



How Go Helped Me Accelerate My Machine Learning Computations
Last Updated on January 6, 2023 by Editorial Team
Author(s): Kourosh T. Baghaei
Machine Learning
TL;DR: (T)oo (L)ong that you (D)on’t wanna (R)ead?
Fine, I got your back: Here, I share my story of using Go language to reduce the time of machine learning computations of my project from one week to less than 24 hours. To meet the deadline, I had to submit my results within 3 days.
Persuading enough? 😀 Then follow along!
The Background Story
As a master’s student, I had a ton of stuff to do from working on my thesis, applying for PhD positions, possible internships, and so on. On top of all these stuff, I had to have the report of my research ready for submission to the target conference. In fact, I had already got most of my results, and had my manuscript written and revised a few times with my research advisor. I wanted to add more results to support my approach.
However, just like any other graduate student, I had one major problem: TIME!
There were only 3 days left to the final deadline of the conference. And I needed at least 7 whole days to finish the computations and a half-day to populate my results. I had two options:
- Give up the target conference, and target for another one.
- Figure out a way to increase the speed of my calculations.
What was my choice? The very fact that you are reading this, speaks for itself.
The major tool that I use for developing and implementing my experiments is PyTorch. It is a very stable and easy to understand framework for harnessing the strength of NVIDIA GPUs for machine learning tasks. I had developed my own method and already had the results. However, for the baseline methods, I preferred to save time by using a stable, well-written and well-documented library. There was a problem though: The library had developed one of the methods (lets just call it too_long_method ) using only NumPy without any GPU-accelerated implementation. The too_long_method consists of a very big number of iterations in a long loop. So, for a single data point, it would take around 15 minutes to complete. In order to be able to calculate the results for all of my data, I ran the code in several instances. However, it was not an option. Even on gaming system with 8 physical cores, Such a configuration would take 7 days for completion.
Possible Solutions?
Taking all the above issues into account, I could think of several approaches to tackle this problem:
- Rewrite the code of too_long_method in PyTorch. ( NOT AN OPTION! : since developing and debugging would take much more time, and cause confusion and frustration.)
- Use of cloud services to divide the burden of the computations on numerous computers. ( NOT AN OPTION! : That would cost me a lot. Plus, figuring out how to make use of those certain cloud services would take a while.)
- Somehow run the codes in parallel using PyTorch’s built-in Multi-Processing capabilities ( NOT AN OPTION! : Although I tried this at first, I soon realized that it would not help much, for reasons I’ll explain later.)
- Run the code in multiple instances (but unlike the previous time, on mini batches of data) ( MY CHOICE!!! I found it much easier to run multiple instances of programs and have the OS handle the burden of parallelism and multi-threading on my behalf.)
My Roadmap
I chose to run my code in multiple instances. To this end, I wrote two pieces of code with two major functionalities:
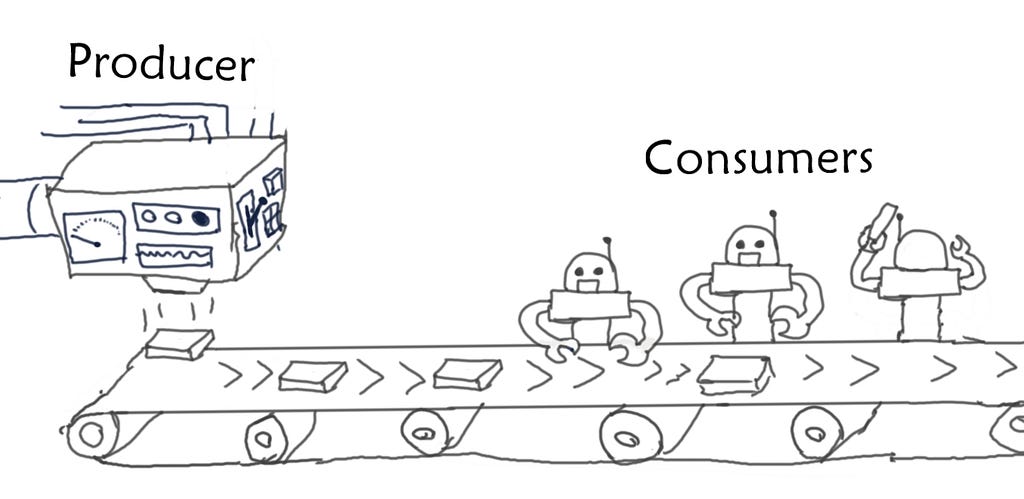
Producer: a single program that would iteratively provide data points to an external pool of instances of the code.
Consumer: the code that contains too_long_method and would process the mini-batch of data points provided to it, and store the results.
The general architecture of the whole system can be depicted as follows:
I tried the following scenarios and had no luck in getting things working correctly with the performance that I had been expecting:
- PyTorch’s MultiProcessing capabilities: The problem I faced while trying to solve the problem in this way, was that I had to manage the division of the data points among different processes that would take different amounts of times to complete. Plus, it seemed to me that increasing the number of sub-processes would not increase the throughput of the whole system. However, it was obvious that the system’s resources such as CPU cores and RAM were not being used as I had been expecting. (Anyways, never forget! I did not have much time to search and ask for possible solutions to that. So, I might have been wrong.)
