



How Regularization Helps in Data Overfitting
Last Updated on July 25, 2023 by Editorial Team
Author(s): Saikat Biswas
Originally published on Towards AI.
Surely helps in reducing the pain of lookout for a perfect model
“Knowledge is the treasure and practice is the key to it”
Let me start this article with a simple fact. For regression most of the time, we start to build a model by trying to fit a curve.
And as we progress towards that for our data, we might encounter a problem and that problem might lead to overfitting the data, which will give us a wrong impression and false implication of our data.
Well…. How ??
We will see how in a bit, but first, let’s understand why it happens? We will start with some definitions first.
Overfitting happens when our model is too complicated to generalise for new data. When our model fits the data perfectly, it is unlikely to fit new data well.
Underfit happens when our model is not complicated enough. This introduces a bias in the model, such that there is systematic deviation from the true underlying estimator.
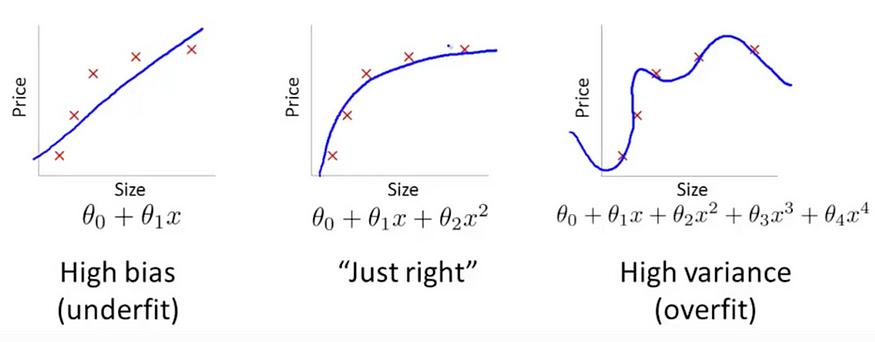
Alright..!! Now, let’s understand more about this in detail. How does it affect our model performance? We will understand more about this using a simple yet most widely seen graph.

The first case here is called underfit, the second being an optimum fit and last being an over-fit.
We can see from the first graph that the fitted line has not been able to distinguish the classes properly which has led to underfitting, meaning the fitted curve has not been able to explain the variance of the data properly.
The last one has fitted the data too good, which should be ideal for our case. But there is a problem for this force-fitting curve. This might have been able to explain the underlying variance of our model, but when we use this for unseen data this would fall flat on its face. In short, it would not be able to distinguish between classes on unseen data thus giving us false predictions.
We consider the 2nd graph as the chosen one, even though it has not been able to predict all the classes properly because this one would not fall flat when it needs to classify the classes properly on unseen test data.
Now all of this comes down to the term we often hear in the Machine Learning world which is Bias vs Variance Tradeoff.
To build a good model, we need to find a good balance between bias and variance such that it minimizes the total error.
The How…?
Let’s see a bit of that in its mathematical form.
The equation of least squares can be expressed as :

where y is the dependent variable and y hat is the predicted one by our model. w represents the weights in our gradient. Now, the least square method would give us a model that is the difference in the expected and predicted variance of our population mean. If the difference is high, it leads to high variance in our model and our aim is to reduce that. The need to choose a model that satisfies both the Bias vs Variance problem comes into play here.
To reduce the impact of this tradeoff we use the concept of Regularization.
Regularization attempts to reduce the variance of the estimator by simplifying it, something that will increase the bias, in such a way that the expected error decreases.
According to Wikipedia, Regularization “refers to a process of introducing additional information in order to solve an ill-posed problem or to prevent overfitting”.
We know, The General Equation of a Linear Regression can be expressed as follows:-
Y ≈ β0 + β1X1 + β2X2 + …+ βpXp
where β is the coefficients of the independent variables X. Now, our goal is to reduce the error in coefficients. This is done by using the Residual Sum of Squares(RSS). Equation of RSS can be defined as:-

