like this.
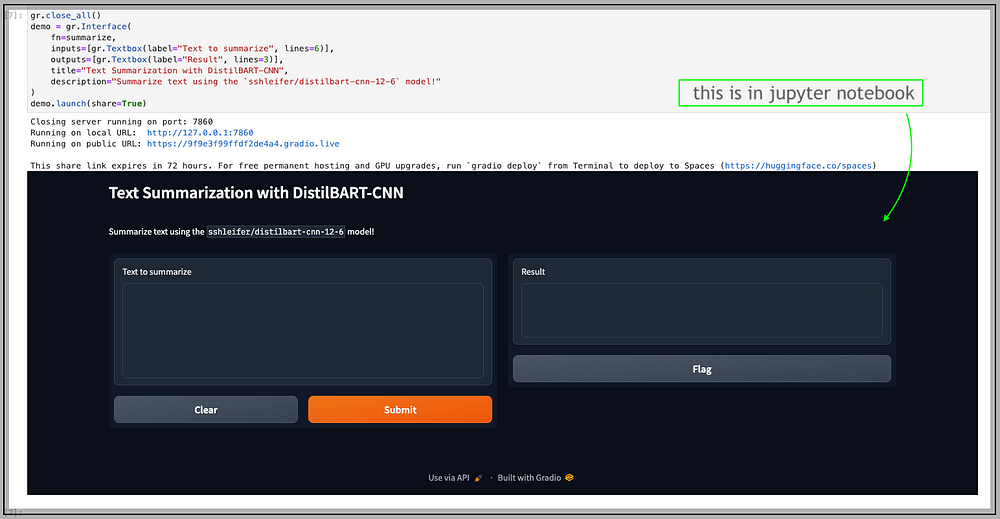
Now that our application is up and running, the Gradio interface is accessible both locally and via the live link provisioned by Gradio. And we are now ready to test.
Unfortunately, there was a tragic train accident in Odisha, a state in India, last year. And if we summarize the text of this BBC article about it, we can see the output it gives.
The model throws an error if your text exceeds 800 words. It's best to keep it between 700-800 words.

This works perfectly fine. You can do a lot of things if you have some experience in Python and use Gradio to build interfaces for your AI applications. Try this!
If you want to summarize books and papers, this advanced-level tutorial by Raghavan Muthuregunathan about How to Summarize and Find Similar ArXiv Articles on Lablab.ai is a very helpful resource on the internet.
Credits
I’d be remiss not to give credit for this oversimplified tutorial to Apolinário Passos (Poli), a Machine Learning Art Engineer at Hugging Face. His free short course on Deeplearning.ai with Andrew NG is an exhilarating resource for learning how to build AI-powered applications.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")