- I tried to write the producer using python. However, I noticed that it cannot run external instances of program more than the virtual number of CPUs. I saw this a bottleneck, as CPU resources were still available, despite the fact that the code was running at its highest capacity. I looked for different configurations related to the python interpreter, though, could not think of any possible bottle-necks on the python’s side.
Playing around with the scenarios above for several hours with no results, made me exhausted. So, I decided to write the producer code in a programming language other than python. Fortunately, I had read and learned about Go Lang a few years back. And I knew about its built-in capabilities for handling concurrency. So, I decided to give it a shot.
Some programming concepts you wanna know:
Before diving into the code, let me first provide a few brief definitions of concepts that I have used, in case you are not so familiar with them. However, if you have never used Go, there are plenty of resources that can help you learn Go easily and quickly.
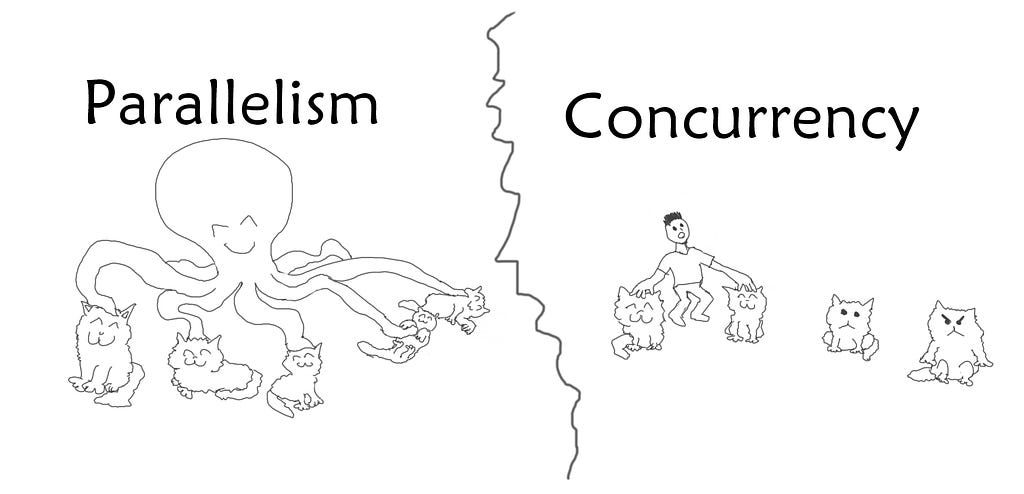
Parallelism: Running multiple tasks (in fact, mostly the same task, but on different chunks of data) at the same time on separate processing units. The main point in parallelism is that at every single moment, every single one of the processing units that are involved in the parallel process, is working on a different piece of data on its own.
Concurrency: Handling multiple tasks that do not require the same amount of time to be finished. This does not necessarily need to be distributed among different processing units. For example, when you open a website, it takes some time to download and show the website. However, while your computer is waiting for the incoming data to arrive completely, it lets you move around the mouse and do other stuff. Even if your computer has only one single processing unit. So, at a random moment that you consider during a concurrent task, you might see that the CPU is only working on one of the tasks, while the other tasks are halted due to waiting for an external factor.
They say a picture is worth a thousand words:
Here are some words and definitions from Go language:
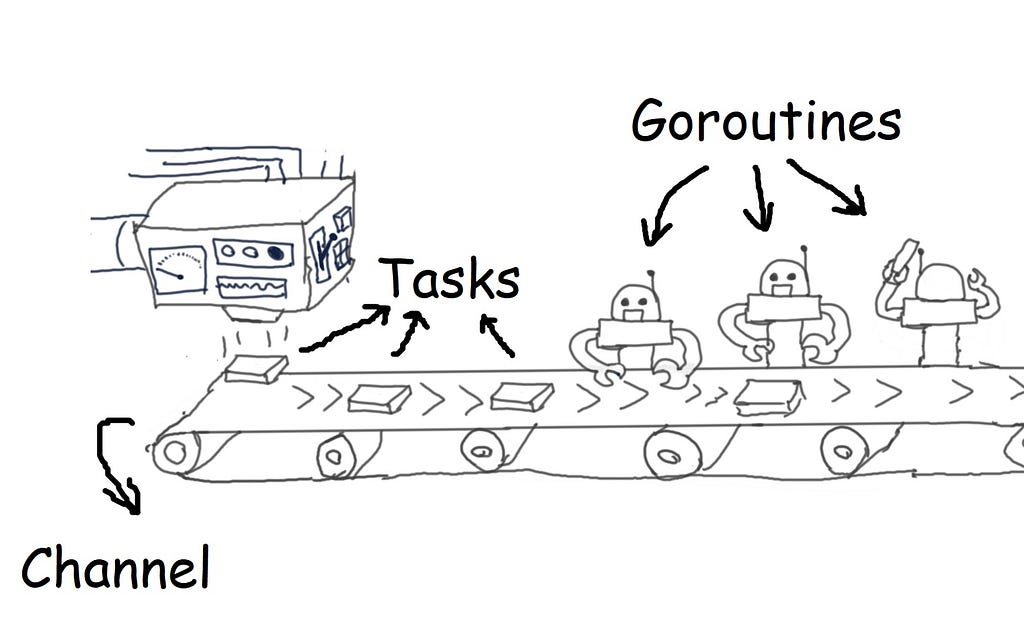
Goroutine: a built-in structure in Go, that is a light weight thread. It provides concurrency in Go programs.
