



How are AI Projects Different
Last Updated on May 17, 2022 by Editorial Team
Author(s): Jeff Holmes
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Guide to AI software development
I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and data science experience who wanted to implement MLOps. Therefore, I thought the AI software process would be a good topic for discussion in an article.
This article is intended as an outline of the key differences rather than a comprehensive discussion on the topic of the AI software process.
An AI project is experimental in nature, so several or many parts of the software program may be replaced or modified over time. Thus, changes are usually a result of outcomes of various steps in the process rather than customer/system requirements, so it is important to design the system in ways that will not require a total reconstruction if experimental results suggest a different approach.
No Free Lunch Theorem: Any two algorithms are equivalent when their performance is averaged across all possible problems.
In addition, writing scientific code has two unique properties: mathematical errors and experimental nature.
Mistakes in computations are often hard to trace, especially when the code is semantically correct. No bugs are found. No exception is raised. All looks good, but the (numerical) result is clearly incorrect. When implementing probabilistic models, the results may look good depending on some initial conditions or a random factor.
There will always be experimental parts that will be constantly changing. Therefore, the key is to design each component so that most of the work can stay and serve as a rock-solid foundation for the next stage of development.
Therefore, many articles such as [3] focus on design patterns that can help create more robust and reusable code with fewer bugs.
We can better see some of the differences with MLOps. MLOps is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently. MLOps is the intersection of Machine Learning, DevOps, and Data Engineering.
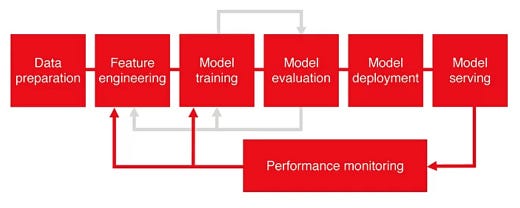
In general, the MLOps process involves eight stages:
- Data preparation
- Feature engineering
- Model design
- Model training and optimization
- Model evaluation
- Model deployment
- Model serving
- Model monitoring
Each step in the MLOps lifecycle is built on its own system but requires interconnection which are the minimum requirements needed to scale ML applications.
Without delving into a discussion of MLOps, we can identify some key ideas on the project differences:
- Need to version code, data, and models
- Continuous delivery and continuous training
- Tracking Model Experiments
- Managing Machine Learning Features
- Monitoring Model in Production
Tracking Model Experiments
Unlike the traditional software development cycle, the model development cycle paradigm is different.
Managing Machine Learning Features
Feature stores address operational challenges. They provide a consistent set of data between training and inference. They avoid any data skew or inadvertent data leakage. They offer both customized capability of writing feature transformations, both on batch and streaming data, during the feature extraction process while training. They allow request augmentation with historical data at inference, which is common in large fraud and anomaly detection deployed models or recommendation systems.
Monitoring Models in Production
There are several types of problems that Machine Learning applications can encounter over time [4]:
- Data drift: sudden changes in the features values or changes in data distribution.
- Model/concept drift: how, why, and when the performance of the model changes.
- Models fail over time: Models fail for inexplicable reasons (system failure, bad network connection, system overload, bad input or corrupted request), so detecting the root cause early or its frequency is important.
- Outliers: the need to track the results and performances of a model in case of outliers or unplanned situations.
- Data quality: ensuring the data received in production is processed in the same way as the training data.
- System performance: training pipelines failing or taking long time to run, very high latency, etc.
- Systems degrade overload: Constantly monitoring the health of model servers or service is also important.
Conclusion
Clearly, the experimental nature of AI projects is a key difference from traditional software development. We can also identify some important differences with AI projects in the context of MLOps: the need to version code, data, and models; tracking model experiments; monitoring models in production.
References
[1] E. Alpaydin, Introduction to Machine Learning, 3rd ed., MIT Press, ISBN: 978 — 0262028189, 2014.
[2] S. Russell and P. Norvig, Artificial Intelligence: A Modern Approach, 4th ed. Upper Saddle River, NJ: Prentice Hall, ISBN: 978–0–13–604259–4, 2021.
[3] How to write better scientific code in Python
[4] Considerations for Deploying Machine Learning Models in Production
How are AI Projects Different was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

