



How does AI Data Collection work in relation to Machine Learning Models?
Last Updated on November 12, 2021 by Editorial Team
Author(s): Mahisha Patel
How does AI Data Collection
work in relation to Machine
Learning Models?
Are you planning to introduce AI to the existing organizational schema? Or are you simply looking to prepare an intelligent and autonomous set up to cater to a particular user base? Regardless of what you aim to achieve in relation to AI implementation, it cannot be bent into shape unless you have relevant data to rely on.
Importance of AI Data Collection
Data collection as a topic is unending. But then, for the uninitiated, it can be simply understood as the process of acquiring model-specific information to train AI algorithms better, so that they can take proactive decisions with autonomy.
Quite simple, right! Well, there is more to it. Imagine your prospective AI model as a child, unaware of how subjects work. For teaching the child to make calls and complete assignments, you must make it learn the concepts first. This is what datasets in AI strive to achieve, by working as the base for the models to learn from.
Types of Datasets Relevant to AI Projects
Collating a lot of data into relevant datasets is fine but is every dataset meant to train the model. Not exactly as there are three broader dataset categories to know before scavenging for relevant insights.
- Training Datasets
AI datasets are primarily used to train algorithms and eventually the model itself. Training datasets make 60% of overall data collected in relevance to machine learning and teach models about neural networking, self-learning, and more.
2. Test Datasets
Testing data is important to see how well the model has grasped the concepts. However, as ML models have already been fed massive volumes of training data, which the algorithms are expected to recognize by the testing stage, test datasets should be completely different and out of sync with the expected results.
3. Validation Sets
Once the model has been trained and tested, you need to add validation sets to ensure that the final product comes to be perfect and in line with expectations.
What strategies to follow for AI Data Collection?
Now that you are aware of the types of datasets, it is important to devise a well-etched plan to make AI data collection a success.
- Strategy 1: Discover the Avenue
No problem is bigger than you not knowing the starting point for collecting data for your predictive models. Once the R&D team has set forth a visual prototype, it is important to plan a strategy that extends beyond data hoarding.
For starters, it is advisable to rely on open datasets, especially the ones offered by credible service providers. Plus, your focus should be on feeding only relevant data to the models and keeping complexity to a bare minimum, especially while starting out.
- Strategy 2: Articulate, Establish, and Check
Once you know where to get your data from, you must articulate the predictive aspects of the model beforehand. This is where data exploration comes to being and at this point you must assign the algorithm that might be relevant to your system. You can choose between clustering, regression, classification, and ranking algorithms.
Next, you should establish mechanisms for data collection, with the probable options being Data Lakes, Data Warehouses, and ETL. Finally, better data collection also needs you to check for the quality by ascertaining adequacy, balance or lack thereof, and technical errors, if any.
- Strategy 3: Format and Reduce
It is obvious that you would want to train, test, and validate your models by collecting data from disparate sources. Therefore, it is important to format them at the onset, just for the sake of consistency and fixing an operating range.
Next, you must reduce datasets to make them functional enough. But wait, isn’t endless data reserves advisable for developing intelligent models. Well, it is but if you are planning to work on exclusive tasks, reducing data via attribute sampling, is the way to go.
You can take data reduction further by padding it up with data cleaning, using tools like record sampling that cuts out erroneous and missing records from the database.
- Strategy 4: Feature Creation
This strategy makes sense if you are dealing in specifics like Image data collection or Speech data collection for that matter. While adding loads of clean and reduced data is important as you wouldn’t want to feed incomplete and blurred-out images to the model, you must try and ensure that certain special features are created in a bespoke way to make the models even more intuitive in time.
- Strategy 5: Rescale and Discretize
By the time you are on this point, you are expected to have collected all the relevant data that makes sense. However, you still need to rescale the same to improve the quality of collections followed by discretizing the same to make the predictions sharper and more relevant.
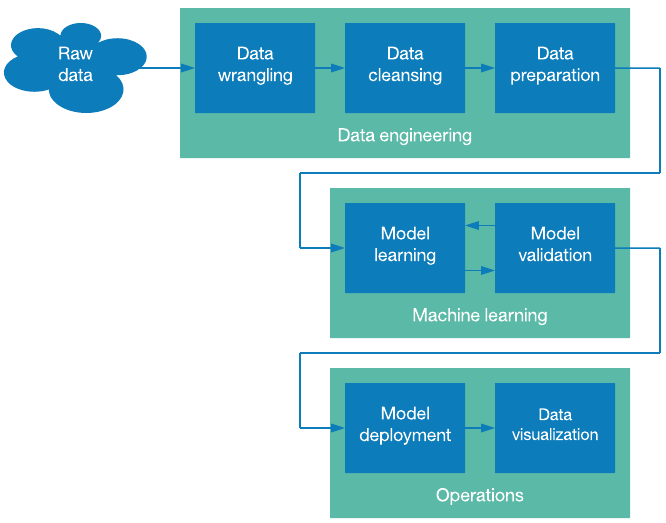
Wrap-Up
Data Collection isn’t a straightforward process. It requires a lot of experience and often a team of experienced and skilled data engineers and scientists. Be it preparing computer vision models with video and image data collection or NLP systems with speech and text data collection, companies must focus on connecting with reputed service providers to outsource data collection, right away.
References
- https://www.shaip.com/offerings/data-collection/
- https://www.iotforall.com/effective-tips-to-build-a-training-data-strategy-for-machine-learning
Thank you for reading! Have a nice day!! 🙂
Artificial Intelligence was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