Channel: can be thought of as a pipe of data, that goroutines can send data to it, also, they can receive data from it. Thus, enabling goroutines to work on pieces of data together. Channels can have lengths of arbitrary size to provide a queue of data objects of a certain type (Buffered Channel).
Task: this is not a technical term specific to any sort of language or context. Here, by using “task”, I am referring to a python code that performs a specific time-consuming machine learning method on a given piece of data.
OK, shall we see the code now?
I have published the code on my github account so that you can see it directly.
The code starts from the main() function. The general structure of the infinite for-loop in the main function is just a state design pattern for providing the user with a set of menu options. The most important part where the whole magic begins is as follows:
Lets go through its important parts line by line:
At line 3, a wait group is created that is necessary for concurrency in Go. All the magic happens from the line 8! First, a buffered channel is created for handling tasks (tasks_chan). Which can be thought of as a First In First Out (FIFO) queue that can be accessed from different goroutines. For my application, after running the code several times, I found number 32 as the optimal number of workers. i.e. the highest number of working processes that none of the processes would halt due to lack of computational resources, and the memory usage would reach its highest possible value without any Memory Exceptions from any of the subprocesses.
In the next lines, call_workers() function actually creates a pool of goroutines and passes the reference to the tasks_chan to them. So that each of them can have access to the queue of tasks. In fact, each of these goroutines runs spawn_worker() function in a separate thread:
Whenever, the code reaches to go keyword, it does not halt execution. Rather, it continues running the main thread. So, the for loop keeps running until all worker goroutines are called. A number is assigned to each of the workers. So that we can keep track of the status of each worker in the terminal. We can see this function finished execution once it prints “All workers online”.
Let’s take a look at spawn_worker function and see what happens when it is called:
The first line in this function is executed once the whole body of function is run completely. So lets forget about it for a moment. At line 4, an infinite for loop starts. Inside the for loop, there is a special select – case structure. Any of the case statements that is triggered first, its body is executed. For instance, if there are any objects available for picking up from the tasks channel, the case at line 6 triggers. And another function (spawn_pytorch) is called to perform the task (at line 9). After the task is over, the break statement at line 15 puts an end to the select statement. Thus, the infinite for-loop goes to the next iteration, and the select statement starts from the beginning.
On the other hand, after entering the select – case statement, if 10 second passes and no other case is executed, then case statement at line 17 triggers. In that case, the function returns. At this point, the first line of the function (i.e. defer wg.Done() ) notifies the group of threads (wg) of its completion.
So, in the beginning, when the call_workers, starts spawning workers in separate goroutines, all of the generated workers start waiting for 10 seconds until they stop execution completely.
Looking back at the main function, once all of the workers are ready after calling call_workers, the function generate_tasks() is called. We also need to pass tasks channel to this function. This function, starts filling the tasks buffer with tasks until the buffer is full. Once the buffer is full, it blocks execution of the main thread at line 8 (or line 15, in the end).
So, while this thread is generating tasks and sending them to the channel, the worker goroutines start reading tasks as soon as they see any tasks available in the channel. This is how Go handles all these complexities for you!
Now that the general structure of how this program works has become more clear, lets get into the more details of running the task. At line 9 of spawn_worker function, spawn_pytorch() function is called. It actually runs a batch file as an external application. The batch file contains commands for setting up the pytorch virtual environment. And then, actual execution of the python file that contains the machine learning logic (i.e. too_long_method, remmeber?). The specifications of the task, are task_index, and the batches_count. These too numbers determine which chunk of the dataset, each of instance of too_long_method should take into account for computation.
spawn_pytorch is actually defined as follows: (the explanation comes afterwards)
From lines 5 to 14, an external command object is defined and ready to run a batch file named: python_job.bat .
From lines 15 to 18, task_index and batches_count are defined as arguments of the command object.
At line 19 to 24, the command is actually run.
As if a person calls that python code with the given arguments in a PyTorch virtual environment. If any error happens along the way, the function returns false. Otherwise, it returns true.
Final Words
There is no doubt that there are plenty ways of achieving a certain goal in programming. However, this is how I confronted the problem and managed to accelerate my computations that could possibly take more than 7 consecutive days to complete, to less than 24 hours. The strength of Go language along its advantages has attracted much interest in recent years. This was also another motive to share my story. Please let me know of your opinions on this article and feel free to reach out to me if you find any problems in this article.
References:
[1] https://github.com/k-timy/go_producer_consumer
How Go Helped Me Accelerate My Machine Learning Computations was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts



")


