



How Google made “Hum to Search”?
Last Updated on May 7, 2021 by Editorial Team
Author(s): Daksh Trehan
Technology
A perfect tool to drive earworms away.
You know me guys, I love to decode interesting algorithms, first, it was TikTok, then Tinder next was GPT-3 and now Google Hum!
Table of Content:
- How to use Google Hum feature?
- How is Google using ML in the “Hum” feature?
Were you ever in the exam hall/conference room and all you could think of was the weird music sound that was playing in the disco last night?
Don’t worry, we’ve all been there. This phenomenon is known as an earworm. And, to drive the earworm away and ease your mind, the only trick is to sing/listen to that tune.
But, you don’t know that song and only a “hum” voice is revolving inside your head? Don’t worry, Google is here.
Google Hum is an advancement of usual music recognition systems.
Shazam, Pixel Sound Search is all fine, but they can only recognize the exact tune with the presence of pitch, tempo, and instruments. But Google took it to another level and introduced “Hum” that can even recognize song name if you “hum” at Google for 15 seconds with hum tone matching that with any particular song.
Funny and amazing, how everything bizarre that we can imagine is now possible with the use of AI and even when humans with the same taste as yours, can’t understand you but freaking AI can!
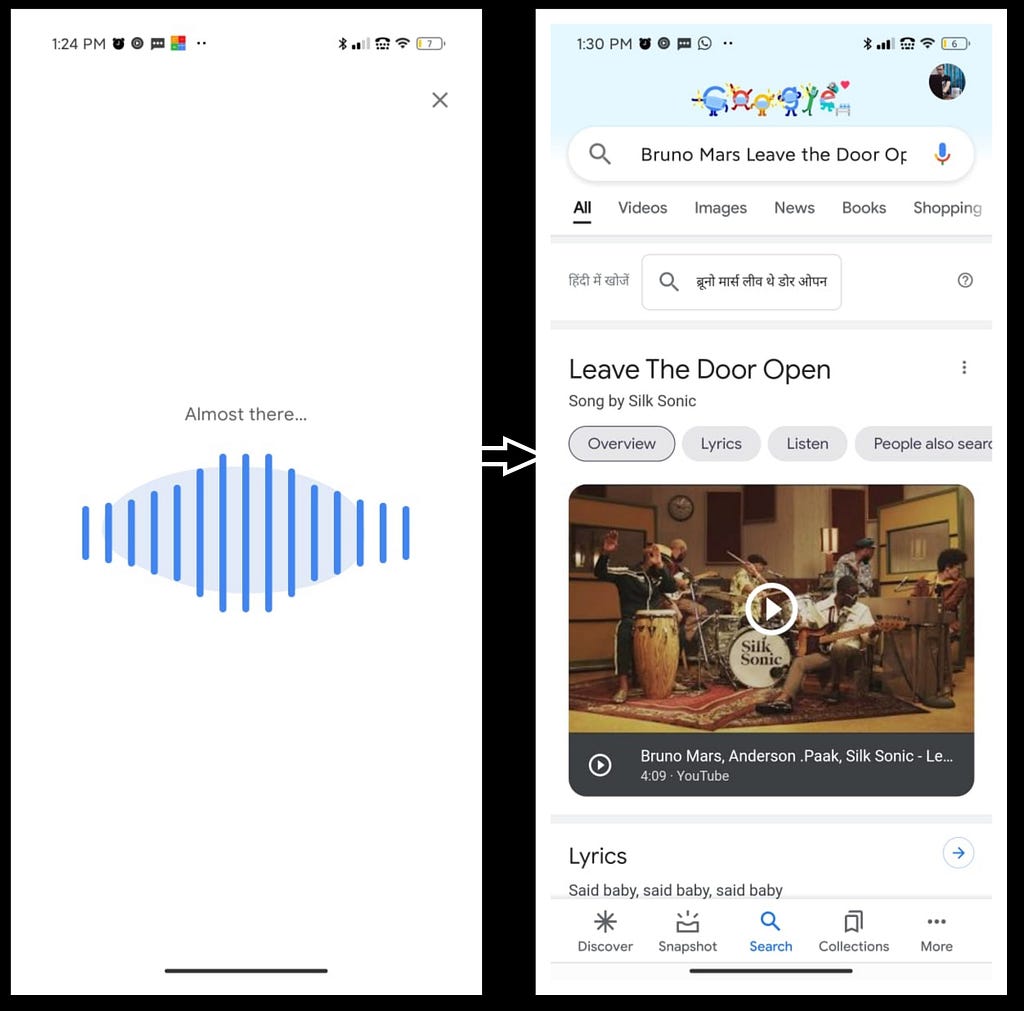
How to use Google Hum feature?
It is easy, go to your google search, tap on the “mic” and “hum” the tune/song.