This should help in adjusting the residuals of the data. If there is noise it won’t generalize well on the data. This is where Regularization comes into practice and we try to minimize the error by introducing a shrinkage factor.
Ridge Regression(L2 Norm):
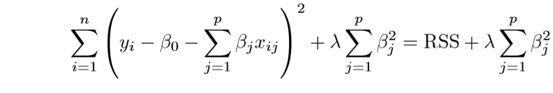
This factor is a λ which is a tuning parameter that is used to penalize the flexibility of our model and finding the optimum parameters. Now if λ is zero, it will not affect the outcome and we will get the same result. However, if λ is towards infinity we will get results that are not at all suitable for our needs.
So, selecting a good value of λ is critical to our need for finding the correct coefficients. This is where Cross Validation comes in handy too that helps in estimating the error over test set, and in deciding what parameters work best for the model. The Coefficient estimates produced using this method is also known as the L2 norm.
Lasso Regression(L1 Norm):
Let’s see another type of Regression that helps in reducing the variance.
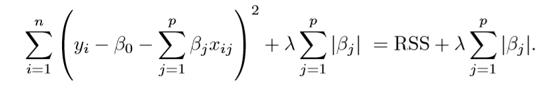
Lasso does its job of penalizing only the high coefficients. It uses U+007CβjU+007C(modulus)instead of squares of β, as its penalty. In statistics, this is known as the L1 norm.

The blue shape refers to the regularization term and the elliptical surface refers to our least square error (or data term).
The ridge regression can be thought of as solving an equation, where the summation of squares of coefficients is less than or equal to s. And the Lasso can be thought of as an equation where the summation of modulus of coefficients is less than or equal to s.
Here s is the constant that exists for each value of shrinkage factor λ.
So, if we consider there are 2 parameters and if we look at the broader picture, we can see that ridge regression can be expressed by β¹² + β²² ≤ s.
And for Lasso, we consider the modulus, so the equation becomes,
U+007Cβ1U+007C+U+007Cβ2U+007C≤ s.
Now there is a problem with Ridge which is model interpretability. It will shrink the coefficients for least important predictors, very close to zero. But it will never make them exactly zero. In other words, the final model will include all predictors. However, in the case of the lasso, the L1 penalty has the effect of forcing some of the coefficient estimates to be exactly equal to zero when the tuning parameter λ is sufficiently large. Therefore, the lasso method also performs variable selection and is said to yield sparse models.
What does Regularization achieve?
A standard least-squares model tends to have some variance in it. Regularization, significantly reduces the variance of the model, without a substantial increase in its bias.
So, it all comes down to the tuning parameter λ, which controls the impact of bias and variance. As the value of λ increases, it reduces the coefficients thus reducing the variance. The increase in λ is beneficial only till a certain point because after a point if we keep increasing its value, the model will start to lose important properties, thus adding bias in the model leading to underfitting.
Typical Use Cases
- Ridge: It is majorly used to prevent overfitting. Since it includes all the features, it is not very useful in case of exorbitantly high #features, say in millions, as it will pose computational challenges.
- Lasso: Since it provides sparse solutions, it is generally the model of choice (or some variant of this concept) for modeling cases where the #features are in millions or more. In such a case, getting a sparse solution is of great computational advantage as the features with zero coefficients can simply be ignored.

Elastic Net
The combination of both L1 and L2 norm gives us a better implementation of regularization.
βˆ = arg minβ y − X β 2 + λ 2 U+007Cβ 2U+007C + λ 1U+007C β 1U+007C
So how do we adjust the λs in order to control the L1 and L2 penalty term? Let us understand by example.
Suppose, we are trying to catch a fish from a pond. And we only have a net, then what would we do? Will we randomly throw our net? No, we will actually wait until you see one fish swimming around, then we would throw the net in that direction to basically collect the entire group of fishes. Therefore even if they are correlated, we still want to look at their entire group.
Elastic regression works in a similar way. Let’ say, we have a bunch of correlated independent variables in a dataset, then the elastic net will simply form a group consisting of these correlated variables. Now if anyone of the variables of this group is a strong predictor (meaning having a strong relationship with the dependent variable), then we will include the entire group in the model building, because omitting other variables (like what we did in lasso) might result in losing some information in terms of interpretation ability, leading to a poor model performance.
Conclusion

As we can see Lasso helps us in bias-variance tradeoff along with helping us in important feature selection. Whereas, Ridge can only shrink coefficients close to zero.
For Further Reading:-
Regularization in Machine Learning
One of the major aspects of training your machine learning model is avoiding overfitting. The model will have a low…
towardsdatascience.com
A comprehensive beginners guide for Linear, Ridge and Lasso Regression
Introduction I was talking to one of my friends who happens to be an operations manager at one of the Supermarket…
www.analyticsvidhya.com
That’s all for now. Until next time…!! Cheers ..!!!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