How is Google using ML in the “Hum” feature?
In a typical musical recognition system, to process audio, the sample is converted to a spectrogram to find an exact audio match. But this can’t be done in the case of hummed voice, because the hummed voice doesn’t include any sort of extra additions like tempo, pitch, loudness, etc. All it has is a random tune, that our model has to match to the closest song.
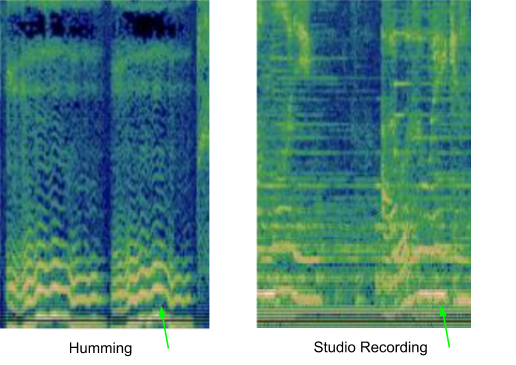
To achieve the above-mentioned technique, our model needs to be very robust and must ignore everything exact for the voice note. To make it work, we need to make changes in already defined Sound Recognition models.

The humming sound is transformed into a number-based sequence for easy computation. The modified neural network is then trained with a pair of hummed and studio-recorded audio that produces embeddings for each input pair thus creating a fingerprint-like unique identity. The model must be potent enough to distinguish two different songs with the same melody but different music and instrumentation.
The trained model generates an embedding for each input hum and looks for song/tune with similar embedding in its training corpus.
Training Data
The training data requires both recorded and sung versions of each song. The pitch is extracted from the songs using SPICE thus generating the melody consisting of discrete audio tone.
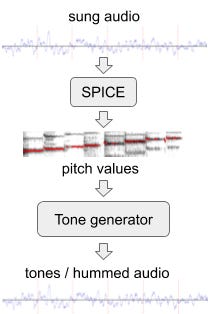
The model is further made sturdy by experimenting with pitch, loudness, bass, the energy of studio recording. Also, mixing and matching two different audios of the same singer helps to achieve higher accuracies.
I just hope Google has trained with all real poor hummed versions of songs and tried themselves personally.
Triplet Loss
The training is incorporated with Triplet Loss which tries to ignore few training points thus avoiding various Neural Networks drawbacks. When we pass pair of audio and corresponding melody to our model, triplet loss tends to ignore those values of training data that are derived from an unusual melody i.e. it leaves behind the accompanying instrument audios and generates a number-based sequence for each melody.
Conclusion
In this article, we tried to shed a light on working of Google Hum and how Machine Learning is becoming the core of new virtual world.
References:
[1] Google AI Blog: The Machine Learning Behind Hum to Search
[2] Google explains how Hum to Search works
[3] Hum to Search: The ML Behind Google’s New Feature
[4] Google can now guess the song you hum! | by Nikita Gawde | Medium
Feel free to connect:
Portfolio ~ https://www.dakshtrehan.com
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
Medium ~ https://medium.com/@dakshtrehan
Want to learn more?
Are You Ready to Worship AI Gods?
Detecting COVID-19 Using Deep Learning
The Inescapable AI Algorithm: TikTok
GPT-3 Explained to a 5-year old.
Tinder+AI: A perfect Matchmaking?
An insider’s guide to Cartoonization using Machine Learning
Reinforcing the Science Behind Reinforcement Learning
Decoding science behind Generative Adversarial Networks
Understanding LSTM’s and GRU’s
Recurrent Neural Network for Dummies
Convolution Neural Network for Dummies
Cheers
How Google made “Hum to Search”? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

